

About GKE Inference Gateway
This page explains the key concepts and features of Google Kubernetes Engine (GKE)Inference Gateway, an extension to the GKEGateway for optimized serving of generative AI applications.
This page assumes that you know about the following:
- AI/ML orchestration on GKE
- Generative AI terminology
- GKE networking concepts,includingServices, and theGKE Gateway API
- Load balancing in Google Cloud,especially how load balancers interact with GKE
This page is intended for the following personas:
- Machine learning (ML) engineers, Platform admins and operators, andData and AI specialists who are interested in using Kubernetes containerorchestration capabilities for serving AI/ML workloads.
- Cloud architects and Networking specialists who interact withKubernetes networking.
Overview
GKE Inference Gateway is an extension to theGKEGateway that providesoptimized routing and load balancing for serving generative ArtificialIntelligence (AI) workloads. It simplifies the deployment, management, andobservability of AI inference workloads.
To choose the optimal load balancing strategy for your AI/ML workloads, seeChoose a load balancing strategy for AI inference on GKE.
Features and benefits
GKE Inference Gateway provides the following key capabilities toefficiently serve generative AI models for generative AI applications onGKE:
- Supported metrics:
KV cache hits: the number of successful lookups in the key-value(KV) cache.- GPU or TPU utilization: the percentage of time that the GPU or TPU isactively processing.
- Request queue length: the number of requests waiting to beprocessed.
- Optimized load balancing for inference: distributes requests to optimizeAI model serving performance. It uses metrics from model servers, such as
KV cache hitsand thequeue length of pending requeststo consumeaccelerators (such as GPUs and TPUs) more efficiently for generative AIworkloads. This enablesPrefix-Cache Aware Routing, a key feature thatsends requests with shared context, identified by analyzing the request body,to the same model replica by maximizing cache hits. This approach dramaticallyreduces redundant computations and improves Time-to-First-Token, making ithighly effective for conversational AI, Retrieval-Augmented Generation (RAG),and other template-based generative AI workloads. - Dynamic LoRA fine-tuned model serving: supports serving dynamic LoRAfine-tuned models on a common accelerator. This reduces the number of GPUsand TPUs required to serve models by multiplexing multiple LoRA fine-tunedmodels on a common base model and accelerator.
- Optimized autoscaling for inference: the GKE HorizontalPod Autoscaler (HPA) uses model server metrics toautoscale, which helpsensure efficient compute resource use and optimized inference performance.
- Model-aware routing: routes inference requests based on the model namesdefined in the
OpenAI APIspecificationswithin your GKE cluster. You can define Gateway routingpolicies, such as traffic splitting and request mirroring, to managedifferent model versions and simplify model rollouts. For example, you canroute requests for a specific model name to differentInferencePoolobjects, each serving a different version of the model. For more information on how to configure this, seeConfigure Body-Based Routing. - Integrated AI safety and content filtering: GKE Inference Gatewayintegrates with Google CloudModel Armorto apply AI safety checks and content filtering to prompts and responses atthe gateway. You can also useNVIDIA NeMoGuardrails.Model Armor provides logs of requests, responses, andprocessing for retrospective analysis and optimization.GKE Inference Gateway's open interfaces allow third-party providers anddevelopers to integrate custom services into the inference request process.
- Model-specific serving
Priority: lets you specify the servingPriorityof AI models. Prioritize latency-sensitive requests overlatency-tolerant batch inference jobs. For example, you can prioritizerequests from latency-sensitive applications and drop less time-sensitivetasks when resources are constrained. - Inference observability: provides observability metrics for inferencerequests, such as request rate, latency, errors, and saturation. Monitor theperformance and behavior of your inference services throughCloud Monitoring and Cloud Logging, leveraging specialized prebuiltdashboards for detailed insights. For more information, seeViewGKE Inference Gatewaydashboard.
- Advanced API Management with Apigee: integrates withApigee to enhance your inference gateway with features such as APIsecurity, rate limiting, and quotas. For detailed instructions, seeConfigure Apigee for authentication and APImanagement.
- Extensibility: built on an extensible, open-source Kubernetes GatewayAPI Inference Extension that supports auser-managed Endpoint Pickeralgorithm.
Understand key concepts
GKE Inference Gateway enhances the existingGKEGateway that usesGatewayClassobjects. GKE Inference Gateway introduces the following newGateway API Custom Resource Definitions (CRDs), aligned with theOSS KubernetesGateway API extension forInference:
InferencePoolobject: represents a group of Pods (containers) thatshare the same compute configuration, accelerator type, base language model,and model server. This logically groups and manages your AI model servingresources. A singleInferencePoolobject can span multiple Pods acrossdifferent GKE nodes and provides scalability and highavailability.InferenceObjectiveobject: specifies the serving model's name from theInferencePoolaccording to theOpenAI APIspecification. TheInferenceObjectiveobject also specifies the model's serving properties,such as the AI model'sPriority. GKE Inference Gateway givespreference to workloads with a higher priority value. This lets youmultiplex latency-critical and latency-tolerant AI workloads on aGKE cluster. You can also configure theInferenceObjectiveobject to serve LoRA fine-tuned models.
The following diagram illustrates GKE Inference Gateway andits integration with AI safety, observability, and model serving within aGKE cluster.
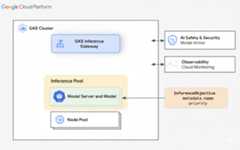
The following diagram illustrates the resource model that focuses on two newinference-focused personas and the resources they manage.

How GKE Inference Gateway works
GKE Inference Gateway uses Gateway API extensions andmodel-specific routing logic to handle client requests to an AI model. Thefollowing steps describe the request flow.
How the request flow works
GKE Inference Gateway routes client requests from the initial request to amodel instance. This section describes how GKE Inference Gateway handlesrequests. This request flow is common for all clients.
- The client sends a request, formatted as described in theOpenAIAPI specification, tothe model running in GKE.
- GKE Inference Gateway processes the request using the followinginference extensions:
- Body-based routing extension: extracts the model identifier from theclient request body and sends it to GKE Inference Gateway.GKE Inference Gateway then uses this identifier to route therequest based on rules defined in the Gateway API
HTTPRouteobject.Request body routing is similar to routing based on the URL path. Thedifference is that request body routing uses data from the request body. - Security extension: uses Model Armor,NVIDIA NeMoGuardrails,or supported third-party solutions to enforce model-specific securitypolicies, which include content filtering, threat detection,sanitization, and logging. The security extension applies these policiesto both request and response processing paths.
- Endpoint picker extension: monitors key metrics from model serverswithin the
InferencePool. It tracks the key-value cache (KV-cache)utilization, queue length of pending requests, prefix cache indexes, andactive LoRA adapters on each model server. It then routes the request tothe optimal model replica based on these metrics to minimize latency andmaximize throughput for AI inference.
- Body-based routing extension: extracts the model identifier from theclient request body and sends it to GKE Inference Gateway.GKE Inference Gateway then uses this identifier to route therequest based on rules defined in the Gateway API
- GKE Inference Gateway routes the request to the model replica returnedby the endpoint picker extension.
The following diagram illustrates the request flow from a client to a modelinstance through GKE Inference Gateway.

How traffic distribution works
GKE Inference Gateway dynamically distributes inference requests to modelservers within theInferencePool object. This helps optimize resourceutilization and maintains performance under varying load conditions.GKE Inference Gateway uses the following two mechanisms to manage trafficdistribution:
Endpoint picking: dynamically selects the most suitable model server tohandle an inference request. It monitors server load and availability, thenmakes optimal routing decisions by calculating a
scorefor each servercombining a number of optimization heuristics:- Prefix cache aware routing: GKE Inference Gateway tracksavailable prefix cache indexes on each model server, and gives a higherscore to a server with a longer prefix cache match.
- Load aware routing: GKE Inference Gateway monitors server load(KV cache utilization and pending queue depth), and gives a higher scoreto a server with lower load.
- LoRA aware routing: when dynamic LoRA serving is enabled,GKE Inference Gateway monitors active LoRA adapters per server, andgives a higher score to a server with the requested LoRA adapter active,or additional room to dynamically load the requested LoRA adapter. Aserver with the highest total score of all the preceding is picked.
Queueing and shedding: manages request flow and prevents trafficoverload. GKE Inference Gateway stores incoming requests in a queue andprioritizes requests based on defined priority.
GKE Inference Gateway uses a numericalPriority system, also known asCriticality, to manage request flow and prevent overload. ThisPriority isan optional integer field defined by the user for eachInferenceObjective. Ahigher value signifies a more important request. When the system is underpressure, requests with aPriority less than0 are considered lowerpriority and are dropped first, returning a429 error to protect morecritical workloads. By default, thePriority is0. Requests are onlydropped due to priority if theirPriority is explicitly set to a value lessthan0. This system lets you prioritize latency-sensitive online inferencetraffic over less time-sensitive batch jobs.
GKE Inference Gateway supports streaming inference for applications likechatbots and live translation, which require continuous or near-real-timeupdates. Streaming inference delivers responses in incremental chunks orsegments, instead of a single, complete output. If an error occurs during astreaming response, the stream terminates, and the client receives an errormessage. GKE Inference Gateway does not retry streaming responses.
Explore application examples
This section provides examples of using GKE Inference Gateway to addressvarious generative AI application scenarios.
Example 1: Serve multiple generative AI models on a GKE cluster
A company wants to deploy multiple large language models (LLMs) to serve different workloads. For example, they might want to deploy aGemma3 model for a chatbot interface and aDeepseek model for a recommendation application. The company needs to ensure optimal serving performance for these LLMs.
Using GKE Inference Gateway, you can deploy these LLMs on yourGKE cluster with your chosen accelerator configuration in anInferencePool. You can then route requests based on the model name (such aschatbot andrecommender) and thePriority property.
The following diagram illustrates how GKE Inference Gateway routes requeststo different models based on the model name andPriority.

This diagram illustrates how a request to a GenAI service onexample.com/completions is handled by GKE Inference Gateway. The requestfirst reaches aGateway in theInfra namespace. ThisGateway forwards therequest to anHTTPRoute in theGenAI Inference namespace, which isconfigured to handle requests for chatbot and sentiment models. For the chatbotmodel, theHTTPRoute splits traffic: 90% is directed to anInferencePoolrunning the current model version (selected by{pool: gemma}), and 10% goes toa pool with a newer version ({pool: gemma-new}), typically for canary testing.Both pools are linked to anInferenceObjective that assigns aPriority of 10to requests for the chatbot model, ensuring these requests are treated as highpriority.
Example 2: Serve LoRA adapters on a shared accelerator
A company wants to serve LLMs for document analysis and focuses on audiences inmultiple languages, such as English and Spanish. They have fine-tuned models foreach language, but need to efficiently use their GPU and TPU capacity. You canuse GKE Inference Gateway to deploy dynamic LoRA fine-tuned adapters foreach language (for example,english-bot andspanish-bot) on a common basemodel (for example,llm-base) and accelerator. This lets you reduce the numberof required accelerators by densely packing multiple models on a commonaccelerator.
The following diagram illustrates how GKE Inference Gateway serves multipleLoRA adapters on a shared accelerator.

What's next
- Deploy GKE Inference Gateway
- Customize GKE Inference Gateway configuration
- Serve an LLM with GKE Inference Gateway
Except as otherwise noted, the content of this page is licensed under theCreative Commons Attribution 4.0 License, and code samples are licensed under theApache 2.0 License. For details, see theGoogle Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2025-12-15 UTC.