Stateful computations
Contents
Stateful computations#
JAX transformations likejit(),vmap(),grad(), require the functionsthey wrap to be pure: that is, functions whose outputs dependsolely on the inputs, and which haveno side effects such as updating of global state.You can find a discussion of this inJAX sharp bits: Pure functions.
This constraint can pose some challenges in the context of machine learning, where state may exist inmany forms. For example:
model parameters,
optimizer state, and
stateful layers, such asBatchNorm.
This section offers some advice of how to properly handle state in a JAX program.
A simple example: Counter#
Let’s start by looking at a simple stateful program: a counter.
importjaximportjax.numpyasjnpclassCounter:"""A simple counter."""def__init__(self):self.n=0defcount(self)->int:"""Increments the counter and returns the new value."""self.n+=1returnself.ndefreset(self):"""Resets the counter to zero."""self.n=0counter=Counter()for_inrange(3):print(counter.count())
123
The counter’sn attribute maintains the counter’sstate between successive calls ofcount. It is modified as a side effect of callingcount.
Let’s say we want to count fast, so we JIT-compile thecount method.(In this example, this wouldn’t actually help speed anyway, for many reasons, but treat this as a toy model of JIT-compiling the update of model parameters, wherejit() makes an enormous difference).
counter.reset()fast_count=jax.jit(counter.count)for_inrange(3):print(fast_count())
111
Oh no! Our counter isn’t working. This is because the line
self.n+=1
incount involves a side effect: it modifies the input counter in-place, and so this function is not supported byjit.Such side effects are executed only once when the function is first traced, and subsequent calls will not repeat the side effect.So, how do we fix it?
The solution: explicit state#
Part of the problem with our counter was that the returned value didn’t depend on the arguments, meaning a constant was “baked into” the compiled output. But it shouldn’t be a constant – it should depend on the state. Well, then why don’t we make the state into an argument?
CounterState=intclassCounterV2:defcount(self,n:CounterState)->tuple[int,CounterState]:# You could just return n+1, but here we separate its role as# the output and as the counter state for didactic purposes.returnn+1,n+1defreset(self)->CounterState:return0counter=CounterV2()state=counter.reset()for_inrange(3):value,state=counter.count(state)print(value)
123
In this new version ofCounter, we movedn to be an argument ofcount, and added another return value that represents the new, updated, state. To use this counter, we now need to keep track of the state explicitly. But in return, we can now safelyjax.jit this counter:
state=counter.reset()fast_count=jax.jit(counter.count)for_inrange(3):value,state=fast_count(state)print(value)
123
A general strategy#
We can apply the same process to any stateful method to convert it into a stateless one. We took a class of the form
classStatefulClassstate:Statedefstateful_method(*args,**kwargs)->Output:
and turned it into a class of the form
classStatelessClassdefstateless_method(state:State,*args,**kwargs)->(Output,State):
This is a commonfunctional programming pattern, and, essentially, is the way that state is handled in all JAX programs.
Notice that the need for a class becomes less clear once we have rewritten it this way. We could just keepstateless_method, since the class is no longer doing any work.This is because, like the strategy we just applied, object-oriented programming (OOP) is a way to help programmers understand program state.
In our case, theCounterV2 class is nothing more than a namespace bringing all the functions that useCounterState into one location. Exercise for the reader: do you think it makes sense to keep it as a class?
Incidentally, you’ve already seen an example of this strategy in the JAX pseudo-randomness API,jax.random, shown in thePseudorandom numbers section.Unlike Numpy, which manages random state using implicitly updated stateful classes, JAX requires the programmer to work directly with the random generator state – the PRNG key.
Simple worked example: Linear Regression#
Let’s apply this strategy to a simple machine learning model: linear regression via gradient descent.
Here, we only deal with one kind of state: the model parameters.But generally, you’ll see many kinds of state being threaded in and out of JAX functions, like optimizer state, layer statistics for batchnorm, and others.
The function to look at carefully isupdate.
fromtypingimportNamedTupleclassParams(NamedTuple):weight:jnp.ndarraybias:jnp.ndarraydefinit(rng)->Params:"""Returns the initial model params."""weights_key,bias_key=jax.random.split(rng)weight=jax.random.normal(weights_key,())bias=jax.random.normal(bias_key,())returnParams(weight,bias)defloss(params:Params,x:jnp.ndarray,y:jnp.ndarray)->jnp.ndarray:"""Computes the least squares error of the model's predictions on x against y."""pred=params.weight*x+params.biasreturnjnp.mean((pred-y)**2)LEARNING_RATE=0.005@jax.jitdefupdate(params:Params,x:jnp.ndarray,y:jnp.ndarray)->Params:"""Performs one SGD update step on params using the given data."""grad=jax.grad(loss)(params,x,y)# If we were using Adam or another stateful optimizer,# we would also do something like## updates, new_optimizer_state = optimizer(grad, optimizer_state)## and then use `updates` instead of `grad` to actually update the params.# (And we'd include `new_optimizer_state` in the output, naturally.)new_params=jax.tree.map(lambdaparam,g:param-g*LEARNING_RATE,params,grad)returnnew_params
Notice that we manually pipe the params in and out of the update function.
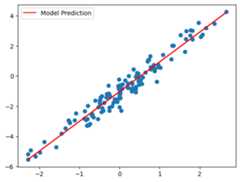
importmatplotlib.pyplotaspltrng=jax.random.key(42)# Generate true data from y = w*x + b + noisetrue_w,true_b=2,-1x_rng,noise_rng=jax.random.split(rng)xs=jax.random.normal(x_rng,(128,1))noise=jax.random.normal(noise_rng,(128,1))*0.5ys=xs*true_w+true_b+noise# Fit regressionparams=init(rng)for_inrange(1000):params=update(params,xs,ys)plt.scatter(xs,ys)plt.plot(xs,params.weight*xs+params.bias,c='red',label='Model Prediction')plt.legend();
Taking it further#
The strategy described above is how any JAX program must handle state when using transformations likejit,vmap,grad, etc.
Handling parameters manually seems fine if you’re dealing with two parameters, but what if it’s a neural net with dozens of layers? You might already be getting worried about two things:
Are we supposed to initialize them all manually, essentially repeating what we already write in the forward pass definition?
Are we supposed to pipe all these things around manually?
The details can be tricky to handle, but there are examples of libraries that take care of this for you. SeeJAX Ecosystem Libraries for some examples.