

Overview
TensorRT Python API Reference
Writing custom operators with TensorRT Python plugins¶
TensorRT (TRT) offers a wide array of built-in operators that fit most use cases. However, you may wish to introduce a custom operator for a variety of reasons, including:
Supporting an entirely new operator that TRT does not support out-of-the-box
Adding an operator with a slightly different behavior to an operator that is already supported
TRT provides support for custom operators through plugins. This guide shows how Python functions that define the behavior of a plugin can be implemented and wrapped suchthat they can be added to a network as a custom operator.
Composition of a plugin¶
Primarily, a plugin definition needs two functions, wrapped with decorators provided by thetensorrt.plugin module:
tensorrt.plugin.register(): Returns shape and type characteristics of output tensors. The function signature also defines the input tensors and any attributes the plugin needs to function.A function defining the plugin computation. This can be either (or both)
tensorrt.plugin.impl(): A Just-in-Time (JIT) compute definitiontensorrt.plugin.aot_impl(): An Ahead-of-Time (AOT) compute definition
It is possible to specify both an AOT and JIT implementation for the same plugin at the same time. However, based on user choice, TensorRT will only use one of these implementations for a given plugin or plugin layer in a single build phase.
Optionally, if a plugin is able to support multiple data type/tensor layout combinations for its I/O, or is able to support multiple backends (e.g. kernels), it can also take advantage of TensorRT’s auototuning capabilities to let it pick the most performant configuration of the plugin on the target platform. To enable autotuning, simply define a function wrapped withtensorrt.plugin.autotune().
Let us consider a few examples to understand the specifics of these functions.
Example: Circular padding plugin¶
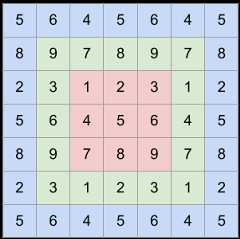
Circular padding is useful for ops like circular convolution. The following image denotes how the original image (red) is circular padded once (green) and twice (blue):
The plugin shall have the following characteristics:
Input:\(N\)-dimensional input
Attribute(s):\(m\)-dimensional parameter
padswhere\(m\) is even and\(m/2 \le N\).padsdenotes the amount of padding to apply before and after each of the\(m/2\) last dimensions of the input tensor.Output: Padded tensor, which has the same data type as the input. The
i-th to-last dimension of the output,\(d^{\text{out}}_{N-i-1}\) can be expressed in terms of the corresponding input dimension,\(d^{\text{in}}_{N-i-1}\), as:
Let’s capture this information in thetensorrt.plugin.register function:
importtensorrt.pluginastrtpimportnumpy.typingasnpt@trtp.register("example::circ_pad_plugin")defcirc_pad_plugin_desc(inp0:trtp.TensorDesc,pads:npt.NDArray[np.int32])->trtp.TensorDesc:ndim=inp0.ndimout_desc=inp0.like()foriinrange(np.size(pads)//2):out_desc.shape_expr[ndim-i-1]+=int(pads[i*2]+pads[i*2+1])returnout_desc
The argumentexample::circ_pad_plugin defines the namespace (“example”) and name (“circ_pad_plugin”) of the plugin. Input arguments annotated withtensorrt.plugin.TensorDesc denote the input tensors; all others are interpreted as plugin attributes. Supported attribute types are:
int,float,str,bool,bytes. Lists/tuples of these types are not supported.1-D Numpy arrays of the following types:
int8,int16,int32,int64,float16,float32,float64,bool. These must be annotated withnumpy.typing.NDArray[dtype], wheredtypeis the expected Numpy data type.
The output signature is atrt.plugin.TensorDesc describing the output. To construct the output tensor descriptor, we start withinp0.like(), which returns a tensor descriptor with identical shape and type characteristics toinp0. Since the output shape is in fact different from the input, symbolic expressions for the output shape is accessed throughtensorrt.plugin.TensorDesc.shape_expr, to which the expected shape is written.
Now let’s define the computation function, decorated withtensorrt.plugin.impl(). For simplicity, let’s leverage PyTorch’storch.nn.functional.pad to do the computation.
importtensorrt.pluginastrtp@trtp.impl("example::circ_pad_plugin")defcirc_pad_plugin_impl(inp0:trtp.Tensor,pads:npt.NDArray[np.int32],outputs:Tuple[trtp.Tensor],stream:int)->None:inp_t=torch.as_tensor(inp0,device="cuda")out_t=torch.as_tensor(outputs[0],device="cuda")out=torch.nn.functional.pad(inp_t,pads.tolist(),mode="circular")out_t.copy_(out)
Note that the decorated function receivestensorrt.plugin.Tensors for each input and output. In contrast toTensorDescs, aTensor references an underlying data buffer, directly accessible throughtensorrt.plugin.Tensor.data_ptr(). When working with Torch and OpenAI Triton kernels, it is easier to usetorch.as_tensor() to zero-copy construct atorch.Tensor corresponding to thetensorrt.plugin.Tensor.
Providing an Ahead-of-Time (AOT) implementation¶
In contrast to a JIT implementation provided bytensorrt.plugin.impl(), an AOT implementation provides the following benefits:
Building a TRT engine with a JIT computation for a plugin requires both its
tensorrt.plugin.register()andtensorrt.plugin.impl()Python definitions to be present at runtime. With an AOT implementation, the plugin is fully embedded in the engine such that no user-provided definition of the plugin is required at runtime.Python-independence of the plugin layer at runtime. This means that if the TRT engine only consists of AOT plugins,it can be executed on the standard TRT runtime as you would an engine with compiled C++ plugins, for example, through
trtexec.
tensorrt.plugin.aot_impl() can be used to define the AOT implementation of a plugin. For the above circular padding plugin, let us define an AOT implementation using an OpenAI Triton kernel:
importtritonimporttriton.languageastl@triton.jitdefcirc_pad_kernel(# input tensorX,# extra scalar args in between input and output tensorsall_pads_0,all_pads_2,all_pads_4,all_pads_6,orig_dims_0,orig_dims_1,orig_dims_2,orig_dims_3,Y_shape_1,Y_shape_2,Y_shape_3,X_len,Y_len,# output tensorY,BLOCK_SIZE:tl.constexpr,):pid=tl.program_id(0)i=pid*BLOCK_SIZE+tl.arange(0,BLOCK_SIZE)mask_y=i<Y_leni3=i%Y_shape_3i2=(i//Y_shape_3)%Y_shape_2i1=(i//Y_shape_3//Y_shape_2)%Y_shape_1i0=i//Y_shape_3//Y_shape_2//Y_shape_1j0=(i0-all_pads_0+orig_dims_0)%orig_dims_0j1=(i1-all_pads_2+orig_dims_1)%orig_dims_1j2=(i2-all_pads_4+orig_dims_2)%orig_dims_2j3=(i3-all_pads_6+orig_dims_3)%orig_dims_3load_idx=(orig_dims_3*orig_dims_2*orig_dims_1*j0+orig_dims_3*orig_dims_2*j1+orig_dims_3*j2+j3)mask_x=load_idx<X_lenx=tl.load(X+load_idx,mask=mask_x)tl.store(Y+i,x,mask=mask_y)@trtp.aot_impl("example::circ_pad_plugin")defcirc_pad_plugin_aot_impl(inp0:trtp.TensorDesc,pads:npt.NDArray[np.int32],outputs:Tuple[trtp.TensorDesc],tactic:int)->Tuple[Union[str,bytes],Union[str,bytes],trtp.KernelLaunchParams,trtp.SymExprs]:asserttactic==0block_size=256type_str="fp32"ifinp0.dtype==trt.float32else"fp16"src=triton.compiler.ASTSource(fn=circ_pad_kernel,signature=f"*{type_str},{','.join(['i32']*13)},*{type_str}",constants={"BLOCK_SIZE":block_size,},)compiled_kernel=triton.compile(src)launch_params=trtp.KernelLaunchParams()N=inp0.ndimall_pads=np.zeros((N*2,),dtype=np.int32)inp_dims=inp0.shape_exprout_dims=outputs[0].shape_exprforiinrange(np.size(pads)//2):all_pads[N*2-2*i-2]=pads[i*2]all_pads[N*2-2*i-1]=pads[i*2+1]# grid dimslaunch_params.grid_x=trtp.cdiv(out_dims.numel(),block_size)# block dimslaunch_params.block_x=compiled_kernel.metadata.num_warps*32# shared memorylaunch_params.shared_mem=compiled_kernel.metadata.sharedall_pads=all_pads.tolist()# Representing all int32 scalar inputs as symbolic expressions.# These inputs are either constants or derivatives of input/output shapes.# The symbolic expressions are resolved after the full shape context becomes available at runtime.# For the `circ_pad_kernel`, there are 13 such scalar extra-arguments, corresponding to the 13 arguments# between the mandatory input and output tensors in the triton kernel's function signature.extra_args=trtp.SymIntExprs.from_tuple([trtp.SymInt32(e)forein[all_pads[0],all_pads[2],all_pads[4],all_pads[6],inp_dims[0],inp_dims[1],inp_dims[2],inp_dims[3],out_dims[1],out_dims[2],out_dims[3],inp_dims.numel(),out_dims.numel(),]])returncompiled_kernel.metadata.name,compiled_kernel.asm["ptx"],launch_params,extra_args
The function decorated withtensorrt.plugin.aot_impl() will be invoked for each I/O type/format combination and for each custom tactic advertised withtensorrt.plugin.autotune(). For each such combination, it should return the name of the kernel, the compiled form of the kernel, the kernel launch parameters, and any extra scalar arguments to pass to the kernel. Note that
When dealing with dynamic shapes, concrete I/O dimensions may not be known when
tensorrt.plugin.aot_impl()is invoked. Therefore, the kernel launch parameters and extra kernel arguments are specified symbolically.The kernel should always be written such that the input tensors come first, any scalar args (specified as above) come next, with the output tensors at the end.
Picking the most performant plugin configuration: Autotuning¶
Let’s assume the plugin is able to support both FP32 and FP16 I/O, in linear tensor layouts (tensor formats). If performance is key, and it is uncertain whether FP32 or FP16 would perform better on the target platform, we can define a function decorated withtensorrt.plugin.autotune().
@trtp.autotune("example::circ_pad_plugin")defcirc_pad_plugin_autotune(inp0:trtp.TensorDesc,pads:npt.NDArray[np.int32],outputs:Tuple[trtp.TensorDesc],)->List[trtp.AutoTuneCombination]:return[trtp.AutoTuneCombination("FP32|FP16, FP32|FP16","LINEAR")]
The decorated function must return a list oftensorrt.plugin.AutoTuneCombinations. In this case, we define a single combinationAutoTuneCombination("FP32|FP16,FP32|FP16","LINEAR"); this indicates that the input and output must be either both FP32 or both FP16, and each have linear formats. When an autotune function is defined, during the engine build, TRT may execute the plugin (invoke itsimpl function) with random inputs, for each of the type/format combinations.
Adding the plugin to a TensorRT network¶
Now that we have defined the plugin, it can be added to a TensorRT network. Depending on your workflow, you may need to add the plugin directly to a TRTtensorrt.INetworkDefinition through the TRT Python API, or you may want the plugin to be added by the TRT ONNX parser when loading an ONNX graph containing the custom operator.
Adding the plugin using TRT Python APIs¶
Thetensorrt.INetworkDefinition.add_plugin() API can be used to add a plugin to a network definition (an instance oftensorrt.INetworkDefinition):
input_tensor=network.add_input(name="x",dtype=trt.DataType.FLOAT,shape=x.shape)plugin_layer=network.add_plugin(trt.plugin.op.example.circ_pad_plugin(input_tensor,pads=pads),aot=False)
Note that
The registered plugin is findable in
tensorrt.plugin.opunder its registered namespace and name.tensorrt.INetworkDefinition.add_plugin()takes a boolean argumentaot, which can be used to choose either the AOT or JIT implementation of a plugin that has both definitions. If a plugin has only one implementation (either AOT or JIT), then omitting theaotargument will result in that implementation being picked by TensorRT.
When a plugin has both AOT and JIT implementations defined, it is also possible to apply a global setting to control whichimplementation is chosen.tensorrt.NetworkDefinitionCreationFlag.PREFER_AOT_PYTHON_PLUGINS andtensorrt.NetworkDefinitionCreationFlag.PREFER_JIT_PYTHON_PLUGINS are mutually exclusive flags that can be applied to thetensorrt.INetworkDefinition as follows:
builder=trt.Builder(trt.Logger(trt.Logger.INFO))# Always choose AOT implementations wherever possiblenetwork=builder.create_network(1<<int(trt.NetworkDefinitionCreationFlag.PREFER_AOT_PYTHON_PLUGINS))...# Now the `aot` argument can be omitted (and TRT will choose the AOT implementation)plugin_layer=network.add_plugin(trt.plugin.op.example.circ_pad_plugin(input_tensor,pads=pads))
Loading an ONNX model with the custom operator¶
It is possible to load an ONNX model with a custom op node which you need to run through the TRT plugin. To allow the TRT ONNX parser to correctly recognize your plugin as being mapped to the ONNX node(s) of interest, ensure that:
The
opproperty of the ONNX node is exactly the same as your plugin name.The node contains a string attribute called
plugin_namespacewith the namespace of your plugin.For a plugin with both AOT and JIT implementations, either
The node should contain a boolean attribute called
aotto communicate which implementation should be chosen (truefor AOT,falsefor JIT), orNetworkDefinitionCreationFlag.PREFER_AOT_PYTHON_PLUGINS()orNetworkDefinitionCreationFlag.PREFER_JIT_PYTHON_PLUGINS()should be specified (see above for an example)
For example, if usingONNX Graphsurgeon, the custom op node can be constructed as follows:
importonnx_graphsurgeonasgsvar_x=gs.Variable(name="x",shape=inp_shape,dtype=np.float32)var_y=gs.Variable(name="y",dtype=np.float32)circ_pad_node=gs.Node(name="circ_pad_plugin",op="circ_pad_plugin",inputs=[var_x],outputs=[var_y],attrs={"pads":pads,"plugin_namespace":"example"},)
Advanced usage¶
Example: Operators with data-dependent output shapes - Non-zero¶
Non-zero is an operation where the indices of the non-zero elements of the input tensor is found. Therefore, it has data-dependent output shapes (DDS), for which typical shape calculations cannot be done with input shapes.
To handle DDS, the extent of each data-dependent output dimension must be expressed in terms of asize tensor, which is a scalar that communicates to TRT an upper-bound and an autotune value for that dimension, in terms of the input shapes. The TRT engine build may be optimized for the autotune value, but the extent of that dimension may stretch up to the upper-bound at runtime.
In this example, we consider a 2D input tensorinp0; the output will be an\(N \times 2\) tensor (a set of\(N\) 2D indices), where\(N\) is the number of non-zero indices. At maximum, all elements could be non-zero, and so the upper-bound could be expressed asupper_bound=inp0.shape_expr[0]*inp0.shape_expr[1].
On average, we can expect half of the input to be filled with zero, so a size tensor can be constructed with that as the autotune value:
st=trt.plugin.size_tensor(opt=upper_bound//2,upper_bound=upper_bound)
Now we’re ready to construct the output shape.st.expr() returns a shape expression for the size tensor, so a tensor descriptor for the output shape can be constructed astrt.plugin.from_shape_expr((st.expr(),2),dtype=trt.int32). TRT requires that any size tensors also be made outputs of the plugin. Putting things together, we arrive at the following:
importtensorrt.pluginastrtp@trtp.register("example::non_zero_plugin")defnon_zero_plugin_desc(inp0:trtp.TensorDesc,)->Tuple[trtp.TensorDesc,trtp.TensorDesc]:upper_bound=inp0.shape_expr[0]*inp0.shape_expr[1]st=trtp.size_tensor(upper_bound//2,upper_bound)returntrtp.from_shape_expr((st.expr(),2),dtype=trt.int32),st
Example: Implementing in-place custom ops with I/O aliasing¶
In-place computations can be accomplished with TRT plugins via aliased I/O. i.e. An input that needs to be modified in-place can be represented by an input-output pair, where the output is aliased to the input. For example, consider a simple elementwise addition plugin. If an in-place addition is needed, that can be achieved as below:
importtensorrt.pluginastrtp@trtp.register("sample::elemwise_add_plugin_")defadd_plugin_desc_(inp0:trtp.TensorDesc)->trtp.TensorDesc:returninp0.aliased()
Note thatinp0.aliased() produces an outputTensorDesc that is aliased toinp0.
Example: Plugins with multiple backends: Using custom tactics¶
It may be the case that there are multiple kernels or libraries available to perform the plugin computation (for the same IO data type/tensor layout combination) but it is not predeterminable which backend would be the fastest on the target platform. Such alternate backends are termedtactics of the plugin. To let TRT figure out the fastest tactic, it is possible to leverage the autotune function.
Let’s assume that we have an OpenAI Triton kernelcirc_pad_kernel which can perform the circular padding operation in the above example. We can ask TRT to pick the fastest between the OpenAI Triton kernel andtorch.nn.functional.pad as below:
importtensorrt.pluginastrtpfromenumimportIntEnumclassTactic(IntEnum):TORCH=1TRITON=2@trt.plugin.autotune("sample::circ_pad_plugin")defcirc_pad_plugin_autotune(inp0:trtp.TensorDesc,pads:npt.NDArray[np.int32],outputs:Tuple[trtp.TensorDesc])->List[trtp.AutoTuneCombination]:c=trtp.AutoTuneCombination()c.pos([0,1],"FP32|FP16")c.tactics([int(Tactic.TORCH),int(Tactic.TRITON)])return[c]
Note that we’re using another way of constructing atrt.plugin.AutoTuneCombination here – namely, throughpos(...) to populate the type/format information andtactics(...) to specify the tactics.
Now, theimpl function can take an additionalint argument calledtactic to use the appropriate backend:
@trtp.impl("example::circ_pad_plugin")defcirc_pad_plugin_impl(inp0:trtp.Tensor,pads:npt.NDArray[np.int32],outputs:Tuple[trtp.Tensor],stream:int,tactic:int)->None:inp_t=torch.as_tensor(inp0,device="cuda")out_t=torch.as_tensor(outputs[0],device="cuda")iftactic==Tactic.TORCH:out=torch.nn.functional.pad(inp_t,pads.tolist(),mode="circular")out_t.copy_(out)eliftactic==Tactic.TRITON:N=inp0.ndimall_pads=np.zeros((N*2,),dtype=np.int32)out_dims=trtp.Shape(tuple(inp0.shape))block_size=256num_blocks=tuple([int((np.prod(out_dims)+block_size-1)//block_size)])circ_pad_kernel[num_blocks](inp_t,...,BLOCK_SIZE=block_size)
FAQ¶
What happened to plugin creators, plugin registration and plugin libraries?
You may have this question if you have previously dealt with class-based TRT plugins. For decorator based plugins, registration is automatically handled by thetensorrt.plugin module as long as thetensorrt.plugin.register function is defined.
To simulate the experience of plugin libraries, you may define plugins under a common namespace on a separate Python module, and then load the module when that plugin “library” needs to be loaded.
How is the serialization/deserialization of plugin attributes handled?
Thetensorrt.plugin module automatically serializes any plugin attributes included in thetensorrt.plugin.impl function signature into the TRT engine. When that engine is loaded, those attributes are deserialized and passed back to thetensorrt.plugin.impl function.
Note
If only a subset of the plugin attributes included intensorrt.plugin.register is required for the plugin computation, only include those intensorrt.plugin.impl function signature. This should avoid the unnecessary serialization of data, and therefore produce leaner TRT engines.
Limitations¶
TRT plugins defined in Python result in TRT engines that, when executed, rely on the availability of a Python environment with those plugin definitions. To build Python-independent TRT engines, it is recommended to use the TRT C++ plugin interfaces.
This guide describes plugin implementations through the
tensorrt.pluginmodule, which supports some of the most common use cases for plugin usage. For more advanced use cases, such as passing shape inputs, it is recommended to define plugins as direct implementations of thetensorrt.IPluginV3interface.