
Fuchsia trace format
This document describes the binary format used to collect, store, andtransmit Fuchsia trace records.You can use this document to search for detailed informationabout each field in the Fuchsia trace format.
Note: For information about the Fuchsia tracing system,seeFuchsia tracing system.Overview
While a trace is running, trace providers write records into a trace bufferVMO shared with the trace manager using the binary format described in thisdocument.
The binary format is designed to introduce minimal impact upon theperformance of the subject under trace while writing traces. The recordsare also written sequentially so that if a trace terminates (normally orabnormally), the trace manager can still recover partial trace data alreadystored in the trace buffer by reading everything up to the last well-formedrecord.
As the trace progresses, the trace manager aggregates records from alltrace providers participating in trace collection, and concatenatesthem together with some special metadata records to form a trace archive.
Once the trace completes, tools such as thetrace command-line programcan read the trace records within the trace archive to visualize the resultsor save them to a file for later consumption. Trace archives can also bevisualized using thePerfetto UI.
Features
- Small footprint
- Trace records are compact, packing information into a small number of bits.
- Pooling strings, processes, and threads further compacts the trace data.
- Memory aligned
- Trace records maintain an 8 byte alignment in memory to facilitatewriting them directly into memory mapped VMOs.
- Variable size records
- Overall record size is limited to 32 KB.
- Large objects may need to be broken up into multiple records.
- Extensible
- There's room to define new record types as needed.
- Unrecognized or malformed trace records can be skipped.
Encoding primitives
The Fuchsia trace format has the following encoding primitives:
- Atoms
- Records
- Archives
- Timestamps
- String references
- Thread references
- Userspace object information
- Kernel object information
- Arguments
Atoms
Each record is constructed as a sequence of atoms.
Each atom is written with 8 byte alignment and has a size that is also amultiple of 8 bytes so as to preserve alignment.
There are two kinds of atoms:
- Word: A 64-bit value that may be further subdivided into bit fields.Words are stored in machine word order (little-endian on all currentlysupported architectures).
- Stream: A sequence of bytes padded with zeros to the next 8 byteboundary. Streams are stored in byte order. Streams that are an exactmultiple of 8 bytes long are not padded (there is no zero terminator).
Fields are subdivisions of 64-bitWords, denoted[<least significant bit> .. <most significant bit>] where the first andlast bit positions are inclusive. All unused bits are reserved for futureuse and must be set to 0.
Words andFields store unsigned integers unless otherwise specifiedby the record format.
Streams may store either UTF-8 strings or binary data, as specified bythe record format.
Records
A trace record is a binary encoded piece of trace information consisting ofa sequence ofatoms.
All records include a header word that contains the following basicinformation:
- Record type: A 4-bit field that identifies the type of the recordand the information it contains. SeeRecord Types.
- Record size: Typically, a 12-bit field that indicates the number of words(multiples of 8 byte units) within the recordincluding the recordheader itself. The maximum possible size of a record is 4095 words(32760 bytes). Very simple records may be just 1 word (8 bytes) long.Large records use a 32-bit size field and therefore have a highermaximum size.
Records are always a multiple of 8 bytes in length and are stored with8 byte alignment.
Archives
A trace archive is a sequence of trace records, concatenated end to end,which stores information collected by trace providers while a trace isrunning together with metadata records that identify and delimit sectionsof the trace produced by each trace provider.
Trace archives are intended to be read sequentially since records thatappear earlier in the trace may influence the interpretation of recordswhich appear later in the trace. Examples of records that affect subsequent recordsin the archive areString references andThread references.
Event records which have timestamps associated with them are not guaranteed to bein timestamp order. Some record types such asFlow eventsrequire processing events in timestamp order, therefore programs processingtrace data should sort events by timestamp before processing.
The trace system provides tools forextracting information from trace archives and converting it into otherforms for visualization.
Timestamps
Timestamps are represented as 64-bit ticks derived from a hardware counter.The trace initialization record describes the number of ticks per secondof real time.
By default, we assume that 1 tick equals 1 nanosecond.
String references
Strings are encoded asString Refs which are 16-bit values of thefollowing form:
- Empty strings: Value is zero.
- Indexed strings: Most significant bit is zero. The lower 15 bitsdenote an index in thestring table which was previously assigned using aString record.
- Inline strings: Most significant bit is one. The lower 15 bitsdenote the length of the string in bytes. The string's content appearsinline in another part of the record as specified by the record format.
To make traces more compact, frequently referenced strings, such as eventcategory and name constants, should be registered into thestring tableusingstring records then referenced by index.
There can be at most 32767 strings in the string table. If this limit isreached, additional strings can be encoded by replacing existing entriesor by encoding strings inline.
String content itself is stored as a UTF-8stream without termination.
The theoretical maximum length of a string is 32767 bytes but in practice thiswill be further reduced by the space required to store the rest of the recordwhich contains it, so we set a conservative maximum string length limit of32000 bytes.
Thread references
Thread and process kernel object ids (koids) are encoded asthread refswhich are 8-bit values of the following form:
- Inline threads: Value is zero. The thread and process koid appearsinline in another part of the record as specified by the record format.
- Indexed threads: Value is non-zero. The value denotes an index inthethread table which was previously assigned using athread record.
To make traces more compact, frequently referenced threads should be registeredinto thethread table usingthread records then referenced by index.
There can be at most 255 threads in the string table. If this limit isreached, additional threads can be encoded by replacing existing entriesor by encoding threads inline.
Userspace object information
Traces can include annotations about userspace objects (anything that can bereferenced using a pointer-like value such as a C++ or Dart object) in theform ofuserspace object records. Trace providers typically generatesuch records when the object is created.
Thereafter, anypointer arguments which refer to the same pointer willbe associated with the referent's annotations.
This makes it easy to associate human-readable labels and other informationwith objects that appear later in the trace.
Kernel object information
Traces can include annotations about kernel objects (anything that can bereferenced using a Zircon koid such as a process, channel, or event)form ofkernel object records. Trace providers typically generate suchrecords when the object is created.
Thereafter, anykernel object Id arguments which refer to the same koid willbe associated with the referent's annotations.
This makes it easy to associate human-readable labels and other informationwith objects that appear later in the trace.
In particular, this is how the tracing system associates names with processand thread koids.
Arguments
Arguments are typed key value pairs.
Many record types allow up to 15 arguments to be appended to the record toprovide additional information from the developer.
Arguments are size-prefixed like ordinary records so that unrecognizedargument types can be skipped.
For more information, seeArgument Types.
Extend the format
The trace format can be extended in the following ways:
Note: To preserve compatibility as the trace format evolves, all extensions must bedocumented authoritatively in this file. Currently there is no support forprivate extensions.- Defining new record types.
- Storing new information in reserved fields of existing record types.
- Appending new information to existing record types (the presence of thisinformation can be detected by examining the record's size and payload).
- Defining new argument types.
Record Types
There are the following record types:
Note: In the record format descriptions, each constituent atom is labeled in italicsfollowed by a bullet-point description of its contents.- Record header
- Large record header
- Metadata record (record type = 0)
- Initialization record (record type = 1)
- String record (record type = 2)
- Thread record (record type = 3)
- Event record (record type = 4)
- Blob record (record type = 5)
- Userspace object record (record type = 6)
- Kernel object record (record type = 7)
- Scheduling record (record type = 8)
- Log record (record type = 9)
- Large BLOB record (record type = 15, large type = 0)
Record header
All records include this header that specifies the record's type and sizetogether with 48 bits of data whose usage varies by record type.
Format
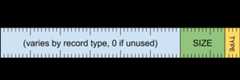
header word
[0 .. 3]: record type[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 63]: varies by record type (must be zero if unused)
Large record header
Provides support for records larger than 32KB. Large records have a32 bit size field rather than the normal 12 bits.
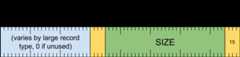
header word
[0 .. 3]: record type (15)[4 .. 35]: record size (inclusive of this word) as a multiple of 8 bytes[36 .. 39]: large record type[40 .. 63]: varies by large record type (must be zero if unused)
Metadata record (record type = 0)
Provides metadata about trace data that follows.
This record type is reserved for use by thetrace manager when generatingtrace archives. It must not be emitted by trace providers themselves.If the trace manager encounters ametadata record within a trace producedby a trace provider, it treats it as garbage and skips over it.
There are several metadata record subtypes, each of which contain differentinformation.
Format

header word
[0 .. 3]: record type (0)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: metadata type[20 .. 63]: varies by metadata type (must be zero if unused)
Provider info metadata (metadata type = 1)
This metadata identifies a trace provider that has contributed information tothe trace.
All data that follows until the nextprovider section metadata orprovider info metadata is encountered must have been collected from thesame provider.
Format

header word
[0 .. 3]: record type (0)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: metadata type (1)[20 .. 51]: provider id (token used to identify the provider in the trace)[52 .. 59]: name length in bytes[60 .. 63]: reserved (must be zero)
provider name stream
- UTF-8 string, padded with zeros to 8 byte alignment
Provider section metadata (metadata type = 2)
This metadata delimits sections of the trace that have been obtained fromdifferent providers.
All data that follows until the nextprovider section metadata orprovider info metadata is encountered is assumed to have been collectedfrom the same provider.
When reading a trace consisting of an accumulation of traces from differenttrace providers, the reader must maintain state separately for each provider'straces (such as the initialization data, string table, thread table,userspace object table, and kernel object table) and switch contextswhenever it encounters a newprovider section metadata record.
Format

header word
[0 .. 3]: record type (0)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: metadata type (2)[20 .. 51]: provider id (token used to identify the provider in the trace)[52 .. 63]: reserved (must be zero)
Provider event metadata (metadata type = 3)
This metadata provides running notification of events that the providerwants to report.
This record may appear anywhere in the output, and does not delimit whatcame before it or what comes after it.
Format

header word
[0 .. 3]: record type (0)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: metadata type (3)[20 .. 51]: provider id (token used to identify the provider in the trace)[52 .. 55]: the event id[56 .. 63]: reserved (must be zero)
Events
The following events are defined.
0: a buffer filled up, records were likely dropped
Trace info metadata (metadata type = 4)
This metadata provides information about the trace as a whole. This record isnot associated with a particular provider.
Format
header word
[0 .. 3]: record type (0)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: metadata type (4)[20 .. 23]: trace info type[24 .. 63]: varies by trace info type (must be zero if unused)
Magic number record (trace info type = 0)
This record serves as an indicator that the binary data is in the Fuchsiatracing format. Generally it should appear at the start of a trace. It carriesno other information. The magic number0x16547846 is the string "FxT"followed by a byte that was chosen at random.
To allow the first eight bytes of a trace to be treated together as a magicnumber without caring about the internal record structure, this record type isnot extensible. The record must not contain any words other than the headerword, and there are no reserved fields. As an eight byte number, the entirerecord has the value 0x0016547846040010.
Note that the byte order of that value, and all other words in the trace,depends on the endianness of the system that wrote the trace. For a littleendian system, the first eight bytes are 10 00 04 46 78 54 16 00. On a bigendian system, it will be the reverse: 00 16 54 78 46 04 00 10.
Format
header word
[0 .. 3]: record type (0)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes (1)[16 .. 19]: metadata type (4)[20 .. 23]: trace info type (0)[24 .. 55]: the magic number 0x16547846[56 .. 63]: zero
Initialization record (record type = 1)
Provides parameters needed to interpret the records that follow. In absenceof this record, the reader may assume that 1 tick is 1 nanosecond.
Format

header word
[0 .. 3]: record type (1)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 63]: reserved (must be zero)
tick multiplier word
[0 .. 63]: number of ticks per second
String record (record type = 2)
Registers a string in the string table, assigning it a string index in therange0x0001 to0x7fff. The registration replaces any prior registrationfor the given string index when interpreting the records that follow.
String records that attempt to set a value for string index0x0000 must beignored since this value is reserved to represent the empty string.
String records that contain empty strings must be tolerated but they'repointless since the empty string can simply be encoded as zero in a string ref.
Format

header word
[0 .. 3]: record type (2)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 30]: string index (range 0x0001 to 0x7fff)[31]: always zero (0)[32 .. 46]: string length in bytes (range 0x0000 to 0x7fff)[47]: always zero (0)[48 .. 63]: reserved (must be zero)
string value stream
- UTF-8 string, padded with zeros to 8 byte alignment
Thread record (record type = 3)
Registers a process id and thread id pair in the thread table, assigning it athread index in the range0x01 to0xff. The registration replaces anyprior registration for the given thread index when interpreting the recordswhich follow.
Thread index0x00 is reserved to denote the use of an inline thread id ina thread ref. Thread records that attempt to set a value for this valuemust be ignored.
Format

header word
[0 .. 3]: record type (3)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 23]: thread index (never 0x00)[24 .. 63]: reserved (must be zero)
process id word
[0 .. 63]: process koid (kernel object id)
thread id word
[0 .. 63]: thread koid (kernel object id)
Event record (record type = 4)
Describes a timestamped event.
This record consists of some basic information about the event includingwhen and where it happened followed by event arguments and event subtypespecific data.
Format

header word
[0 .. 3]: record type (4)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: event type[20 .. 23]: number of arguments[24 .. 31]: thread (thread ref)[32 .. 47]: category (string ref)[48 .. 63]: name (string ref)
timestamp word
[0 .. 63]: number of ticks
process id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
thread id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: thread koid (kernel object id)
category stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument data (repeats for each argument)
- (see below)
event-type specific data
- Can be any of the following:
- Instant event (event type = 0)
- Counter event (event type = 1)
- Duration begin event (event type = 2)
- Duration end event (event type = 3)
- Duration complete event (event type = 4)
- Async begin event (event type = 5)
- Async instant event (event type = 6)
- Async end event (event type = 7)
- Flow begin event (event type = 8)
- Flow step event (event type = 9)
- Flow end event (event type = 10)
Instant event (event type = 0)
Marks a moment in time on this thread. These are equivalent to Zirconkernel probes.
Format

No event-type specific data required.
Counter event (event type = 1)
Records sample values of each argument as data in a time series associatedwith the counter's name and id. The values may be presented graphically as astacked area chart.
Format

counter word
[0 .. 63]: counter id
Duration begin event (event type = 2)
Marks the beginning of an operation on a particular thread. Must be matchedby aduration end event. May be nested.
Format

No event-type specific data required.
Duration end event (event type = 3)
Marks the end of an operation on a particular thread.
Format
No event-type specific data required.
Duration complete event (event type = 4)
Marks the beginning and end of an operation on a particular thread.
Format

end time word
[0 .. 63]: end time number of ticks
Async begin event (event type = 5)
Marks the beginning of an operation that may span threads. Must be matchedby anasync end event using the same async correlation id.
Format

async correlation word
[0 .. 63]: async correlation id
Async instant Event (event type = 6)
Marks a moment within an operation that may span threads. Must appearbetweenasync begin event andasync end event using the same asynccorrelation id.
Format
async correlation word
[0 .. 63]: async correlation id
Async end event (event type = 7)
Marks the end of an operation that may span threads.
Format
async correlation word
[0 .. 63]: async correlation id
Flow begin event (event type = 8)
Marks the beginning of an operation, which results in a sequence of actionsthat may span multiple threads or abstraction layers. Must be matched by aflow end event using the same flow correlation id. This can be envisionedas an arrow between duration events.
The beginning of the flow is associated with the enclosing duration eventfor this thread; it begins where the enclosingduration event ends.
Format

flow correlation word
[0 .. 63]: flow correlation id
Flow step event (event type = 9)
Marks a point within a flow.
The step is associated with the enclosing duration event for this thread;the flow resumes where the enclosing duration event begins then is suspendedat the point where the enclosingduration event event ends.
Format
flow correlation word
[0 .. 63]: flow correlation id
Flow end event (event type = 10)
Marks the end of a flow.
The end of the flow is associated with the enclosing duration event for thisthread; the flow resumes where the enclosingduration event begins.
Format
flow correlation word
[0 .. 63]: flow correlation id
BLOB record (record type = 5)
Provides uninterpreted bulk data to be included in the trace. This can beuseful for embedding captured trace data in other formats.
The blob name uniquely identifies separate blob data streams within the trace.By writing multiple blob records with the same name, additional chunks ofdata can be appended to a previously created BLOB.
The BLOB type indicates the representation of the BLOB's content.
Format

header word
[0 .. 3]: record type (5)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: blob name (string ref)[32 .. 46]: blob payload size in bytes (excluding padding)[47 .. 47]: reserved (must be zero)[48 .. 55]: blob type[56 .. 63]: reserved (must be zero)
blob name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
payload stream (variable size)
- binary data, padded with zeros to 8 byte alignment
Blob types
The following blob types are defined:
TRACE_BLOB_TYPE_DATA=0x01: Raw untyped data. The consumer is expected to knowhow to consume it, perhaps based on context.TRACE_BLOB_TYPE_LAST_BRANCH=0x02: Last Branch Record of Intel Performance Monitor.The format is defined by the[CPU performancemonitor.TRACE_BLOB_TYPE_PERFETTO =0x03`: The blob contains data recorded from aPerfetto speaking component. The data is encoded inPerfetto's ProtoFormat.
Userspace object record (record type = 6)
Describes a userspace object, assigns it a label, and optionally associateskey/value data with it as arguments. Information about the object is addedto a per-process userspace object table.
When a trace consumer encounters an event with apointer argument whosevalue matches an entry in the process's object table, it can cross-referencethe argument's pointer value with a prioruserspace object record to find adescription of the referent.
Format

header word
[0 .. 3]: record type (6)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 23]: process (thread ref)[24 .. 39]: name (string ref)[40 .. 43]: number of arguments[44 .. 63]: reserved (must be zero)
pointer word
[0 .. 63]: pointer value
process id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument data (repeats for each argument)
- (see below)
Kernel object record (record type = 7)
Describes a kernel object, assigns it a label, and optionally associateskey/value data with it as arguments. Information about the object is addedto a global kernel object table.
When a trace consumer encounters an event with akoid argumentwhose value matches an entry in the kernel object table, it cancross-reference the argument's koid value with a priorkernel object recordto find a description of the referent.
Format

header word
[0 .. 3]: record type (7)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 23]: kernel object type (one of the ZX_OBJ_TYPE_XXX constants fromzircon/syscalls/types.h[24 .. 39]: name (string ref)[40 .. 43]: number of arguments[44 .. 63]: reserved (must be zero)
kernel object id word
[0 .. 63]: koid (kernel object id)
name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument data (repeats for each argument)
- (see below)
Argument Conventions
By convention, the trace writer should include the following named argumentswhen writing kernel object records about objects of particular types. Thishelps trace consumers correlate relationships among kernel objects.
Note: This information may not always be available."process": forZX_OBJ_TYPE_THREADobjects, specifies the koid of theprocess that contains the thread
Scheduling Record (record type = 8)
Describes a scheduling event such as when a thread was woken up, or a contextswitch from one thread to another.
Format
+---------(4)--------------+--------(48)--------+--(8)--+-(4)-+| scheduling record type | <type specific> | size | 8 |+--------------------------+--------------------+-------+-----+header word
[0 .. 3]: record type (8)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 59]: scheduling record type specific data[60 .. 63]: scheduling record type
Context Switch Record (scheduling event record type = 1)
Format
+-(4)-+----(20)---+--------(4)-------+----(16)---+-------(4)-------+----(8)--+-(4)-+| 1 | reserved | out thread state | cpu | argument count | size | 8 |+-----+-----------+------------------+-----------+-----------------+---------+-----++---------------------------(64)------------------------------+| timestamp |+-------------------------------------------------------------++---------------------------(64)------------------------------+| outgoing thread id |+-------------------------------------------------------------++---------------------------(64)------------------------------+| incoming thread id |+-------------------------------------------------------------++--------------------------(...)------------------------------+| argument data |+-------------------------------------------------------------+header word
[0 .. 3]: record type (8)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: argument count[20 .. 35]: cpu number[36 .. 39]: outgoing thread state[40 .. 59]: reserved[60 .. 63]: scheduling record type (1)
timestamp word
[0 .. 63]: number of ticks
outoing thread id
[0 .. 63]: thread koid (kernel object id)
incoming thread id
[0 .. 63]: thread koid (kernel object id)
argument data (repeats of each argument)
- (seeArguments for argument format)
Argument Conventions
By convention, the trace writer may also optionally include the following namedarguments when writing this record to provide additional information to traceconsumers.
"incoming_weight":Int32describing the relativeweight of the incomingthread"outgoing_weight":Int32describing the relative weight of the outgoingthread
Thread Wakeup Record (scheduling event record type = 2)
Format
+-(4)-+----(24)---+----(16)---+-------(4)-------+----(8)--+-(4)-+| 2 | reserved | cpu | argument count | size | 8 |+-----+-----------+-----------+-----------------+---------+-----++---------------------------(64)------------------------------+| timestamp |+-------------------------------------------------------------++---------------------------(64)------------------------------+| waking thread id |+-------------------------------------------------------------++--------------------------(...)------------------------------+| argument data |+-------------------------------------------------------------+header word
[0 .. 3]: record type (8)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: argument count.[20 .. 35]: cpu number.[60 .. 63]: scheduling record type (2)
timestamp word
[0 .. 63]: number of ticks
waking thread id
[0 .. 63]: thread koid (kernel object id)
argument data (repeats of each argument)
- (seeArguments for argument format)
Argument Conventions
By convention, the trace writer may also optionally include the following namedargument when writing this record to provide additional information to traceconsumers.
"weight":Int32describing the relativeweight of the waking thread
Legacy Context Switch Record (context switch record type = 0)
As Fuchsia's scheduling has evolved, this record is no longer an effectivecontext switch model. It remains for backwards compatibility.
The record specifies the new state of the outgoing thread following thecontext switch. By definition, the new state of the incoming thread is"running" since it was just resumed.
Format

[0 .. 3]: record type (8)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 23]: cpu number[24 .. 27]: outgoing thread state (any of the values below except "running")[28 .. 35]: outgoing thread (thread ref)[36 .. 43]: incoming thread (thread ref)[44 .. 51]: outgoing thread priority[52 .. 59]: incoming thread priority[60 .. 63]: scheduling record type (0)
timestamp word
[0 .. 63]: number of ticks
outgoing process id word (omitted unless outgoing thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
outgoing thread id word (omitted unless outgoing thread ref denotes inline thread)
[0 .. 63]: thread koid (kernel object id)
incoming process id word (omitted unless incoming thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
incoming thread id word (omitted unless incoming thread ref denotes inline thread)
[0 .. 63]: thread koid (kernel object id)
Thread States
The following thread states are defined:
0: new1: running2: suspended3: blocked4: dying5: dead
These values align with theZX_THREAD_STATE_XXX constants fromzircon/syscalls/object.h.
Log record (record type = 9)
Describes a message written to the log at a particular moment in time.
Format

header word
[0 .. 3]: record type (9)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 30]: log message length in bytes (range 0x0000 to 0x7fff)[31]: always zero (0)[32 .. 39]: thread (thread ref)[40 .. 63]: reserved (must be zero)
timestamp word
[0 .. 63]: number of ticks
process id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
thread id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: thread koid (kernel object id)
log message stream
- UTF-8 string, padded with zeros to 8 byte alignment
Profiler record (record type = 10)
Describes profiler data, such as module loads, memory mappings, and backtraces.This record has several subtypes to represent different kinds of profiler data.
Format
+----------(4)-----------+----------(44)------------+--(12)--+-(4)-+| profiler record type | <type specific> | size | 10 |+------------------------+--------------------------+--------+-----+header word
[0 .. 3]: record type (10)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: profiler record subtype[20 .. 63]: subtype specific data
Module Record (profiler record subtype = 0)
Stores the information about a loaded module.
Format
+-(4)-+---(8)----+---(8)----+------(16)------+---(8)----+-(4)--+----(12)----+-(4)-+| rsvd| build_len| name_len | module_id |thread_ref| 0000 | size | 10 |+-----+----------+----------+----------------+----------+------+------------+-----++--------------------------------(64)-----------------------------------+| timestamp |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| process id (omitted unless thread ref denotes inline thread) |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| thread id (omitted unless thread ref denotes inline thread) |+-----------------------------------------------------------------------++--------------------------------(...)----------------------------------+| module name |+-----------------------------------------------------------------------++--------------------------------(...)----------------------------------+| build id |+-----------------------------------------------------------------------+header word
[0 .. 3]: record type (10)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: profiler record subtype (0)[20 .. 27]: thread ref[28 .. 43]: module id (16 bits)[44 .. 51]: name length in bytes[52 .. 59]: build id length in bytes[60 .. 63]: reserved
timestamp word
[0 .. 63]: number of ticks
process id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
thread id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: thread koid (kernel object id, will constantly be 0)
module name stream
- UTF-8 string, padded with zeros to 8 byte alignment
build id stream
- Binary data, padded with zeros to 8 byte alignment
Mmap Record (profiler record subtype = 1)
Stores the details of a specific memory mapping for a specific module.
Format
+--------(17)-------+-(3)-+------(16)------+---(8)----+-(4)--+----(12)----+-(4)-+| reserved |flags| module_id |thread_ref| 0001 | size | 10 |+--------------------+-----+---------------+----------+------+------------+-----++--------------------------------(64)-----------------------------------+| timestamp |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| process id (omitted unless thread ref denotes inline thread) |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| thread id (omitted unless thread ref denotes inline thread) |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| start address |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| address range |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| vaddr |+-----------------------------------------------------------------------+header word
[0 .. 3]: record type (10)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: profiler record subtype (1)[20 .. 27]: thread ref[28 .. 43]: module id (16 bits)[44 .. 46]: flags[47 .. 63]: reserved
timestamp word
[0 .. 63]: number of ticks
process id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
thread id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: thread koid (kernel object id, will constantly be 0)
start address word
[0 .. 63]: start address in mmap record
address range word
[0 .. 63]: the range of the mmap record
vaddr word
[0 .. 63]: vaddr - module relative address
Backtrace Record (profiler record subtype = 2)
Stores a list of backtrace frames (All of the backtrace frames in a single call stack) within a single record.
Format
+------------(28)------------+---(8)----+---(8)----+-(4)--+----(12)----+-(4)-+| reserved |record_num|thread_ref| 0010 | size | 10 |+----------------------------+----------+----------+------+------------+-----++--------------------------------(64)-----------------------------------+| timestamp |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| process id (omitted unless thread ref denotes inline thread) |+-----------------------------------------------------------------------++--------------------------------(64)-----------------------------------+| thread id (omitted unless thread ref denotes inline thread) |+-----------------------------------------------------------------------++--------------------------------(...)----------------------------------+| backtrace data |+-----------------------------------------------------------------------+header word
[0 .. 3]: record type (10)[4 .. 15]: record size (inclusive of this word) as a multiple of 8 bytes[16 .. 19]: profiler record subtype (2)[20 .. 27]: thread ref[28 .. 35]: number of backtrace records (backtrace data length in 8 byte units)[36 .. 63]: reserved
timestamp word
[0 .. 63]: number of ticks
process id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
thread id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: thread koid (kernel object id)
backtrace data stream
- Binary data, in a multiple of 8 bytes.
Large BLOB record (record type = 15, large type = 0)
Provides large binary BLOB data to be embedded within a trace. Ituses the large record header.
The large BLOB record supports a number of different formats. Theseformats can be used for varying the types of BLOB data and metadataincluded in the record.
Format
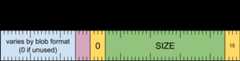
header word
[0 .. 3]: record type (15)[4 .. 35]: record size (inclusive of this word) as a multiple of 8 bytes[36 .. 39]: large record type (0)[40 .. 43]: blob format type[44 .. 63]: reserved, must be zero
In Band Large Blob Record With Metadata (blob format = 0)
This type contains the blob data and metadata within the recorditself. The metadata includes a timestamp, thread/processinformation, and arguments, in addition to a category and name.
The name should be sufficient to identify the type of data containedwithin the blob.
Format

header word
[0 .. 3]: record type (15)[4 .. 35]: record size (inclusive of this word) as a multiple of 8 bytes[36 .. 39]: large record type (0)[40 .. 43]: blob format type (0)[44 .. 63]: reserved, must be zero
format header word
[0 .. 15]: category (string ref)[16 .. 31]: name (string ref)[32 .. 35]: number of arguments[36 .. 43]: thread (thread ref)[44 .. 63]: reserved, must be zero
category stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
timestamp word
[0 .. 63]: number of ticks
process id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: process koid (kernel object id)
thread id word (omitted unless thread ref denotes inline thread)
[0 .. 63]: thread koid (kernel object id)
argument data (repeats for each argument)
- (see below)
blob size word
[0 .. 63]: blob payload size in bytes (excluding padding)
payload stream (variable size)
- binary data, padded with zeros to 8 byte alignment
In Band Large Blob Record No Metadata (blob format = 1)
This type contains the blob data within the record itself,but does not include metadata. The record only containsa category and name.
The name should be sufficient to identify the type of data containedwithin the blob.
Format

header word
[0 .. 3]: record type (15)[4 .. 35]: record size (inclusive of this word) as a multiple of 8 bytes[36 .. 39]: large record type (0)[40 .. 43]: blob format type (1)[44 .. 63]: reserved, must be zero
format header word
[0 .. 15]: category (string ref)[16 .. 31]: name (string ref)[32 .. 63]: reserved, must be zero
category stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
blob size word
[0 .. 63]: blob payload size in bytes (excluding padding)
payload stream (variable size)
- binary data, padded with zeros to 8 byte alignment
Argument types
Arguments associate typed key and value data records. They are used togetherwithevent record anduserspace object record andkernel object record.
Each argument consists of a one word header followed by a variable numberwords of payload. In many cases, the header itself is sufficient to encodethe content of the argument.
There are the following argument types:
- Argument header
- Null argument
- 32-bit signed integer argument
- 32-bit unsigned integer argument
- 64-bit signed integer argument
- 64-bit unsigned integer argument
- Double-precision floating point argument
- String argument
- Pointer argument
- Kernel object id argument
- Boolean argument
- Blob argument
Argument header
All arguments include this header, which specifies the argument's type,name, and size together with 32 bits of data whose usage varies byargument type.
Format

argument header word
[0 .. 3]: argument type[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: varies (must be zero if not used)
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
Null argument (argument type = 0)
Represents an argument that appears in name only, without a value.
Format

argument header word
[0 .. 3]: argument type (0)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: reserved (must be zero)
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
32-bit signed integer argument (argument type = 1)
Represents a 32-bit signed integer.
Format

argument header word
[0 .. 3]: argument type (1)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: 32-bit signed integer
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
32-bit unsigned integer argument (argument type = 2)
Represents a 32-bit unsigned integer.
Format

argument header word
[0 .. 3]: argument type (2)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: 32-bit unsigned integer
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
64-bit signed integer argument (argument type = 3)
Represents a 64-bit signed integer. If a value fits in 32-bits,use the32-bit signed integer argument type instead.
Format

argument header word
[0 .. 3]: argument type (3)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: reserved (must be zero)
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument value word
[0 .. 63]: 64-bit signed integer
64-bit unsigned integer argument (argument type = 4)
Represents a 64-bit unsigned integer. If a value fits in 32-bits,use the32-bit unsigned integer argument type instead.
Format

argument header word
[0 .. 3]: argument type (4)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: reserved (must be zero)
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument value word
[0 .. 63]: 64-bit unsigned integer
Double-precision floating point argument (argument type = 5)
Represents a double-precision floating point number.
Format

argument header word
[0 .. 3]: argument type (5)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: reserved (must be zero)
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument value word
[0 .. 63]: double-precision floating point number
String argument (argument type = 6)
Represents a string value.
Format

argument header word
[0 .. 3]: argument type (6)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 47]: argument value (string ref)[48 .. 63]: reserved (must be zero)
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument value stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
Pointer argument (argument type = 7)
Represents a pointer value. Additional information about the referent canbe provided by auserspace object record associated with the same pointer.
Format

argument header word
[0 .. 3]: argument type (7)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: reserved (must be zero)
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument value word
[0 .. 63]: the pointer value
Kernel object id argument (argument type = 8)
Represents a koid (kernel object id). Additional information about thereferent can be provided by akernel object record associated with thesame koid.
Format

argument header word
[0 .. 3]: argument type (8)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: reserved (must be zero)
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
argument value word
[0 .. 63]: the koid (kernel object id)
Boolean argument (argument type = 9)
Represents a boolean.
Format

argument header word
[0 .. 3]: argument type (9)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: 1 bit padded with zeros
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
Blob argument (argument type = 10)
Represents opaque binary data. The maximum size is slightly smaller than 32k.
Format

argument header word
[0 .. 3]: argument type (10)[4 .. 15]: argument size (inclusive of this word) as a multiple of 8 bytes[16 .. 31]: argument name (string ref)[32 .. 63]: 32-bit unsigned blob size
argument name stream (omitted unless string ref denotes inline string)
- UTF-8 string, padded with zeros to 8 byte alignment
payload stream
- binary data, padded with zeros to 8 byte alignment
- the maximum size will be 32k minus 8 bytes for the header and as many 8-bytewords are used for an inline argument name, if used.
- since the payload stream may be padded a reader should discard bytes beyondthe length specified in theblob size header field.
Except as otherwise noted, the content of this page is licensed under theCreative Commons Attribution 4.0 License, and code samples are licensed under theApache 2.0 License. For details, see theGoogle Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2025-10-24 UTC.