4コア8スレッドCPUを手に入れたので試してみたら不思議な結果に
インテルCore i7 2600Kという4コア8スレッドのCPUを手にいれたので、並列処理でどうなるか試してみたら、面白い結果に。
ソースは最後に載せますが、1億5千万件のint数値を複数回合計するという処理を行って、時間を計測してみました。
メモリは8GBで、VMオプションには-Xmx2048mを指定しています。
JavaVMは、JDK7ea b140です。
で、Ubuntu10.04の32bit版で実行した結果。
--- result ---1 threads:15.451201(s)2 threads:8.184938(s)4 threads:6.324816(s)6 threads:6.993831(s)8 threads:6.587393(s)
1スレッドから2スレッドにすると倍近くに、2スレッドから4スレッドでも1.3倍程度に速くなってます。ただ、6スレッド・8スレッドでは速度改善はありませんでした。条件分岐もなくただ足し算繰り返すだけでなのでHT効きづらいのかなーと思いますが。
※ 32bitなので、メモリは3.5GBくらいしか認識していませんが、メモリの余裕はありました。
まあ、これだけなら、4コアまで伸びたけどハイパースレッドきかなかったねーとなるわけですけど、OSかえたら面白い結果になりました。
Windows7 64bit版でやってみました。
--- result ---1 threads:6.930770(s)2 threads:6.020648(s)4 threads:6.175338(s)6 threads:6.133848(s)8 threads:6.160824(s)
なんだか、1スレッドのときからUbuntu 32bitでの4スレッドと同レベルの速度です。で、2スレッドで1.15倍ほど速度改善しますが、あとはむしろ悪くなります。
これが、Windows7がエラいのか、64bitにしたからなのかが気になりました。
ということで、Ubuntu 10.04 64bit版をUSBメモリに入れてみて試してみました。
--- result ---1 threads:6.862185(s)2 threads:5.982360(s)4 threads:6.061102(s)6 threads:6.126239(s)8 threads:6.152392(s)
Windows7 64bitとだいたい同じで、ちょっと速いかなーくらいの結果になっています。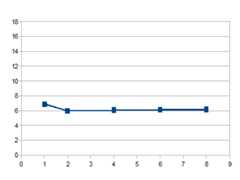
この、Ubuntu 32bitとUbuntu 64bitでの結果を統一的に説明できるような原因が、まったくわからんのですけど、だれか教えてえらい人
追記1 コメントのおかださんの結果のグラフです
6コア12スレッド!
SUM_TIMES = 30になっていたときの結果なので、時間は短くなっていますが、2600K 3.4GHzだと2スレッド以上で速くなったときに1.8秒だったので、倍近く速い!
HTは効いてませんね。
追記2 結局、メモリをチャネル0側に両方挿していたのでデュアルチャネルになってなかったという話。
4コア8スレッドマシンのメモリを2枚から4枚に増やしたらいろいろわかった - きしだのHatena
ソースです。
JDK7の数値のアンダーバー区切りのおかげで、大きい数値が見やすいです。
集計は10試行の最初3試行を捨てて、最大値と最小値を省いた5試行の平均になっています。
最初SUM_TIMES = 30になってたのですが、計測時と同様100に修正しました。試すときは30でも傾向かわらないので、そっちのほうが時間くわなくていいと思います。
package sample;import java.util.LinkedHashMap;import java.util.Map;import java.util.Random;publicclass ParallelSum {publicstaticfinalint DATA_COUNT =150_000_000;//データ数staticfinalint COUNT =10;//計測回数staticfinalint AVOID =3;//時間の集計をしない回数privatestaticfinalint[] THREAD_COUNTS = {1,2,4,6,8};staticfinalint SUM_TIMES =100;//合計を行う回数publicstaticvoid main(String[] args) {//データ作成int[] data =newint[DATA_COUNT]; Random r =new Random(505); r.nextInt();//最初の値は捨てておくfor(int i =0; i < data.length; ++i){ data[i] = r.nextInt(100); }//計測実行 Map<Integer, Double> times =new LinkedHashMap<>();for(int n : THREAD_COUNTS){long min = Long.MAX_VALUE;//処理時間の最小long max = Long.MIN_VALUE;//処理時間の最大long timeTotal =0;for(int i =0; i < COUNT; ++i){ System.out.print("start." + i);long t = proc(data, n);//処理の呼び出しif(i < AVOID)continue;//最初の数回は集計に含めない timeTotal += t;if(min > t) min = t;if(max < t) max = t; }//最大値と最小値を除いた平均処理時間を得る timeTotal -= min; timeTotal -= max;double t = timeTotal / (COUNT - AVOID -2.) /1000_000_000; times.put(n, t); System.out.printf("n:%d t:%f%n", n, t); }//全体の処理結果を表示 System.out.println("--- result ---");for(int n : times.keySet()){ System.out.printf("%d threads:%f(s)%n", n, times.get(n)); } }/** * 配列の数値を合計する時間を計測 *@param data 集計データ *@param n スレッド数 *@return 計算時間(ナノ秒) */staticlong proc(finalint[] data,int n){long startTime = System.nanoTime();long total =0;finallong[] results =newlong[n];//処理スレッド起動 Thread[] threads =new Thread[n];for(int t =0; t < n; ++t){finalint tt = t;finalint start = (int) ((long)data.length * t / n);finalint end = (int) ((long)data.length * (t +1) / n); (threads[t] =new Thread(new Runnable() {@Overridepublicvoid run() {//集計処理long subtotal =0;for(int j =0; j < SUM_TIMES; ++j){for(int i = start; i < end; ++i){ subtotal += data[i]; } } results[tt] = subtotal; } })).start(); }//処理の終了を待機して結果を集計try {for(int t =0; t < n; ++t){ threads[t].join(); total += results[t]; } }catch (InterruptedException ex) { }//処理時間を計測long time = System.nanoTime() - startTime; System.out.printf(" summary:%d time:%f%n", total, time /1000_000_000.);return time; }}

