- Notifications
You must be signed in to change notification settings - Fork144
python 数据结构与算法 leetcode 算法题与书籍 刷算法全靠套路与总结!Crack LeetCode, not only how, but also why.
License
ls1248659692/leetcode
Folders and files
| Name | Name | Last commit message | Last commit date | |
|---|---|---|---|---|
Repository files navigation
作者: Jam
算法有三种:面试算法,竞赛算法和工程算法, 针对不同的类型需要采取不一样的策略和系统性练习,本仓库主要针对面试算法。
竞赛算法追求的是在一定的时间内,实现一定的算法和数据结构,以解决某一特定的、可能并不具有现实意义的问题,主要用于培养算法思维。
工程算法追求的是实现一定的算法和数据结构以解决某一特定的具有实际现实意义的问题,对运行速度有极致的追求会直接影响用户体验。
个人简介: 化工行业转行计算机全靠自学,目前在国内大厂工作,在力扣上传了数百道问题的解法,本仓库主要是为了总结算法套路与帮助和我一样转行,以及想深入学习算法有大厂梦的兄弟和姐妹们。
刷题写代码环境, IDE选用 Pycharm 配置几个必要写代码插件Pycharm 写代码插件 ,并配置leetcode 刷题插件 方便直接拉取 Leetcode-cn 算法题,直接在IDE 里面写代码和套用算法模板,提高刷题效率,选用 Python 作为刷算法题语言,主要原因也是刷题效率。
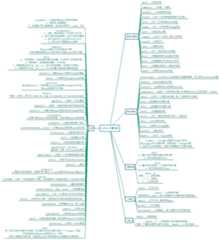
算法题分类思维导图:
- 本仓库的 spider 文件夹下spider/problems 都是基于 LeetCode 的题目和解法,已经爬取了Leetcode-cn 的全部算法练习题,已经按照不同类型分类规整整理,方便后续算法题对比与总结 。有助于帮助大家做到同类型题举一反三,一通百通
- 本仓库的 book 文件夹下算法体系化学习书籍和面试题有相关算法系统学习书籍和题目推荐, 主要是针对算法入门的小伙伴参考。
- 做算法常用 Python 的标准库中有很多内置函数,它们的运行效率都很高,因为很多标准库是使用 C 语言编写的,不要重复造轮子,不要重复造轮子,不要重复造轮子。

{kind=link}
- 职业训练:拆分知识点、刻意练习、总结
- 五步刷题法(五毒神掌)
- 做算法的最大误区:只刷一遍
- 新手建议先从简单题开始刷起,从30min/题 提升到 5min/题 就可以开始挑战刷中等难度题
- 大厂面试只要你能不看答案刷中等难度题,基本国内大厂随便进(能够讲出如何优化算法并实现,提高算法时间效率一般面试官会给比较好的评价)
- 始终保持匀速前进,既不松懈倦怠,亦不急于求成,定时归纳总结, 按类训练,深度理解人的记忆规律,高频率高效复习
- 拥抱孤独, 过滤外界杂音, 平稳心态
- 确定和面试官沟通的是否一致,问清楚,题目要看清楚
- 想所有可能的解法,找时间最优解法
- coding(多写)
- test cases(测试样例)
- 读题:5分钟读题+思考
- 自己暴力破解并对暴力破解方法进行优化
- 优化后看解法(理解多个解法)比较自己和高赞题解的区别并学习
- 根据别人的题解思路背诵默写
- 马上自己写,提交lc(leetcode),代码要简洁与优美,完全按照pep8规范
- 多种解法比较,体会 -> 优化(执行时间和ac)
- 过了一天再重复做题
- 不同熟悉的解法程度->专项训练
- 过了一周:再反复练习相同题目
- 专项训练
- 面试前一周恢复训练
- 面试前一周复习算法模板与相应分类出现的题目
- 短期记忆: 持续若干天或者一两周的记忆
- 中期记忆: 持续数周或者几个月的记忆
- 长期记忆: 持续数年甚至永世不会消逝的记忆
德国的心理学家艾宾浩斯告诉我们,人对于知识的遗忘速度遵循 "先快后慢" 的原则。学得的知识在一天后,如不抓紧复习,很快就只剩下原来的 25%。而随着时间的推移,遗忘的速度会减慢,遗忘的数量也就减少。去有效抵抗这种遗忘现象,最好的办法就是进行有规律的复习 (每 5 分钟,30分钟,12小时,1天,2天,4天,7天,15天,1个月,3个月,6个月)
20 个最常用的、最基础数据结构与算法,都已经总结在算法题模板分类
10 个必考数据结构模板:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树。
10 个必会算法模板:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法。
- 大小为 K 的子数组的最大和
- Best Time to Buy and Sell Stock
- Longest Substring Without Repeating Characters
- Sliding Window Maximum
- 剑指 Offer 57 - II. 和为s的连续正数序列
# Sliding windows code template is most used in substring match or maximum/minimum problems.# It uses two-pointer as boundary of sliding window to traverse, and use a counter(dict) maintain current state,# and a count as condition checker, update it when trigger some key changes.## Time: O(n)# Space: O(k) k = len(set(p))fromcollectionsimportCounter# s - target sequence, p - pattern or restrict sequencedefsliding_window_template_with_examples(s,p):# initialize the hash map here# counter is used to record current state, could use defaultdict in some situation, for example, no p restrictcounter=Counter(p)# two pointers, boundary of sliding windowstart,end=0,0# condition checker, update it when trigger some key changes, init value depend on your situationcount=0# result, return int(such as max or min) or list(such as all index)res=0# loop the source string from begin to endwhileend<len(s):counter[s[end]]+=1# update count based on some conditionifcounter[s[end]]>1:count+=1end+=1# count condition herewhilecount>0:''' update res here if finding minimum '''# increase start to make it invalid or valid againcounter[s[start]]-=1# update count based on some conditionifcounter[s[start]]>0:count-=1start+=1''' update res here if finding maximum '''res=max(res,end-start)returnres# refer to https://leetcode.com/problems/minimum-window-substring/discuss/26808/here-is-a-10-line-template-that-can-solve-most-substring-problems
双指针通常用在排好序的数组或是链表中寻找对子, 或者是merge 或者是排序,或者去除element,反正一般都是头尾各一个指针,然后根据条件移动。
- Two Sum(# 也可以用map的方式做)
- Two Sum II - Input array is sorted
- Squares of a Sorted Array (很像merge sort里的merge)
- Move Zeroes
- Remove Element
- Remove Duplicates from Sorted Array
- 3Sum Closest
- 4Sum
- Partition List
- Container With Most Water
- Trapping Rain Water
- Sort Colors
- 剑指 Offer 04. 二维数组中的查找
- 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面
# two pointers scenario, famous applications such as binary search, quick sort and sliding window.'''Classification:1. old & new state: old, new = new, cur_result2. slow & fast runner: slow-> fast->->3. left & right boundary or index: left-> <-right4. p1 & p2 from two sequences: p1-> p2->5. start & end sliding window boundary: start-> end->'''# old & new state: old, new = new, cur_resultdefold_new_state(self,seq):# initialize stateold,new=default_val1,default_val2forelementinseq:''' process current element with old state '''old,new=new,self.process_logic(element,old)# slow & fast runner: slow-> fast->->defslow_fast_runner(self,seq):# initialize slow runnerslow=seq[0]# for index: slow = 0# fast-runner grows each iteration generallyforfastinrange(seq):# for index: range(len(seq))''' slow-runner grows with some restrictions '''ifself.slow_condition(slow):slow=slow.next# for index: slow += 1''' process logic before or after pointers movement '''self.process_logic(slow,fast)# left & right boundary or index: left-> <-rightdefleft_right_boundary(self,seq):left,right=0,len(seq)-1whileleft<right:''' left index moves when satisfy the condition '''ifself.left_condition(left):left+=1''' right index move when satisfy the condition '''ifself.right_condition(right):right-=1''' process logic before or after pointers movement '''self.process_logic(left,right)# p1 & p2 from two sequences: p1-> p2->defpointers_from_two_seq(self,seq1,seq2):# init pointersp1,p2=0,0# or seq1[0], seq2[0]# or other conditionwhilep1<len(seq1)andp2<len(seq2):''' p1 index moves when satisfy the condition '''ifself.p1_condition(p1):p1+=1# or p1 = next(seq1)''' p2 index move when satisfy the condition '''ifself.p2_condition(p2):p2+=1# or p2 = next(seq2)''' process logic before or after pointers movement '''self.process_logic(p1,p2)# start & end of sliding window: |start-> ... end->|# more details in sliding windows templates, here is just about two-pointers partdefstart_end_sliding_window(self,seq):start,end=0,0whileend<len(seq):# end grows in the outer loopend+=1# start grows with some restrictwhileself.start_condition(start):''' process logic before pointers movement '''self.process_logic1(start,end)# start grows in the inner loopstart+=1''' or process logic after pointers movement '''self.process_logic2(start,end)
快慢指针是处理linked list常用的套路,通常是用来判断成环以及环的入口,或者是寻找 list中第k个元素。
- Linked List Cycle
- Linked List Cycle II
- Palindrome Linked List
- Rotate List
- 剑指 Offer 18. 删除链表的节点JZ56 删除链表中重复的结点
- 剑指 Offer 22. 链表中倒数第k个节点
- 剑指 Offer 52. 两个链表的第一个公共节点
# a Linked list is a linear collection of data elements, whose order is not given by their physical placement in memory.# Instead, each element points to the next.## when operation with linked list, we can choose to change list node or change node value.# change node value is more easy-understanding, and may need extra space to store.## Time: O(1) to insert and delete, O(n) to random access# Space: O(n)# Definition for singly-linked list.classListNode:def__init__(self,x):self.val=xself.next=None# add dummy node to help flag the head, usually used in head may changed or merging None edge case.defdummy_node_assist(self,head):dummy=ListNode(0)cur=dummy.next=head# or cur = dummywhilecur:''' process current node logic '''self.process_logic(cur)returndummy.next# another solution is use self.next, more pythonicdefself_assist(self,head):pre,pre.next=self,headwhilepre.next:''' process current node logic '''self.process_logic(pre.next)returnself.next# add nodedefadd_node(pre_node,new_node):pre_node.next,new_node=new_node,pre_node.next# delete nodedefdelete_node(pre_node):pre_node.next=pre_node.next.next# reverse linked list iterativelydefreverse_iteratively(head:ListNode)->ListNode:prev,cur=None,headwhilecur:cur.next,cur,prev=prev,cur.next,curreturnprev# reverse linked list recursivelydefreverse_recursively(head:ListNode)->ListNode:defrecursive(cur,pre=None):ifnotcur:returnprepre,cur.next=cur.next,prereturnrecursive(pre,cur)returnrecursive(head)
- Palindrome Linked List
- Reverse Linked List
- Reverse Nodes in k-Group
- Reverse Linked List II
# a Linked list is a linear collection of data elements, whose order is not given by their physical placement in memory.# Instead, each element points to the next.## when operation with linked list, we can choose to change list node or change node value.# change node value is more easy-understanding, and may need extra space to store.## Time: O(1) to insert and delete, O(n) to random access# Space: O(n)# reverse linked list iterativelydefreverse_iteratively(head:ListNode)->ListNode:prev,cur=None,headwhilecur:cur.next,cur,prev=prev,cur.next,curreturnprev# reverse linked list recursivelydefreverse_recursively(head:ListNode)->ListNode:defrecursive(cur,pre=None):ifnotcur:returnprepre,cur.next=cur.next,prereturnrecursive(pre,cur)returnrecursive(head)
区间合并的问题,通常是重新把区间按照start和end排序,重新组合区间。
- Merge Intervals
- Interval List Intersections
- Insert Interval
todoMergeIntervalsalgorithmtemplate
要求 inplace, 通常是采用正负反转的做法
- First Missing Positive
- Find All Numbers Disappeared in an Array剑指 Offer 03. 数组中重复的数字
todo无序限定范围的数组元素查找O(N)algorithmtemplate
BFS 通常采用queue 来实现
- Binary Tree Level Order Traversal
- Binary Tree Zigzag Level Order Traversal
- Serialize and Deserialize Binary Tree
- Word Ladder I
- Course Schedule【拓扑排序】
# Breadth-first search is traversing or searching tree or graph data structures, including graph-like solution space.# it explores all of the neighbor nodes at the present depth prior to moving on to the nodes at the next depth level.## Time: O(V+E) V: vertex, E: edges# Space: O(V)fromcollectionsimportdeque# iteration version, using dequedefbfs_iteratively_by_queue(self,start,target=None):queue,visited=deque([start]), {start}whilequeue:node=queue.popleft()visited.add(node)''' process current node logic here '''self.process_logic(node)# target is optionalifnode==target:''' reach the goal and break out '''self.process_target_logic(target)breakfornext_nodeinnode.get_successors():ifnext_nodenotinvisited:queue.append(next_node)# iteration version, using list, pythonic-style# conciser but more memory, mainly used when you want to collect the whole listdefbfs_iteratively_by_list(self,start,target=None):node_list,visited= [start], {start}# append while traversingfornodeinnode_list:visited.add(node)''' process current node logic here '''self.process_logic(node)# target is optionalifnode==target:''' reach the goal and break out '''self.process_target_logic(target)breakfornext_nodeinnode.get_successors():ifnext_nodenotinvisited:node_list+=node# basically the node_list is useful herereturnnode_list# recursion version, uncommondefbfs_recursively(self,queue:deque,visited:set,target=None):ifnotqueue:returnnode=queue.popleft()visited.add(node)''' process current node logic here '''self.process_logic(node)# target is optionalifnode==target:''' reach the goal and break out '''self.process_target_logic(target)returnfornext_nodeinnode.get_successors():ifnext_nodenotinvisited:queue.append(next_node)self.bfs_recursively(queue,visited)# bfs list comprehension in row of binary treedefbfs_row(self,root):row= [root]whilerow:''' process current node logic here '''# process logic separatelyrow= [childfornodeinrowforchildin (node.left,node.right)ifnode]
通常采用递归 111. Minimum Depth of Binary Tree
- Path Sum
- Path Sum II(和剑指 Offer 34. 二叉树中和为某一值的路径一样)
- Path Sum III
- Same Tree
- Symmetric Tree
- Maximum Depth of Binary Tree
- Balanced Binary Tree
- 剑指 Offer 26. 树的子结构
- 剑指 Offer 33. 二叉搜索树的后序遍历序列
- 剑指 Offer 54. 二叉搜索树的第k大节点(inorder)
# Deep-first search is traversing or searching tree or graph data structures, including graph-like solution space.# it starts at the root node and explores as far as possible along each branch before backtracking.## Time: O(V+E) V: vertex, E: edges# Space: O(V)# recursion versiondefdfs_recursively(self,node,visited:set):visited.add(node)''' process current node logic here '''self.process_logic(node)fornext_nodeinnode.get_successors():ifnext_nodenotinvisited:self.dfs_recursively(next_node,visited)# iteration version, uncommondefdfs_iteratively(self,root):stack,visited= [root],set()whilestack:node=stack.pop()visited.add(node)''' process current node logic here '''self.process_logic(node)fornext_nodeinnode.get_successors():ifnext_nodenotinvisited:stack.append(next_node)
对于排列和组合的题目,需要主要判断是否会有重复数字,如有重复,需要先进行sort,而且需要进行剪枝。
- Subsets
- Subsets II
- Permutations
- Permutations II
- Combination Sum
- Coin Change
- Coin Change 2
- Combination Sum II
- Palindrome Partitioning !
- Letter Combinations of a Phone Number (differ from 91. Decode Ways)
- Word Search(same as 剑指 Offer 12. 矩阵中的路径)
- 剑指 Offer 13. 机器人的运动范围
- 双堆模式295 Find-Median-from-Data-Stream
- Sliding Window Median
- Min Stack
- 剑指 Offer 09. 用两个栈实现队列
# Backtracking is a general algorithm for finding all (or some) solutions to some computational problems, notably# constraint satisfaction problems, that incrementally builds candidates to the solutions, and abandons a candidate# ("backtracks") as soon as it determines that the candidate cannot possibly be completed to a valid solution.## backtracking vs. dfs# traverse in solution space vs. traverse in data structure space, pruned of dfsdefbacktracking(self,data,candidate):# pruningifself.reject(data,candidate):return# reach the endifself.accept(data,candidate):returnself.output(data,candidate)# drill downforcur_candidateinself.all_extension(data,candidate):# or you can choose to prune here, recursion depth - 1ifnotself.should_to_be_pruned(cur_candidate):self.backtracking(data,cur_candidate)
当你需要解决的问题的输入是排好序的数组,链表,或是排好序的矩阵,要求咱们寻找某些特定元素。这个时候的不二选择就是二分搜索。
- Search Insert Position
- Find First and Last Position of Element in Sorted Array
- Search in Rotated Sorted Array
- Find Minimum in Rotated Sorted Array
- Find Minimum in Rotated Sorted Array II(same as [剑指 Offer 11. 旋转数组的最小数字])
- Find Peak Element
- Single Element in a Sorted Array
- 剑指 Offer 16. 数值的整数次方(2分法)
# binary search requires sorted iterator. Common variation is find left-most or right-most index.## Time: O(log(n))# Space: O(1)# [lo, hi] versiondefbinary_search(arr,target):lo,hi=0,len(arr)-1whilelo<=hi:# no overflow problem in python, (lo + hi) // 2 is better.# mid = lo + (hi - lo) // 2mid= (lo+hi)//2''' change to your comparison condition as you need '''# find the targetifarr[mid]==target:breakelifarr[mid]<target:lo=mid+1else:hi=mid-1# [lo, hi) versiondefbinary_search2(arr,target):lo,hi=0,len(arr)whilelo<hi:mid= (lo+hi)//2# find the targetifarr[mid]==target:breakelifarr[mid]<target:lo=mid+1else:hi=mid# result in [0, hi]defbisect_left(arr,target,lo,hi):whilelo<hi:mid= (lo+hi)//2# left-most, so equal will be on the right sideifarr[mid]<target:lo=mid+1else:hi=mid''' # bisect right code if arr[mid] > target: hi = mid else: lo = mid + 1 '''returnlo
采用priority queue 或者 说在python 中的heapq 求top k 采用最小堆(默认) 采用最大堆的时候可以采用push 负的value
- Kth Largest Element in an Array
- Top K Frequent Elements
- Find K Pairs with Smallest Sums
# heap, also called priority queue# heap common operations: heapify, top, heappush, heappop, heappushpop, heapreplace, _siftup/_siftdown,# nlargest/nsmallest, merge# heapq in Python, there is only min heap, if you want to a max heap, you should reverse the key or implement __lt__.## Time: O(1) to find, O(log(n)) to push/pop/sift, O(nlog(n)) to heapify, O(n) to merge# Space: O(n)## from Queue import PriorityQueue is alternative way, which is a thread-safe classimportheapqdefheap_operations():heap= [4,2,1,3]# heapifyheapq.heapify(heap)# toptop=heap[0]# heappoptop=heapq.heappop(heap)# heappushheapq.heappush(heap,5)# heappushpop = push + popheapq.heappushpop(heap,0)# heapreplace = pop + pushheapq.heapreplace(heap,0)data= [10,5,18,2,37,3,8,7,19,1]heapq.heapify(data)old,new=8,22# increase the 8 to 22i=data.index(old)data[i]=new# _siftup, from root to leaf, when increaseheapq._siftup(data,i)old,new=10,4# decrease the 10 to 4i=data.index(old)data[i]=new# _siftdown, from leaf to root, when decreaseheapq._siftdown(data,0,i)# find n largest by queueheapq.nlargest(data,3)# find n smallest by queueheapq.nsmallest(data,3)# Merge multiple sorted inputs into a single sorted output# e.g. merge timestamped entries from multiple log filesheapq.merge([1,3,5,7], [0,2,4,8], [5,10,15,20], [], [25])
K路归并能帮咱们解决那些涉及到多组排好序的数组的问题。
- Merge k Sorted Lists
- Merge Two Sorted Lists
todoK路归并algorithmtemplate
- Longest Increasing Subsequence
- Longest Common Subsequence
- Edit Distance
- Wildcard Matching
- Regular Expression Matching
- Triangle
- Maximum Subarray
- Maximum Product Subarray
- Super Egg Dropref
- House Robber
- House Robber II (两个dp)
- Best Time to Buy and Sell Stock
- Best Time to Buy and Sell Stock II
- Best Time to Buy and Sell Stock IV
- Best Time to Buy and Sell Stock III ref
- Best Time to Buy and Sell Stock with Transaction Fee
- Best Time to Buy and Sell Stock with Cooldown
- Longest Palindromic Subsequence !
- Longest Palindromic Substring
- Partition Equal Subset Sum
- Coin Change
- Coin Change 2
- Decode Ways
- Word Break
- 剑指 Offer 10- I. 斐波那契数列
- 剑指 Offer 10- II. 青蛙跳台阶问题矩形覆盖变态跳台阶
- 剑指 Offer 14- I. 剪绳子
- 剑指 Offer 46. 把数字翻译成字符串
- 剑指 Offer 47. 礼物的最大价值
- 剑指 Offer 49. 丑数
- 剑指 Offer 60. n个骰子的点数
# simplifying a complicated problem by breaking it down into simpler sub-problems in a recursive manner# dynamic programming = recursion + memorized# state definition, state transition equation, optimal substructure# direction: bottom-up or top-downdefdynamic_programming_template_with_example(word1,word2):m,n=len(word1),len(word2)# states definition: cur_min_edit_dist# states compressed to two states: old and newdp= [[0]* (m+1)for_inrange(2)]# initialize the initial edit distance, add one more state for init stateforiinrange(0,m+1):dp[0][i]=icur=1foriinrange(n):# initialize the init statedp[cur][0]=i+1forjinrange(m):# state transition equation# if char matched, this is the min dist.ifword1[j]==word2[i]:dp[cur][j+1]=dp[cur^1][j]# otherwise, 1 + minimum of edit/remove/add operationselse:dp[cur][j+1]=1+min(dp[cur^1][j],dp[cur^1][j+1],dp[cur][j])# switch between two statescur^=1# return the last state as resultreturndp[cur^1][-1]
- Selection Sort
- Heapsort
- Mergesort
- Insertion Sort
- Shell's Sort
- Quicksort
- Bubblesort
- Linear Sorting
# all kinds of sort algorithm, just some common versions to show its idea.# here I unify the api as xxx_sort(arr), changed in-place## currently include:# quick, merge, insert, bubble, selection, heap, shell, bucket, counting, radix, topological## constant space vs extra space (merge O(n), counting O(k), bucket O(n+k), radix O(n+k))## in place vs out place (merge, counting, bucket, radix)## stable vs unstable (selection, quick, heap, shell)## comparison based vs non-comparison based (radix, bucket, counting)## comparison of counting, bucket and radix sort: all use bucket idea# counting sort: store the single key in bucket# bucket sort: store a range in bucket# radix sort: store each part of element in bucket# sort average best worst space place stable comparison# bubble O(n^2) O(n) O(n^2) O(1) in-place stable comparison# selection O(n^2) O(n^2) O(n^2) O(1) in-place unstable comparison# insert O(n^2) O(n) O(n^2) O(1) in-place stable comparison# shell O(nlogn) O(nlogn^2) O(nlogn^2) O(1) in-place unstable comparison# merge O(nlogn) O(nlogn) O(nlogn) O(n) out-place stable comparison# quick O(nlogn) O(nlogn) O(n^2) O(logn) in-place unstable comparison# heap O(nlogn) O(nlogn) O(nlogn) O(1) in-place unstable comparison# counting O(n+k) O(n+k) O(n+k) O(k) out-place stable non-comparison# bucket O(n+k) O(n+k) O(n^2) O(n+k) out-place stable non-comparison# radix O(nk) O(nk) O(nk) O(n+k) out-place stable non-comparisonimportrandomimporttimefromcollectionsimportdequefromcollectionsimportdefaultdict'''quick sortavg: O(nlogn), best: O(nlogn), worst: O(n^2), space: O(logn), in-place, unstable, comparisonfastest in large-scale and out-of-order data, divide & conquer'''defquick_sort(arr):quick_sort_rec(arr,0,len(arr)-1)# hi is included, in range [lo, hi]defquick_sort_rec(arr,lo,hi):iflo<hi:pivot=partition(arr,lo,hi)quick_sort_rec(arr,lo,pivot-1)quick_sort_rec(arr,pivot+1,hi)defpartition(arr,lo,hi):# choose pivot by median-of-threex,idx=sorted(((arr[lo],lo), (arr[hi],hi), (arr[lo+hi>>1],lo+hi>>1)))[1]arr[lo],arr[idx]=arr[idx],arr[lo]whilelo<hi:whilelo<hiandarr[hi]>=x:hi-=1arr[lo]=arr[hi]whilelo<hiandarr[lo]<=x:lo+=1arr[hi]=arr[lo]arr[lo]=xreturnlo'''merge sortavg: O(nlogn), best: O(nlogn), worst: O(nlogn), space: O(n), out-place, stable, comparisondivide & conquer'''# the version with a fixed temp arraydefmerge_sort(arr):merge_sort_rec(arr,0,len(arr)-1, [0]*len(arr))defmerge_sort_rec(arr,first,last,temp):iffirst<last:mid= (first+last)//2merge_sort_rec(arr,first,mid,temp)merge_sort_rec(arr,mid+1,last,temp)merge(arr,first,mid,last,temp)defmerge(arr,first,mid,last,temp):i,j=first,mid+1m,n=mid,lastk=0whilei<=mandj<=n:ifarr[i]<=arr[j]:temp[k]=arr[i]i+=1else:temp[k]=arr[j]j+=1k+=1whilei<=m:temp[k]=arr[i]i+=1k+=1whilej<=n:temp[k]=arr[j]j+=1k+=1foriinrange(k):arr[first+i]=temp[i]defmerge_sort2(arr):res=merge_sort_rec2(arr)foriinrange(len(arr)):arr[i]=res[i]defmerge_sort_rec2(arr):iflen(arr)<=1:returnarrmid=len(arr)//2left=merge_sort_rec2(arr[:mid])right=merge_sort_rec2(arr[mid:])returnmerge1(left,right)defmerge1(left,right):res= []i=j=0whilei<len(left)andj<len(right):ifleft[i]<=right[j]:res.append(left[i])i+=1else:res.append(right[j])j+=1whilei<len(left):res.append(left[i])i+=1whilej<len(right):res.append(right[j])j+=1returnres# more pythonic but slowerdefmerge2(left,right):res= []whileleftandright:ifleft[0]<=right[0]:res.append(left.pop(0))else:res.append(right.pop(0))returnres+ (leftorright)# slowestdefmerge3(left,right):res= []whileleftandright:ifleft[-1]>right[-1]:res.insert(0,left.pop())else:res.insert(0,right.pop())return (leftorright)+res'''insert sortavg: O(n^2), best: O(n), worst: O(n^2), space: O(1), in-place, stable, comparisonfast in small-scale and almost sorted data'''definsert_sort(arr):foriinrange(1,len(arr)):x=arr[i]j=i-1whilej>=0andarr[j]>x:arr[j+1]=arr[j]j=j-1arr[j+1]=x'''bubble sortavg: O(n^2), best:O(n), worst: O(n^2), space:O(1), in-place, stable, comparisonoptimization:1. flag whether swap last round, if not, end sort2. flag the last swap place, [last_swap, j] has been sorted, just skip it.'''# bubble the max to right mostdefbubble_sort(arr):foriinrange(len(arr)-1):forjinrange(len(arr)-i-1):ifarr[j]>arr[j+1]:arr[j],arr[j+1]=arr[j+1],arr[j]# optimizationdefbubble_sort2(arr):i=len(arr)-1whilei>0:last_swap=0forjinrange(i):ifarr[j]>arr[j+1]:arr[j],arr[j+1]=arr[j+1],arr[j]last_swap=j# if last_swap=0, it means no swap in last round, end sort# [last_swap, i] has been sorted, start from last_swapi=last_swap'''selection sortavg: O(n^2), best: O(n^2), worst: O(n^2), space: O(1), in-place, unstable, comparisonmost stable in time cost, always O(n^2), and easy understanding, used in small scale data'''defselection_sort(arr):foriinrange(len(arr)):min_i=iforjinrange(i+1,len(arr)):ifarr[j]<arr[min_i]:min_i=jarr[i],arr[min_i]=arr[min_i],arr[i]'''heap sortavg: O(nlogn), best: O(nlogn), worst: O(nlogn), space: O(1), in-place, unstable, comparisonnot only a sort algorithm, this structure (priority queue) can do more thing.'''defheap_sort(arr):# build max heapforiinrange(len(arr)//2)[::-1]:heap_adjust(arr,i,len(arr))# adjust from last elementforiinrange(1,len(arr))[::-1]:# swap first with the last, make the right most is maximumarr[0],arr[i]=arr[i],arr[0]heap_adjust(arr,0,i)defheap_adjust(arr,i,n):cur=arr[i]while2*i+1<n:# get child index in heapchild=2*i+1# choose the larger childifchild<n-1andarr[child+1]>arr[child]:child+=1# if child is larger than parent, sift upifcur<arr[child]:arr[i],arr[child]=arr[child],curi=childelse:break'''shell sortavg: O(nlogn), best: O(nlogn^2), worst: O(nlogn^2), space: O(1), in-place, unstable, comparisonimprovement of insertion sort'''defshell_sort(arr):# Shell sort using Shell's (original) gap sequence: n/2, n/4, ..., 1.gap=len(arr)//2# loop over the gapswhilegap>0:# do the insertion sortforiinrange(gap,len(arr)):val=arr[i]j=iwhilej>=gapandarr[j-gap]>val:arr[j]=arr[j-gap]j-=gaparr[j]=valgap//=2'''counting sortavg: O(n+k), best:O(n+k), worst:O(n+k), space:O(k), out-place, stable, non-comparisonrelatively concentrated values'''defcounting_sort(arr):min_val,max_val=min(arr),max(arr)size=max_val-min_val+1counter= [0]*sizeforiinrange(len(arr)):counter[arr[i]-min_val]+=1idx=0fori,vinenumerate(counter):# use slice assignmentarr[idx:idx+v]= [i+min_val]*vidx+=v'''bucket sortavg: O(n+k), best:O(n+k), worst:O(n^2), space:O(n+k), out-place, stable, non-comparisonimprovement of counting sort, usually used with hash'''DEFAULT_BUCKET_SIZE=5defbucket_sort(arr,size=DEFAULT_BUCKET_SIZE):min_val,max_val=min(arr),max(arr)# initialize bucketscount= (max_val-min_val)//size+1buckets= [[]for_inrange(count)]# put values in bucketsforiinrange(len(arr)):buckets[(arr[i]-min_val)//size].append(arr[i])# sort buckets and place back into input arrayi=0forbucketinbuckets:insert_sort(bucket)# use slice assignmentarr[i:i+len(bucket)]=bucketi+=len(bucket)# with hashdefbucket_sort2(arr):# get hash codescode=hashing(arr)buckets= [[]for_inrange(code[1])]# distribute data into buckets: O(n)foriinarr:x=re_hashing(i,code)buckets[x].append(i)i=0# merge the buckets: O(n)forbucketinbuckets:insert_sort(bucket)arr[i:i+len(bucket)]=bucketi+=len(bucket)defhashing(arr):return [max(arr),int(len(arr)**0.5)]defre_hashing(i,code):returnint(i/code[0]* (code[1]-1))'''radix sortavg: O(nk), best:O(nk), worst:O(nk), space:O(n+k), out-place, stable, non-comparisonimprovement of counting sort'''defradix_sort(arr):radix=10max_length=Falseplacement=1whilenotmax_length:max_length=True# declare and initialize bucketsbuckets= [[]for_inrange(radix)]# split arr between listsforiinarr:temp=i//placementbuckets[temp%radix].append(i)ifmax_lengthandtemp>0:max_length=False# assign from bucket to arri=0forbucketinbuckets:insert_sort(bucket)# use slice assignmentarr[i:i+len(bucket)]=bucketi+=len(bucket)# move to next digitplacement*=radixreturnarr'''topological sortin a directed graph, a linear ordering of its vertices such that for every directed edge uv from vertex u to vertex v,u comes before v in the ordering.'''GRAY,BLACK=0,1deftopological_sort(graph):order,enter,state=deque(),set(graph), {}defdfs(node):state[node]=GRAYforkingraph.get(node, ()):sk=state.get(k,None)ifsk==GRAY:raiseValueError("cycle")ifsk==BLACK:continueenter.discard(k)dfs(k)order.appendleft(node)state[node]=BLACKwhileenter:dfs(enter.pop())returnorderif__name__=='__main__':defsort_test(sort_func):start=time.time()for_inrange(100):nums= [random.randrange(1,250)for_inrange(1000)]nums1=sorted(nums)sort_func(nums)ifnums1!=nums:print('incorrect', )end=time.time()print('{:15s} time: {}'.format(sort_func.__name__,end-start))sort_test(quick_sort)sort_test(merge_sort)sort_test(merge_sort2)sort_test(heap_sort)sort_test(shell_sort)sort_test(counting_sort)sort_test(bucket_sort)sort_test(bucket_sort2)sort_test(radix_sort)# put turtle algorithms to the tailsort_test(insert_sort)sort_test(bubble_sort)sort_test(bubble_sort2)sort_test(selection_sort)graph=defaultdict(list)graph['A'].append('B')graph['B'].append('D')graph['C'].append('A')print(topological_sort(graph))
- 二叉搜索树与双向链表
- Convert Sorted List to Binary Search Tree
- Flatten Binary Tree to Linked List
# Classification: binary tree, complete binary tree, full binary tree, binary search tree, AVL tree(self-balancing)## Time: O(n)# Space: O(h) h: height of treefromcollectionsimportdeque# Definition for a binary tree nodeclassTreeNode:def__init__(self,x):self.val=xself.left=Noneself.right=None'''traverse binary tree recursively'''# pre-order: root->left->rightdefpreorder_traversal_recursively(self,root:'TreeNode'):# recursion terminator here# you can check if none when add left and right child, it will decrease one recursion depth,# but you have to check whether root is None outside.ifnotroot:return''' add current node logic here '''self.process_logic(root)self.preorder_traversal_recursively(root.left)self.preorder_traversal_recursively(root.right)# in-order: left->root->rightdefinorder_traversal_recursively(self,root:'TreeNode'):ifnotroot:returnself.inorder_traversal_recursively(root.left)''' add current node logic here '''self.process_logic(root)self.inorder_traversal_recursively(root.right)# post-order: left->right->rootdefpostorder_traversal_recursively(self,root:'TreeNode'):ifnotroot:returnself.postorder_traversal_recursively(root.left)self.postorder_traversal_recursively(root.right)''' add current node logic here '''self.process_logic(root)# level-order# to traverse recursively, need help from extra data structure or dfs level by leveldeflevel_order_traversal_recursively(self,root:'TreeNode')->'List[List[int]]':res= []defdfs(root,level):ifnotroot:returniflen(res)<level+1:res.append([])''' add current node logic here '''self.process_logic(root)res[level].append(root.val)dfs(root.left,level+1)dfs(root.right,level+1)dfs(root,0)returnres'''traverse binary tree iteratively'''# There are too many version to traverse iteratively, just choose the one you like it.# pre-order: root->left->rightdefpreorder_traversal_iteratively(self,root:'TreeNode'):ifnotroot:return []stack= [root]whilestack:root=stack.pop()''' add current node logic here '''self.process_logic(root)# push right child first because of FILOifroot.right:stack.append(root.right)ifroot.left:stack.append(root.left)# in-order: left->root->rightdefinorder_traversal_iteratively(self,root:'TreeNode'):stack= []# keep stack empty and compare root too, compatible with edge case: root=Nonewhilestackorroot:# push itself and all left children into stack iterativelywhileroot:stack.append(root)root=root.leftroot=stack.pop()''' add current node logic here '''self.process_logic(root)# point to right childroot=root.right# here I choose to not use# post-order: left->right->rootdefpostorder_traversal_iteratively(self,root:'TreeNode'):ifnotroot:return []stack= [root]# used to record whether left or right child has been visitedlast=Nonewhilestack:root=stack[-1]# if current node has no left right child, or left child or right child has been visited, then process and pop itifnotroot.leftandnotroot.rightorlastand (root.left==lastorroot.right==last):''' add current node logic here '''self.process_logic(root)stack.pop()last=root# if not, push right and left child in stackelse:# push right first because of FILOifroot.right:stack.append(root.right)ifroot.left:stack.append(root.left)# post-order: left->right->root# use visit flagdefpostorder_traversal_iteratively2(self,root:'TreeNode'):ifnotroot:return []stack= [root]whilestack:root=stack[-1]# use visited attribute to judge whether it has been visitedifhasattr(root,'visited'):''' add current node logic here '''self.process_logic(root)stack.pop()delroot.visitedelse:ifroot.right:stack.append(root.right)ifroot.left:stack.append(root.left)root.visited=True# level-orderdeflevel_order_traversal_iteratively(self,root:'TreeNode'):ifnotroot:return []queue=deque([root])whilequeue:for_inrange(len(queue)):cur=queue.popleft()''' add current node logic here '''self.process_logic(cur)ifcur.left:queue.append(cur.left)ifcur.right:queue.append(cur.right)''' add level logic here if you need '''
- Construct Binary Tree from Preorder and Inorder Traversal
- Construct Binary Tree from Inorder and Postorder Traversal
- Construct String from Binary Tree
- Construct Binary Search Tree from Preorder Traversal
- Construct Binary Tree from Preorder and Postorder Traversal
相关算法模板同上树和链表结合
- Single Number
- Single Element in a Sorted Array
- Reverse Bits
- 剑指 Offer 15. 二进制中1的个数
- 剑指 Offer 56 - I. 数组中数字出现的次数
- 剑指 Offer 56 - II. 数组中数字出现的次数 II
# Bit manipulation is the act of algorithmically manipulating bits or other pieces of data shorter than a word.## common bit-wise operation## operations priority:# {}[]() -> ** -> ~ -> -x -> *,/,% -> +,- -> <<,>> -> & -> ^ -> | -> <>!= -> is -> in -> not x -> and -> ordefbit_wise_operations(a,b):# not~a# ora|b# anda&b# xora^b# shift operatorsa<<ba>>b# subtractiona&~b# set bit, assign to 1a|=1<<b# clear bit, assign to 0a&=~(1<<b)# test bitifa&1<<b:pass# extract last bita&-a# remove last bita& (a-1)# check is odd or evenifa&1:print('odd')# clear right n bita& (~0<<b)# clear left until to na& ((1<<b)-1)# reference# https://leetcode.com/problems/sum-of-two-integers/discuss/84278/A-summary%3A-how-to-use-bit-manipulation-to-solve-problems-easily-and-efficiently
一般都有很多corner cases 需要考虑8. String to Integer (atoi)
- 剑指 Offer 20. 表示数值的字符串
- 剑指 Offer 58 - I. 翻转单词顺序(2次翻转)
- 剑指 Offer 58 - II. 左旋转字符串
# string is traditionally a sequence of characters, either as a literal constant or as some kind of variable.importstringdefstring_operations():s='abcab'# join','.join(s)# splits.split(',')# replaces.replace()# index & find, index return -1 if not founds.index('a')s.find('a')s.rfind('a')# counts.count('a')# start & end withs.startswith('a')s.endswith('b')# translateintab="aeiou"outtab="12345"trantab=str.maketrans(intab,outtab)s.translate(trantab)# strips.lstrip()s.rstrip()s.strip()# justs.ljust(10)s.rjust(10)s.center(10)s.zfill(10)# common stringstring.punctuationstring.whitespacestring.ascii_lowercasestring.hexdigitsstring.printable
- 剑指 Offer 31. 栈的压入、弹出序列
# stack common operation: push, pop, top# stack is used in pairs, maintain extreme value## FILO: First In, Last Out# Time: O(1)# Space: O(n)# sequence stack based on listdefstack_operations():# initializationstack= []# size of stacksize=len(stack)# pushstack.append(1)# check is emptyifstack:# toptop=stack[-1]# popstack.pop()
- 剑指 Offer 66. 构建乘积数组
# list is a collection which is ordered and changeable, with continuous space.## Time: O(1) to index or write or append, O(n) to insert or remove# Space: O(n)deflist_operations():# initializationlist1= [3,1,2,4]list2=list(range(5))# [*X] equals to list(X)list2= [*range(5)]# appendlist1.append(5)list1+= [5]list1+=5,list1.extend([5,6])# insertlist1.insert(0)# indexlist1.index(3)# countlist1.count(3)# removelist1.remove(3)# sortlist1.sort(reverse=True)# reverselist1.reverse()
- 剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
- 剑指 Offer 68 - II. 二叉树的最近公共祖先
- 二叉树的下一个结点
# binary search requires sorted iterator. Common variation is find left-most or right-most index.## Time: O(log(n))# Space: O(1)# [lo, hi] versiondefbinary_search(arr,target):lo,hi=0,len(arr)-1whilelo<=hi:# no overflow problem in python, (lo + hi) // 2 is better.# mid = lo + (hi - lo) // 2mid= (lo+hi)//2''' change to your comparison condition as you need '''# find the targetifarr[mid]==target:breakelifarr[mid]<target:lo=mid+1else:hi=mid-1# [lo, hi) versiondefbinary_search2(arr,target):lo,hi=0,len(arr)whilelo<hi:mid= (lo+hi)//2# find the targetifarr[mid]==target:breakelifarr[mid]<target:lo=mid+1else:hi=mid# result in [0, hi]defbisect_left(arr,target,lo,hi):whilelo<hi:mid= (lo+hi)//2# left-most, so equal will be on the right sideifarr[mid]<target:lo=mid+1else:hi=mid''' # bisect right code if arr[mid] > target: hi = mid else: lo = mid + 1 '''returnlo
- 算法图解.pdf百度云下载链接 密码:lk0v
- 算法第四版.pdf百度云下载链接 密码:gsjc
- 算法导论第三版.pdf百度云下载链接 密码:qans
- 数据结构与算法经典问题解析Java语言描述.pdf百度云下载链接 密码:m7ef
- 数据结构与算法分析:C语言描述_原书第2版.pdf百度云下载链接 密码:1w5g
- 大话数据结构.pdf百度云下载链接 密码:h5du
- 编程之美——微软技术面试心得.pdf百度云下载链接 密码:rcpv
- 编程之法.pdf百度云下载链接 密码:0cv3
- 背包九讲.pdf百度云下载链接 密码:he90
- 啊哈算法.pdf百度云下载链接 密码:h89a
- Algorithms, 4th Edition(算法,第四版).pdf百度云下载链接 密码:ipni
- 《LeetCode101(谷歌师兄刷题笔记)》百度网盘链接 密码: 14fn
- 《第二份谷歌刷题笔记》百度网盘链接 密码: k70j
- 阿里霜神-《LeetCode刷题手册》百度网盘链接 密码: fwtn
如果本仓库对你有帮助,可以请作者喝杯速溶咖啡,给大家推荐个Google大佬的算法课程。
About
python 数据结构与算法 leetcode 算法题与书籍 刷算法全靠套路与总结!Crack LeetCode, not only how, but also why.
Topics
Resources
License
Uh oh!
There was an error while loading.Please reload this page.