NVIDIAのLLM、Nemotron 3 Nanoは賢いけどコーディングには向かないかも。Mamba 2の特性が悪く出てる?
NVIDIAから新しいモデル、Nemotron 3 Nanoが出ていました。30BのMoEでアクティブパラメータは3B。つまり30B-A3Bです。
試してみたら、かなり賢いんだけど、コーディングの長いやりとりをしてたら過去のコードをうろ覚えになってて変な挙動をしてました。
どうやら、Transformerの代わりに使ってるMamba 2だとそういう挙動になるみたい。自信がないので、こうやって書いたら、だれかが間違いを指摘してくれるはずメソッド。
追記:30Bモデルの主戦場になるのは、言語処理的な単機能部品だと考えると、長いやり取りは不要なので、かなり強いモデルではないかと思います。また別にブログかきます。たぶん。
Nemotron 3
Nemotronはこちらにブログが。
Inside NVIDIA Nemotron 3: Techniques, Tools, and Data That Make It Efficient and Accurate | NVIDIA Technical Blog
30B-A3Bということだったので、Qwen3 30B-A3Bと同じアーキテクチャなんかな?と思ったりもしたけど、Q4_K_M量子化のサイズが30Bなのに24GBあって、Qwen3は18Bだったので全然違いそう。
で、ブログを見ると、どうやらTransformerの代わりにMamba 2というのを使ってるみたい。
Mamba 2とMoeの層が全部で23層あって、3層に一回くらいMamba 2とMoeの間にAttentionが入ってる。
Mamba 2というのは、O(n2)なTransformerと等価な計算をO(n)で線形に計算できるようにものらしい。
PLaMo翻訳でも使ってますね。
これをNVIDIAの4bit浮動小数、NVFP4で学習したというモデル。
日本語は?
小説を出してもらったら、それなりの長さの物語を自然な日本語で書いてくれました。
日本知識
奈良になんで都ができたか聞いてみたら、結構くわしく説明してくれました。
正しいかどうかようわからん。けど違和感あることは書いてなさそう。
話題として出してくる項目や構成など見ても、結構いい感じです。
要約
この記事の全文を渡して要約してもらいました。
IT土管はAIにまかせて、人間は情報に価値をのせよう - きしだのHatena
だいたい文意は拾えてそう。
あと、宮沢賢治の「注文の多い料理店」を400文字で。
だいたいの文章は抜き出せてるけど、物語の筋はよくわからないことに。
面白いのが、Thinkingの中で素案を出してカウントしてるところ。律儀だ。
論理的思考
「64歳以上であれば100円、64歳未満は1000円」を整数四則演算で実現してもらいます。
Reasoningモデルで、1分ちょい考え込んでいました。ループに入ってないかなと思ったけど、ちゃんと答えが。
が答えです。127歳までは正しく計算できます。
14BのMinistral 3だけでなく106BのGLM 4.6Vでも思考が無限ループしてたのを考えると、妥当な答えが出るだけでえらい。
Ministral 3は性能はもう一歩だけど存在が大切。文字読み取り性能は高い - きしだのHatena
Z.aiの新しい画像言語モデルGLM 4.6Vよさそう - きしだのHatena
128歳で-800になると文句を言うと、3分半考えて、次のような答え。
変数を使ってますが、展開すれば四則演算だけで計算できます。
長考してループに陥らずちゃんと答えを出すのはすごい。
あと、じゃあいつも長考するかというとそうでもなく、小説や奈良の話では2-3秒の思考でした。 思考時間の調整がうまくいってそう。
コーディング
いつも通りブロック崩しを。1ヶ所、手で修正したのだけど、ちょっとボールの動きはおかしいけど、それなりのコードができてます。
ただ、まず気になったのが、最初にクラスごとにわかれたソースを出したあとで1ファイルにまとめてきたんだけど、たとえば最初のBallクラスの末尾はこれ。
そしてまとめられたコードでのBallクラスの末尾。
ロジックは同じだけど、publicが消えていたり、変数名が違ったり、メソッドが増えてたり、微妙な違いがあります。
で、動かしたら例外が出たので貼り付けると、「あなたのコード」と人ごとのような対応。そして、コードの存在を忘れて、「例としては次のような書き方」って言ってます。
そのあとのやりとりでも、ちょっと要領を得ない感じがありました。
なんか、見えているコンテキストが狭そう。
で、例外が出てたのはここのnew Colorで、BRICK_ROWSは5なので150+4*30=270になって、ここでは255までしか指定できないというもの。
for (int r =0; r < BRICK_ROWS; r++) {for (int c =0; c < BRICK_COLS; c++) {int idx = r * BRICK_COLS + c; bricks[idx] =new Brick(...new Color(0,150 + r *30,255) ); }}
なんだけど、「期待しない型や値を渡しています」と説明が。それだとコンパイルエラーで、例外にはならないというのに。
ということで、エラー対応も苦手かも。
コードを書く能力はあるけど、エラー処理がにがてで、なにより離れたところのコードがうろおぼえっぽい挙動をするので、コーディングエージェントには使えないかも。
まとめ
なんか調べたりChatGPTやGeminiに聞いてると、どうも離れたコンテキストを圧縮していくような挙動になっているらしく、どんどんうろおぼえみたいになるらしい。
これは、長い範囲を正確に把握する必要のない要約や翻訳、離れた過去はうろおぼえでもいいような対話では問題なく、むしろ長い対話を適切に行えると思うのだけど、離れた部分でも正確に扱える必要のあるコーディングでは使えないんじゃないかという気がした。

LLMにやさしいSui言語にやさしいLLMを作る
LLMにやさしいSui言語が話題だった。
で、「ヤサシクナイヨ」とか書いてたのだけど、それならSui言語にやさしいLLMを作ってみるのはどうか。
LLMにやさしい言語SuiはLLMにやさしくなさそう - きしだのHatena
まあ、ファインチューンという金槌を持ってウロウロしてるところにSui言語という釘を見つけたので打ってみましょう、ということで。
データセットを作る
最初はCodeNetのコードをSuiに変換してデータセット作ろうかと思ったのだけど、Suiで書くにはちょっとコードが複雑すぎるのでやめた。
簡単な問題をChatGPTに作ってもらう。
整理して80件になった。まあデータセットとしては少なすぎるけど、今回は小さいモデルを学習させるだけなのでどうにかなるはず。(追記:どうにかならなかった・・)
そしてgpt-oss-120bにコードを書いてもらう。
コードはここ。「さくらのAI Engine」で動くようにしてる。無料枠で余裕で動かせる。
https://gist.github.com/kishida/e040f1755c3ddeab307deb5f0319808c
できたデータセットはここに置いた。
kishida/sui-lang-examples · Datasets at Hugging Face

ファインチューンする
さて、データができたので、なんかLLMのファインチューンをしたい。
たぶん4Bだと書けない気がするので、8Bくらい、ということでQwen3-8Bを調教する。
UnslothさんのDockerを使ってJupyter Notebookを動かす。
Fine-tuning LLMs Guide | Unsloth Documentation
とりあえず15stepsほど学習させてみる。
lossも順調に下がってる。
過学習の気配。というか30steps、3epoch学習させると見事に過学習してたので、15stepsにしてる。
試しに動かすと、それっぽいコードが出てそう。
Google Colabで試せるノートブックこちら。
Google Colab
とりあえずGGUFが出来たのでこちらに。
kishida/sui-lang-qwen3-8b-GGUF · Hugging Face
結果
まず、普通のQwen3-8Bで動かしてみる。量子化はQ4_K_M。
こんな感じに。
これはこんな感じのコード。ダメそう。
f0 (a0, a1, a2) { v0 = a0 > a1 v1 = a2 > v0 return v1}できたGGUFをLM Studioで読み込んでみる。

なんかそれっぽいコードを出すようになった。
こんな感じなので、それっぽさはあるけどlabel_1がないしcompareの引数も足りない。
var g0f0 (a0, a1, a2) { v0 = a0 v1 = a1 v2 = a2 g0 = v0 > v1 g1 = !g0 if (g1) goto label_1 g2 = v0 < v2 g3 = g2 == ??(※ 足りない) return g3}まあ、それっぽいコードを吐くようには なった。 ただ、なんかデータを300件くらい作るかモデルサイズが14Bくらいないと難しいかも。システムプロンプトに構文の説明を入れるものと入れないものも分けたほうがよさそう。
データセット内のコードをちゃんと見てないので、マジメにやるなら動作確認や手作業での修正も必要そう。
まとめ
ということで、データセット作って学習させて試してみるという一連の流れをやってみました。
ほんとは言語リファレンスなしでもちゃんと書けるようになると面白いのだけど、そうすると継続事前学習が必要で手間が増えるのとウチの16GB VRAMではメモリが足りなかった(21GB使ってた)ので、今回はあきらめてシステムプロンプトに言語リファレンス入れてます。
ところでこの本を献本でいただいたけど、プロンプトエンジニアリングからLangChain、RAG、オブザーバビリティにAIエージェントまで、AIシステム開発に必要なことが広く必要なことが書かれていてよさそう。
※ ファインチューンまでは触れられてません。
Z.aiの新しい画像言語モデルGLM 4.6Vよさそう
GLM 4.6Vが出てるのでMLXの4bit版を試してみました。
106BのMoEでアクティブパラメータは12B。画像や動画に対応しています。画像エンコーダーもあるので全体では108B。
ライセンスはMIT。
zai-org/GLM-4.6V · Hugging Face
GLM-4.6V: Open Source Multimodal Models with Native Tool Use
日本語表現
小説を書いてもらったら、日本語も流暢で結構いい感じ。
むずかしい問題
「64歳以上であれば100円、64歳未満は1000円」を整数四則演算だけで実現して。年齢制限なく対応できるように。
ループに入ってしまった。
このあたりはRemaining Issuesにも書いてある。
The model may still overthink or even repeat itself in certain cases, especially when dealing with complex prompts.
コード
いつもどおりブロック崩し。
エラーを一回だしたものの、ちゃんと動くコードが出た。
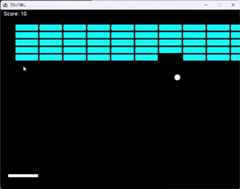
ただ、Thinkingが長い。最中に一旦コードを出力したりしていた。
そして、ちょっと修正してもらう。
これもすんなり実装してくれた。Thinkingも妥当な内容だった。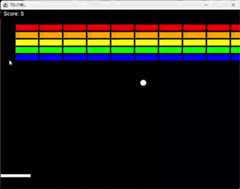
かなり安定してコードを書いてくれる印象。
Thinkingの抑制
/nothinkを付けるとThinkingを省略できる。
けど、同じことを繰り返したり、ちょっと挙動があやしい。
enable_thinking を設定して抑制もできそうだけど、試してない。
量子化のせいかも。
画像よみとり
日本語読み取り、ほぼ完ぺき。
ただ、begin_of_boxのようなコントロールトークン出てしまってます。Jinjaテンプレートにbegin_of_boxがないんで、テンプレートの問題かな。
画像を渡してJavaフォームを作ってもらうのも、再現度が高い。
まとめ
最近はGLM 4.5-Airをローカルではメインに使ってるけど、画像付きでバージョンアップした。
100B帯で唯一の画像言語モデルともいえるので、第一選択肢になりそう。
(Llama 4 Scoutが109Bだけど、ライセンスが使いにくいのと性能が低いので・・・)
LLMにやさしい言語SuiはLLMにやさしくなさそう
LLMにやさしい言語という謳い文句の言語、Suiが話題。
けどこれ、LLMにあまりやさしくなんじゃなかろうか。
https://github.com/TakatoHonda/sui-lang
9月にこういうエントリを書いてます。
AI専用のプログラミング言語は現れない - きしだのHatena
ここで理由として挙げたのは、この4点です。
- すでにAIは独自の言語を持っている
- 低レベルな記述にはコストがかかる
- 意味の記述が必要であることに変わりはない
- 作っても学習させるのが大変
この4点にあてはまっていると思います。
追記:
あと、こういうことも10月に書いてます。
AIが読み書きするコードも読みやすいほうがいい(トランスフォーマの特性の考慮やリーダブルコードについて追記) - きしだのHatena
去年の4月ですが、こういうことも書いてました。
AIがコードを書くようになるなら、AIだけに理解できる言語を作ればいい、のかな? - きしだのHatena
ブコメに「永久に流行りのフレームワークもプログラミング言語も変わらないという事になるのでは」とありますが、すでにある程度プログラミング言語は完成しつつユースケースによっての住み分けも行われているので「今のプログラミング言語は1000年残る」ということを書いてます。
そして追記:
本田さんからの背景説明や方向性の説明のブログ出てます。面白かったので今回の話に興味ある方はぜひ。
「LLMにやさしい言語SuiはLLMにやさしくなれそう」|本田崇人(ほんだたかと)
さらに追記(12/14):
SuiにやさしいLLMを作る試みをやってみました。
LLMにやさしいSui言語にやさしいLLMを作る - きしだのHatena
トークンの節約になってない
まず、命令が記号1文字なのでトークンの節約になるということが書かれてますが、プログラム言語で頻出のキーワードはだいたい1トークンになっています。
ここで、.utilや");なども1トークンになっています。また、javaやpublicは前後のスペースも含めて1トークンです。つまり、よくある処理をよくある書き方で書けばトークンが節約されます。
このように、人間が見た通りにAIが扱っているわけではなく、すでに言語を扱いやすく変化させています。
一方で、cx = (px * scale) / width - (scale/2) + centerXに相当するSuiコードは次のようなトークン化がされています。vやaはひとつまえのスペースと共にトークン化されているので1トークンですが、やってる内容の割にトークン数が多いです。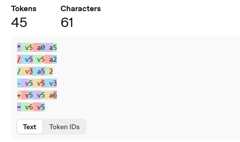
ちなみにcx = (px * scale) / width - (scale/2) + centerXは18トークンです。
命令が細粒度なので、一連の処理のための命令数が増えます。そうするとトークンがかなり増えていきます。
意味の記述が必要であることに変わりはない
実際にChatGPTにマンデルブローを書かせてみた先頭部分がこれです。結局、コメントとして仮コードが埋め込まれてますね。
; 16.16 固定小数点を使ったマンデルブロ集合の 1 ピクセル計算; f0(px, py, width, height, maxIter, scale_fixed, centerX_fixed, centerY_fixed) -> returns iter# 0 8 { ; args: a0=px, a1=py, a2=width, a3=height, a4=maxIter, a5=scale, a6=centerX, a7=centerY = v0 0 ; iter = v1 0 ; x (fixed) = v2 0 ; y (fixed) = v3 0 = v4 0 = v5 0 = v6 0 ; cx = v7 0 ; cy = v8 0 = v9 0 = v10 0 ; cx = (px * scale) / width - (scale/2) + centerX * v5 a0 a5 / v5 v5 a2 / v3 a5 2 - v5 v5 v3 + v5 v5 a6 = v6 v5また、Thinkingで次のような思考が行われています。Thinkingでは結局変数名を使った思考が行われる気がします。
「コメントを書くな」などの指示を行うと、恐らくThinkingでコードを書いてから、そのコードを抜いたものを出力するという挙動にもなりそうです。
と思ったけど、gpt-oss 120bは聞いてくれずコメント書いてた。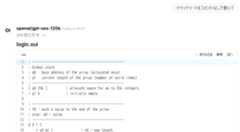
コメントに仮コードを書きながら書き下すのであれば、最初から高級言語を使うほうがトークンも節約できます。
自然言語で要求を与えて、自然言語でThinkingが行われるのであれば、結局のところ自然言語に近い高級言語のほうがLLMにやさしいように思います。
Sui版のマンデルブローは動かなかったので、JavaScriptで書いてもらいました。これは学習不足もあると思うので、言語の問題とは必ずしも言えないと思います。いまのLLMはJavaScriptで書かれたマンデルブローをたくさん学習してるはず。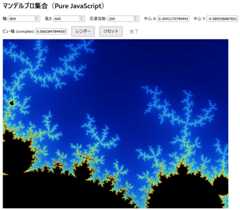
追記: AIがコードを読むとき変数名などをかなり参考にしているという論文ありました。
https://arxiv.org/abs/2510.03178v1
LLMには実際には厳しいんじゃなかろうか
細粒度の命令を組み合わせて処理を書くと、同じ処理の中では似たような命令列の繰り返しが多くなります。
そうすると、いまのLLMでは繰り返しが発生する可能性が高くなります。
実際、GLM 4.5-Airに「クイックソートをコメントなしで書いて」とやると、不要な処理を繰り返して止まらなくなりました。
LLMに学習させるにしても、頻出する命令列のパターンをたくさん学習させる必要があります。恐らく、現状でもある程度のコードが書けているのはアセンブリに近いからだと思います。けれども配列や関数など使いこなしてもっとうまく書かせようとすると、Suiならではのパターンをたくさん覚えさせる必要があります。
しかしながら、そういうパターンが既存言語の言語機能で表せるのであれば、LLMは既存言語の共通概念を学んでいるので、流用したほうがLLMにやさしいはずです。
また、変数が多くなってv99やv100などになったとき、その役割を覚えることはLLMにとって苦手なことです。特に、v100が必要なくらいコードが長くなって変数定義との距離があいてしまうと、間違いが増えると思います。
実際には、LLMに厳しい言語仕様のように思います。
性能が高いLLMであればこなすだろうけど、それはLLMに厳しいということになります。LLMにやさしいのであれば、サイズが小さく性能の低いLLMにも書きやすい必要があると思います。
プログラミング言語で発展した仕組みを流用したほうがいいのでは
プログラミング言語は、人間がわかりやすいだけではなく、論理を記述します。論理を記述することで、やりたいことを的確に正しく表現できることになります。というか、人間に簡単にわかりやすいものではないので、ある程度の訓練が必要です。
間違いを減らすには冗長性も大事です。v0やv1という名前は、cxとcyという名前より間違いに気付くのが難しくなります。LLMは記号の処理がうまいわけではなく、自然言語のほうが得意なので、自然言語に近い変数名のほうが扱いがうまいです。
LLMに間違いなくプログラムを書かせるには、それなりの型機能をもって自然言語と同じキーワードを持つ言語のほうが適しているように思います。
論理を発展させて計算を記述することがベースになっています。そこに人間が書きやすいような文法を当てはめているだけです。論理構造は既存言語が持つものと共通にしたほうが、LLMに書きやすくなるはずです。また、記号を独自の意味で使うよりも、広く使われる意味に近い使い方のほうがLLMに書きやすくなるはずです。
専用に学習させるにしても、基礎知識として学習させているWikipediaやPythonに近いほうが、知識を転移させやすいと思います。
いまのプログラミング言語は、70年かけて論理による制約と記述の容易さバランスがとられてきたものです。そうすると、ふつうのプログラミング言語が結局はLLMにとっても書きやすくなると思います。
追記Markdownに4文字付け足すだけのコミットもしました🎉。

)")

Ministral 3は性能はもう一歩だけど存在が大切。文字読み取り性能は高い
昨日、Mistral 3シリーズがリリースされました。モデルは675BのMistral 3 Largeと、3B、8B、14Bという手ごろなサイズのMinistral 3です。このMinistral 3でコーディングや画像認識、3Bモデルのファインチューニングを試してみました。
そこそこ使えて画像認識精度は高いけど、コードは書けないし性能もそこまで高くなさそう、けれどもQwen3以外の選択肢が出たのが大事、という感じ。
Introducing Mistral 3 | Mistral AI
基本的なやりとり
すべてQ4_K_Mの4ビット量子化で試しています。Q8にしてもおそらくそこまで性質は変わらなそうなのと、使えるハードウェアが広がること、gpt-ossは元々4ビットで公開されてたりQwen3も4ビットでちゃんと性能出てたりするので、4ビットでの性能は大事だと思います。
とりあえず日本語を見るために小説書かせてみます。案外ちゃんと書けました。筋も通ってるし、
というか、「俺たちの戦いはこれからだ!」やっとる
さまざまな基本知識もちゃんとあるようです。
ただ、話が長くて「聞きたいことソレじゃないんだけど」と思ってても出力が止まらずツッコミを許しません。
ffmpegでのフレームレート設定を聞いた場合も、聞いてないのに品質や圧縮率まで説明しはじめて、なかなか止まらなかった。
この傾向はMistral 3 Largeでも同様なので、出力量調整のような後段のファインチューニングまで手がまわってないように思います。
画像読み取り
Ministral 3は画像言語モデルで、画像を読み取れます。
ということで、3B-Instructで試してみます。
ちゃんと読み取ってるけど、日本語は怪しい。
日本語の読み取りは無理かなぁと思ったら、かなり読み取ってます。Sarahina2.2 VLほどではないものの8bit量子化と同程度、ほぼ間違いなし。
画像エンコーダーは、たぶんどのモデルも同じなので、読み取った後の対応を賢くしたければ大きいモデルを、という感じですね。
Reasoning
今回のMinistral 3のモデルにはそれぞれReasoningとInstructの両方が出てます。Largeは今のところInstructのみ。
[THINK]から[/THINK]までが思考ぽい。なので、LM Studioでは開始終了文字列の設定が必要です。
「「64歳以上であれば100円、64歳未満は1000円」を整数四則演算だけで実現して」と聞いてみます。
ちゃんとThinking判定してくれた。
けど、結論に至らずだらだらと思考を続けて同じ内容を繰り返すようになっていたので止めました。12Kトークン消費。
後述のブロック崩しを作るときも、思考過程で修正を3回くらいやって、完成コードを一旦だしてから返答が始まったりして、無駄に思考をこねくりまわしてるうちにコンテキストが伸びてアホになる、という感じ。
返答と同様に、どこでThinkingをやめていいか判断がついてなさそうです。
難しすぎる問題は無限ループ、簡単な問題はReasoningの必要がないので、使いどころは難しそうです。
ちなみにMinistral 3 Largeも普通に無限ループしていました。
コーディング
では、いつも通りブロック崩しを作ってみます。
が、14Bでも完成に至りませんでした・・・。
コードを出したあと、改善案みたいなのを出してきます。
いろいろ出したあと、また「全体コード」を出してくる。もちろん「こちら」のリンク先は404です。
返答を簡潔に出せずにいろいろ付け足してしまうのは、性能が低いモデルの特徴ですね。返答の精度とは別に、どこで返答を打ち切っていいかの判断が弱くて、延々と付け足してしまう。
なんかコードもあまり美しくないです。
このelseは中カッコ必要やろ、とか、なぜblockXを1行で、とか、colという名前は・・・みたいな。
それでコンパイル通って動くコードを出すならいいけど、コンパイルが通らないし、エラーを示しても、修正できず、動かすところまで行きませんでした。続けても無理そうだなというところで諦め。
コーディング力は、今年 見た中で一番ダメそう・・・。Qwen3 4Bでもコンパイル通るコードを書いた。
Mistral AIは、Devstral Smallという、24Bでかなりコード書けるモデルを作ってたのに、どうしてこうなった、という感じ。
Largeだとさすがにちゃんと動くコードを出してきました。コードもきれいだった。パドルの当たり判定おかしいけど。
Function Calling
3Bモデルで、ちゃんとToolを使えています。
コードはこちら。
Function Callingを試すサンプル · GitHub
10B以下でFunction CallingできるモデルがQwen3しかなかったので、他の選択肢が出たのがありがたいです。
Llama 3やGemma 3はTool対応なし、Phi 4 miniはTool対応してるということなんだけど、性能低くて「その関数あるのは知ってるけど使えません」みたいなことを言ったりしてました。
なので、Qwen3を使えない場合にFunction Callingできる一番小さいモデルはPhi-4の15BのQ4_K_M量子化だけど9GBあるので、Macならいいけど、Windowsだと12GB VRAMのGPUでもつらい。
Q2_S量子化だと5.6GBくらいだけど「以下のAPIを呼び出して、現在時刻を取得します」とだけ言って呼び出してくれなくなった。
Ministral 3BはCPUでもこの速さ。
ファインチューン
Unslothさんが早速ファインチューンやってたので、「明るくJavaコンパイルエラーを説明するデータセット」で学習させてみました。
Ministral 3: How to Run & Fine-tune | Unsloth Documentation
Unsloth Docker ImageではそのままだとMistral 3に対応してなかったので、いくつかパッケージのアップデートが必要。
pip install --upgrade --no-deps unsloth unsloth_zoopip install --upgrade git+https://github.com/huggingface/transformers.git@bf3f0ae70d0e902efab4b8517fce88f6697636ce
ちゃんと学習できてる!
3Bは学習させやすいけど、これまでライセンス的に使いにくいLlama3.2 3Bくらいしかなかったので、Apache 2.0というのもあってファインチューンの基盤としてもよさそうです。
GGUF保存もエラーが出ます。エラーを出したあとgguf-pyをGitHubの最新に更新してconvert_hf_to_gguf.pyを直接呼び出すとQ8_0で保存できました。
pip install --force-reinstall git+https://github.com/ggml-org/llama.cpp.git#subdirectory=gguf-py
ただ、なんかちょっと壊れてそう。
対応が進んで落ち着いてから試す方がよさそうです。
とりあえずHugging Faceに置いておきました。
kishida/java-error-explainer-jp-cheerful-ministral3-3b · Hugging Face
一応、学習できそうなノートブックを。
Javaのエラーを明るく説明するMinistral 3 3B
Google ColabだとT4だと難しいかも?

Sarashina-2.2-Vision-3Bの文字読み取りがすごい、けどVRAM 16GBではつらい -> 解決。VRAM12GBで使える
SB Institutionから日本の情報に特化した画像言語モデル、Sarashina-2.2-Vision-3Bが出ていたので試したところ、性能の高さは感じたものの、VRAM 16GBで動かすのがつらかったのでまとめました。
Sarashina2.2-Vision-3B: コンパクトかつ性能が高いVLMの公開 - SB Intuitions TECH BLOG
※use_cache=Trueつけたら解決!12GBで動きそうです。追記しています。
GradioでのUI
とりあえず、いろいろ試すたびにコードいじるのは面倒なので、gradioでUIをつけました。
ChatGPTに「gradioで、画像と短文を入力したら長文が返ってくるシステムのUIを作りたい。実際の処理はこちらで書くので、generate_text(intput_txt, image_pil)関数がある前提で画面構築のスクリプトを書いて。」として生成してもらって、上記ブログのサンプルコードを埋めていきます。※use_cache=True つける必要があります。
Sarashina 2.2 Vision 3BのGradio UI · GitHub
「たなかさん」認定された。
サンプルの読み取り
サンプルの画像とプロンプトを指定すると、こんな感じで、サンプルどおりの出力が得られました。乱数シードは設定していないので、サンプルとは微妙に違います。
住所は実際には湯之町5丁目6番なのでちょっと違いますが、サンプルと同じです。
起動時のメモリは、起動前に2.4GBつかってたので、7.2GBくらい使っています。3BでBF16なのでそんなものでしょう。
※追記generateの引数にuse_cache=Trueをつけると、メモリ消費もあまりありませんでした。
生成速度も問題ないです。
※ 追記ここまで。ここからはuse_cache=Trueをつけてないときの記述
出力後にはメモリぱつぱつです。
出力速度はこんな感じ。きびしい。静止画じゃないです。しばらく見てて。
文字読み取りをみてみる
経済産業省のAI事業者ガイドライン P7を読み取ってみます。
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20250328_2.pdf
完璧。すごい。
量子化を試す
メモリが厳しいので、load_in_8bit=Trueをつけて、量子化して試してみます。
起動前が1.5GBだったので、4.2GB。3GBほど削減されました。
同じ文章を読み取り。ちょこちょこ間違いがあります。確実に精度は落ちてますね。
読みとり終了時のメモリ使用量はこんな感じ。余裕がある。
量子化したら速くなるかなと思ったけど、生成速度は、ほとんど変わってないです。
load_in_4bitも見てみます。メモリは5.4GB。ほとんど変わってない。
「I am the language of my own tongue.」。。。
どっから出てきた?4bitは使い物にならんす。
生成速度も変わってないか、むしろ遅くなった気もするので、ただ壊れただけですね。
で、じゃあ精度はちょっと落ちるけど8bitで使うかなってなるのだけど、問題が。
ビル群も緑地も見当たらないのだけど。
文字以外の画像認識が壊滅的になっています。
bitsandbytesの簡易量子化ではなくGGUFつくるときのように時間をかけて最適化がされていればよさそうだけど、アーキテクチャ上GGUFも単純には作れなさそう。
ということでBF16のまま使いましょうってなります。
まとめ
精度がすごく高い画像言語モデルが、MITという使いやすいライセンスで出たのはとてもいいですね。ただ、3Bなので使いやすいかと思ったけど、メモリ的にも速度的にもちょっと厳しい。
今後は、使いやすさを、ということになりそうだけど、「精度は十分なので使いやすさを」と言えるモデルが日本特化で出たというのはうれしい。
パラメータを適切に設定すればメモリ的にも速度的にも問題ないです。VRAM 12GBで使えそう。
量子化やGGUF、MLXに対応して、VRAM 8GBやMacでも使えるようになるともっといいなと思います。
LINEのベース日本語言語モデルを強化学習で対話できるようにして賢さを評価する(過去下書き放出)
下書きにあったものをとりあえず放出。2023年8月おわりくらいの下書き。無加工なので、組織名などが当時のものになっています。
ココカラ。
LINEのNLP Foundation Devチームから36億パラメータの日本語言語モデルが公開されています。
https://engineering.linecorp.com/ja/blog/3.6-billion-parameter-japanese-language-model
そして、対話用にチューニングしたモデルも出ています。
https://engineering.linecorp.com/ja/blog/3.6b-japanese-language-model-with-improved-dialog-performance-by-instruction-tuning
なのだけど、対話モデルが出る前に、ベースモデルを調整して対話できるようにして、あとlm-evaluation-harnessで性能評価もしてみてたので、まとめておきます。
Instructionチューニング
言語モデルは、文章の続きを生成する仕組みになっています。なので例えば「言語モデルは、」を与えると、「言語モデルは、音声を解釈して、 音声を復号化する。」のような文章が生成されます。
LLMでのチャットの多くは、次のような対話履歴を渡して続きを生成させるようになっています。
ユーザー: 日本の首都は?システム: 東京です。ユーザー: 東京には何がある?システム:
けれども、これを対話用にチューニングされてないベースモデルに渡すと、次のように勝手に続きの対話を埋めていきがちです。もちろん、たまたまちゃんと返答になることもあります。
そこで対話用の返答のやりかたを仕込んであげる必要があるのですが、そのようなチューニングをInstructionチューニングと呼ぶようです。
LINEの対話モデルもInstructionチューニングされていますが、今回はそれを自分でやってみようという感じ。
Instructionチューニング用データセット
そうすると、学習のためのデータセットをどうするかということになります。ここで、DatabricksがEleutherAIのpyhiaをInstructionチューニングした[Dolly 2.0]があります。
Free Dolly: Introducing the World's First Open and Commercially Viable Instruction-Tuned LLM - The Databricks Blog
このチューニングに使われたデータセットが公開されています。
databricks/databricks-dolly-15k · Datasets at Hugging Face
そして、このデータセットをkunishouさんが日本語化されていますので、これを使いましょう。
kunishou/databricks-dolly-15k-ja · Datasets at Hugging Face
LoRAファインチューニング
ということでチューニングをするのだけど、36億パラメータを全部更新するようなファインチューニングには読み込んだパラメータの数倍のVRAMが必要になります。
そんなメモリはない!そこで、パラメータの一部を更新していい感じにチューニングを行うLoRAというテクニックを使います。
といっても、PEFT(Parameter-Efficient Fine-Tuning)というライブラリがあるのでそれを使うだけだけど。
https://github.com/huggingface/peft
ただ、PEFTではどこのパラメータを更新するのか指定する必要があります。
それを確認するためにこういうコードを動かす。モデルを読み込んで表示するだけ。
from transformersimport AutoModelForCausalLMmodel_name ="line-corporation/japanese-large-lm-3.6b"model = AutoModelForCausalLM.from_pretrained( model_name, device_map='cpu')print(model)
こんな感じに表示されます。GPTNeoXというモデルになってることがわかります。
GPTNeoXForCausalLM( (gpt_neox): GPTNeoXModel( (embed_in): Embedding(51200, 3072) (emb_dropout): Dropout(p=0.0, inplace=False) (layers): ModuleList( (0-29): 30 x GPTNeoXLayer( (input_layernorm): LayerNorm((3072,), eps=1e-05, elementwise_affine=True) (post_attention_layernorm): LayerNorm((3072,), eps=1e-05, elementwise_affine=True) (post_attention_dropout): Dropout(p=0.0, inplace=False) (post_mlp_dropout): Dropout(p=0.0, inplace=False) (attention): GPTNeoXAttention( (rotary_emb): GPTNeoXRotaryEmbedding() (query_key_value): Linear(in_features=3072, out_features=9216, bias=True) (dense): Linear(in_features=3072, out_features=3072, bias=True) (attention_dropout): Dropout(p=0.0, inplace=False) ) (mlp): GPTNeoXMLP( (dense_h_to_4h): Linear(in_features=3072, out_features=12288, bias=True) (dense_4h_to_h): Linear(in_features=12288, out_features=3072, bias=True) (act): GELUActivation() ) ) ) (final_layer_norm): LayerNorm((3072,), eps=1e-05, elementwise_affine=True) ) (embed_out): Linear(in_features=3072, out_features=51200, bias=False))
LoRAでは基本的にアテンションの線形レイヤーを対象にすればいいということなのでLinearを探します。(attention)というところを見ると(query_key_value)と(dense)という層があるのがわかります。そして、だいたい`(query_key_value)'だけを対象にすればいいっぽい。
import torchimport datasetsfrom transformers import AutoTokenizer, AutoModelForCausalLM, Trainer, TrainingArgumentsfrom peft import get_peft_model, LoraConfig, TaskType, PeftModel, PeftConfigmodel_name = "line-corporation/japanese-large-lm-1.7b"peft_model_name = "peft_model"dataset_name = "kunishou/databricks-dolly-15k-ja"targets = ["query_key_value"]prompt_template_cqa = """ユーザー: 次の情報を元に質問に答えてください。{input}システム: わかりました。ユーザー: {instruction}システム: """prompt_template_oqa = """ユーザー: {instruction}システム: """def encode(sample): if (sample["input"]): prompt = prompt_template_cqa.format(instruction=sample["instruction"], input=sample["input"]) else: prompt = prompt_template_oqa.format(instruction=sample["instruction"]) target = sample["output"] + tokenizer.eos_token input_ids_prompt, input_ids_target = tokenizer([prompt, target]).input_ids input_ids = input_ids_prompt + input_ids_target labels = input_ids.copy() labels[:len(input_ids_prompt)] = [-100] * len(input_ids_prompt) return {"input_ids": input_ids, "labels": labels}def get_collator(tokenizer, max_length): def collator(batch): batch = [{ key: value[:max_length] for key, value in sample.items() } for sample in batch ] batch = tokenizer.pad(batch, padding=True) batch["labels"] = [ e + [-100] * (len(batch["input_ids"][0]) - len(e)) for e in batch["labels"] ] batch = { key: torch.tensor(value) for key, value in batch.items() } return batch return collator# prepare datasettokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)dataset = datasets.load_dataset(dataset_name)dataset = dataset.map(encode)dataset = dataset["train"].train_test_split(0.2)train_dataset = dataset["train"]val_dataset = dataset["test"]# load modelbase_model = AutoModelForCausalLM.from_pretrained(model_name, device_map={"": 0}, torch_dtype=torch.float16)peft_config = LoraConfig( task_type=TaskType.CAUSAL_LM, inference_mode=False, target_modules=targets, r=16, lora_alpha=32, lora_dropout=0.05)model = get_peft_model(base_model, peft_config)model.print_trainable_parameters()training_args = TrainingArguments( output_dir="./train_results", learning_rate=2e-4, per_device_train_batch_size=4, gradient_accumulation_steps=4, per_device_eval_batch_size=16, num_train_epochs=1, logging_strategy='steps', logging_steps=10, save_strategy='epoch', evaluation_strategy='epoch', load_best_model_at_end=True, metric_for_best_model="eval_loss", greater_is_better=False, save_total_limit=2)trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset, eval_dataset=val_dataset, data_collator=get_collator(tokenizer, 512))trainer.train()model = trainer.modelmodel.save_pretrained(peft_model_name)評価
https://github.com/Stability-AI/lm-evaluation-harness
https://github.com/Stability-AI/lm-evaluation-harness/blob/jp-stable/docs/prompt_templates.md
ユーザー: 与えられた選択肢の中から、最適な答えを選んでください。システム: 分かりました。ユーザー: 質問:{question}選択肢:- {choice0}- {choice1}...- {choice4}システム: {answer}open file in utf-8 by kishida · Pull Request #11 · shunk031/huggingface-datasets_JGLUE · GitHub
3 epochでチューニング
先ほどは各データ1回ずつという1 epochで学習を行ったのだけど、3 epochほどまわしてみました。
9時間半かかって終了。
A100 80GBを8台使い、3epoch学習しました。1epochの学習にかかる時間はおおむね10分程度でした
というのを見ると「GPU力こそパワー」というのを実感しますね。


LoRAモデルのマージ
# https://note.com/__olender/n/n7913ac32c18c#f6bc06e7-c594-42ff-a8f6-72c1a5aab972import torchfrom peft import PeftConfig, PeftModelfrom transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "line-corporation/japanese-large-lm-3.6b"peft_name = "lora/dolly-line-3.6b"output_dir = peft_name + "-merged"# PEFT(LoRA)の指定peft_config = PeftConfig.from_pretrained(peft_name)print (f"lora loaded {peft_name}")# ベースモデルの読み込みmodel = AutoModelForCausalLM.from_pretrained( model_name, return_dict=True, torch_dtype=torch.float16,)print (f"model loaded {model_name}")# Rinnaのトークナイザーでは、「use_fast=False」も必要になるtry: tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast = False)except ValueError: tokenizer = AutoTokenizer.from_pretrained(model_name)# PEFT(LoRA)の読み込みmodel = PeftModel.from_pretrained(model, peft_name)# マージモデル作成merged_model = model.merge_and_unload()# 出力merged_model.save_pretrained(output_dir) tokenizer.save_pretrained(output_dir)print(f"Saving to {output_dir}")
