BigQueryで自由記述形式のデータを分類する方法 Part 2 ~ Vector Search 編 ~


はじめに
さて今回はBigQueryで自由記述形式のデータを分類するPart 2ということで、予告通りVector Search を利用したテキスト分類を手軽にできるのか検証していきたいと思います。(前回のブログでVector Search Indexと述べてますが、Vector Searchを利用するという部分が趣旨になります。)利用するデータはPart 1と同じ駐車場申し込みのキャンセル理由となりますがインデックスの作成なども検証したかったので前回よりもデータが多めです。検索対象となるデータが5000件に満たない場合はそもそもインデックスを作成する意味がないため、Vector Search Indexは利用できないのでご注意ください。なお、結論から言うと前回実施したgeminiIを利用した手法よりは精度が劣っており今回は70%程度の正答率でした。
前回のブログはこちらnealle-dev.hatenablog.com
前提条件
実施にあたり下記の設定が必要になります。
- BigQuery Connection APIの有効化
- Vertex AI APIの有効化
- Cloudリソース接続の作成
基本的にML.GENERATE_EMBEDDING 関数を使用してテキスト エンベディングを生成する | BigQuery | Google Cloudこのリンクに全て書いてありますのでご一読ください。
カテゴリ分類の手順
今回の目的はVector Search Indexを利用した駐車場申し込みのキャンセル理由の分類になります。手順としては
- テキスト埋め込みモデルを利用してキャンセル理由をベクトル化し、テーブルに保存する
- カテゴリとそのカテゴリの説明文を用意してベクトル化する
- Vector Search Indexを生成する
- キャンセル理由と最も距離の近い説明文のカテゴリを抽出する(VECTOR_SEARCH関数を利用)
このようになります。また、テキスト埋め込みモデルとして今回は多言語対応版のtext-multilingual-embedding-002を利用します。(ファインチューニングは別の機会で!)なお操作はコンソール上から実施していきます。それでは早速実施していきましょう。
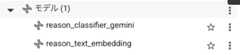
データセットにモデルを作成する
接続設定、データセットはPart 1のものを流用しています。(なので接続設定にgeminiとついてますね。。)
CREATEORREPLACE MODEL `test.reason_text_embedding` REMOTEWITH CONNECTION `asia-northeast1.vertex_gemini_connection` OPTIONS (ENDPOINT ='text-multilingual-embedding-002');
上記のクエリをコンソールから実行すると指定したデータセット内にモデルが作成されます。

キャンセル理由をベクトルに変換する
キャンセル理由が入ったテーブルはtest.cancel_reasonsでカラムはreasonとなります。今回は5000件以上のキャンセル理由が入っています。reasonの中身を以下に示すクエリでベクトル化して、test.cancel_reasons_embeddingに保存します。
CREATEORREPLACETABLE test.cancel_reasons_with_embeddingsASSELECT content, 元のキャンセル理由の文章 text_embeddingFROM ML.GENERATE_TEXT_EMBEDDING( MODEL `test.reason_text_embedding`, (SELECT reasonAS contentFROM `test.cancel_reasons`), STRUCT('SEMANTIC_SIMILARITY'as task_type)-- );
文章が入っているカラムはcontentという名前である必要がありますのでエイリアスをつけています。今回はキャンセル理由とカテゴリの説明文のベクトルを比較し、距離が近いものをカテゴリとするためtask_typeにはSEMANTIC_SIMILARITYを選択します。ロジスティック回帰などの判別器を利用して分類を行う場合はCLASSIFICATIONが良いと考えられます。
カテゴリ定義をベクトルに変換する
まずはカテゴリ定義のテーブルを作成します。カテゴリ名と実際のキャンセル理由を対応させたデータになります。このテーブルのレコードを増やすほど精度が上がっていきますが、手動で分類するのでその手間とのトレードオフになります。今回は50ほどキャンセル理由からサンプリングしています。増やしすぎると手軽さがなくなりますね。。
CREATEORREPLACETABLE test.cancel_reason_categoriesASSELECT'別の駐車場が見つかった'AS category,'他の駐車場が見つかり既にそちらを契約してしまった'AS cancel_reasonUNIONALLSELECT'別の駐車場が見つかった'AS category,'借りたい期間や賃料が安いなど他の条件の良い駐車場が見つかった'AS cancel_reasonUNIONALLSELECT'顧客都合でのキャンセル'AS category,'転居のため不要になった'AS cancel_reasonUNIONALLSELECT'顧客都合でのキャンセル'AS category,'車検証やナンバー、車種、氏名、電話番号などの申し込み情報に入力した内容に誤りがあった'AS cancel_reasonUNIONALLSELECT'区画を変更したい'AS category,'違う区画に移動したいので申し込みをキャンセルした'AS cancel_reasonUNIONALLSELECT'区画を変更したい'AS category,'10番の区画の方が良かったのでそちらに変更するため申し込みをキャンセルした。'AS cancel_reason# 以下合計で50件ほど
上のクエリで作成したテーブルを先ほどのキャンセル理由のテーブルと同様にベクトル化します。
CREATEORREPLACETABLE test.cancel_reason_categories_with_embeddingsASSELECT category, content, text_embeddingFROM ML.GENERATE_TEXT_EMBEDDING( MODEL `test.reason_text_embedding`, (SELECT category, cancel_reasonAS contentFROM `test.cancel_reason_categories`), STRUCT('SEMANTIC_SIMILARITY'as task_type) );
ベクトルインデックスの作成
ベクトルインデックスの作成を行います。準備としてはこれで最後になります。
CREATE VECTORINDEX cancel_reason_indexON sentenceest.cancel_reasons_with_embeddings(text_embedding) OPTIONS(distance_type='COSINE', index_type='IVF')

このように表示されます。インデックスが作成されるまで待つことになります。
進捗は下記のクエリで確認できます。
SELECT TABLE_NAME, INDEX_NAME, INDEX_STATUS, COVERAGE_PERCENTAGEFROM `test.INFORMATION_SCHEMA.VECTOR_INDEXES`
下記のようにカバレッジが100になっているとインデックス作成が完了しています。

カテゴリを分類する
さていよいよカテゴリを分類するところまで来ました。VECTOR_SEARCHを利用した以下のクエリを実行します。distanceが0.3以上の場合はその他と分類させます。ここはかなり恣意的なので結果を見て調整すると良いかと思います。
SELECT query.contentAS reason,CASEWHEN distance <0.3THEN base.categoryELSE'その他'ENDAS category, distanceFROM VECTOR_SEARCH(TABLE `dev_test.cancel_reason_categories_with_embeddings`,'text_embedding',TABLE `dev_test.cancel_reasons_with_embeddings`, top_k =>1, distance_type =>'COSINE')ORDERBY reason
結果は。。
結構誤った分類が目につきます。300件ほどサンプリングして確認したところ70%程度が正しく分類されているような具合でした。この方法は実用的であるとは言い難いかもしれません。
終わりに
今回はBigQueryのVector Searchを利用して、自由記述形式のキャンセル理由を分類するという試みを行いました。結果としては、約70%程度の正解率となり、この手法をそのまま実運用に乗せるには課題が残る、というのが正直な感想です。
精度が伸び悩んだ要因としては、カテゴリを定義するために用意したサンプルデータが50件と少なかった点が考えられます。このサンプルを増やせば精度向上は見込めますが、手動でのラベリングコストが増大するため、手軽さというメリットが失われてしまいます。また、類似度の閾値を0.3としましたが、この値も結果を見ながら調整する必要があり、最適な設定を見つけるには試行錯誤が必要となります。
手軽さという観点で今回このような検証を行いましたが、手軽さと精度のいずれの点でも前回実施した生成AIに分類してもらう方が筋が良さそうだなと感じました。また機会があればBigQuery MLのロジスティック回帰分類やブーステッドツリー分類モデルを利用する手法も試していきたいと思います。
最後になりますが、ニーリーでは一緒に働く仲間を募集中です。「ちょっと話を聞いてみたいかも」そんな軽い気持ちでも大歓迎です。ぜひカジュアル面談にお越しください。
- SRE (25)
- AWS (21)
- 組織・文化 (20)
- イベントレポート (16)
- QA (12)
- AI (10)
- データ基盤 (9)
- #ニーリー開発組織の野望 (9)
- 生成AI (7)
- Python (6)
- Datadog (6)
- セキュリティ (5)
- データ分析 (5)
- BigQuery (5)
- SET (5)
- ツール紹介 (4)
- Redash (4)
- TOROCCO (4)
- リモートワーク (3)
- コーポレートエンジニアリング (3)
- Celery (3)
- アーキテクチャ (3)
- プロダクトエンジニア (3)
- IaC (3)
- 在籍エントリ (3)
- 開発手法 (2)
- ドキュメント管理 (2)
- プロダクトマネジメント (2)
- リファクタリング (2)
- スクラム (2)
- Angular (2)
- インフラ (2)
- CI/CD (2)
- dbt (2)
- TypeScript (2)
- Playwright (2)
- サクセスエンジニアリング (2)
- ユニットテスト (1)
- 自由研究 (1)
- Autify (1)
- 協賛 (1)
- 入門記事 (1)
- EC2 (1)
- GAS (1)
- ラーメン (1)
- プラットフォームエンジニアリング (1)
- パフォーマンス (1)
- イベント登壇レポート (1)
- インシデント振り返り (1)
- インターン (1)
- デザイン (1)
- コードレビュー (1)
