

Design a self-service data platform for a data mesh
In a data mesh, a self-service data platform enables users to generate valuefrom data by enabling them to autonomously build, share, and use data products.To fully realize these benefits, we recommend that your self-service dataplatform provide the capabilities described in this document.
This document is part of a series which describes how to implement a data meshon Google Cloud. It assumes that you have read and are familiar with theconcepts described inBuild a modern, distributed Data Mesh with Google Cloud andArchitecture and functions in a data mesh.
The series has the following parts:
- Architecture and functions in a data mesh
- Design a self-service data platform for a data mesh (this document)
- Build data products in a data mesh
- Discover and consume data products in a data mesh
Data platform teams typically create central self-service data platforms, asdescribed in this document. This team builds the solutions and components thatdomain teams (both data producers and data consumers) can use to both create andconsume data products. Domain teams represent functional parts of a data mesh.By building these components, the data platform team enables a smoothdevelopment experience and reduces the complexity of building, deploying, andmaintaining data products that are secure and interoperable.
Ultimately, the data platform team should allow domain teams to move faster.They help increase the efficiency of domain teams by providing those teams with alimited set of tools that address their needs. In providing these tools,the data platform team removes the burden of having the domain team build andsource these tools themselves. The tooling choices should be customizable todifferent needs and not force an inflexible way of working on the data domainteams.
The data platform team shouldn't focus on building custom solutions for datapipeline orchestrators or for continuous integration and continuous deployment(CI/CD) systems. Solutions such as CI/CD systems are readily available asmanaged cloud services, for example, Cloud Build. Using managed cloudservices can reduce operational overheads for the data platform team and letthem focus on the specific needs of the data domain teams as the users of theplatform. With reduced operational overhead, the data platform team can focusmore time on addressing the specific needs of the data domain teams.
Architecture
The following diagram illustrates the architecture components of a self-servicedata platform. The diagram also shows how these components can support teams asthey develop and consume data products across the data mesh.

As shown in the preceding diagram, the self-service data platform provides thefollowing:
Platform solutions: These solutions consist of composablecomponents for provisioning Google Cloud projects and resources, which usersselect and assemble in different combinations to meet their specificrequirements. Instead of directly interacting with the components, users ofthe platform can interact with platform solutions to help them to achieve aspecific goal. Data domain teams should design platform solutions to solve commonpain-points and friction areas that cause slowdowns in data productdevelopment and consumption. For example, data domain teams onboarding ontothe data mesh can use aninfrastructure-as-code (IaC) template. Using IaC templates lets them quickly create a set ofGoogle Cloud projects with standard Identity and Access Management (IAM)permissions, networking, security policies, and relevant Google CloudAPIs enabled for data product development. We recommend that each solution isaccompanied with documentation such as "how to get started" guidance and codesamples. Data platform solutions and their components must be secure andcompliant by default.
Common services: These services provide data productdiscoverability, management, sharing, and observability. These servicesfacilitate data consumers' trust in data products, and are an effective wayfor data producers to alert data consumers to issues with their data products.
Data platform solutions and common services might include the following:
- IaC templates to set up foundational data product development workspaceenvironments, which include the following:
- IAM
- Logging and monitoring
- Networking
- Security and compliance guardrails
- Resource tagging for billing attribution
- Data product storage, transformation, and publishing
- Data product registration, cataloging, and metadata tagging
- IaC templates which follow organizational security guardrails and bestpractices that can be used to deploy Google Cloud resources intoexisting data product development workspaces.
- Application and data pipeline templates that can be used to bootstrapnew projects or used as reference for existing projects. Examples of suchtemplates include the following:
- Usage of common libraries and frameworks
- Integration with platform logging, monitoring, and observability tooling
- Build and test tooling
- Configuration management
- Packaging and CI/CD pipelines for deployment
- Authentication, deployment, and management of credentials
- Common services to provide data product observability and governancewhich can include the following:
- Uptime checks to show the overall state of data products.
- Custom metrics to give helpful indicators about data products.
- Operational support by the central team such that data consumerteams are alerted of changes in data products they use.
- Product scorecards to show how data products are performing.
- A metadata catalog for discovering data products.
- A centrally defined set of computational policies that can beapplied globally across the data mesh.
- A data marketplace to facilitate data sharing across domain teams.
Create platform components and solutions using IaC templates discusses the advantages of IaC templates to expose and deploy data products.Provide common services discusses why it's helpful to provide domain teams with common infrastructurecomponents that have been built and are managed by the data platform team.
Create platform components and solutions using IaC templates
The goal of data platform teams is to set up self-service data platforms to getmore value from data. To build these platforms, they create and provide domainteams with vetted, secure, and self-serviceable infrastructure templates. Domainteams use these templates to deploy their data development and data consumptionenvironments. IaC templates help data platform teams achieve that goal andenable scale. Using vetted and trusted IaC templates simplifies the resourcedeployment process for domain teams by allowing those teams to reuse existingCI/CD pipelines. This approach lets domain teams quickly get started and becomeproductive within the data mesh.
IaC templates can be created using an IaC tool. Although there are multiple IaCtools, includingCloud Config Connector,Pulumi,Chef,andAnsible,this document provides examples forTerraform-basedIaC tools. Terraform is an open source IaC tool that allows the data platformteam to efficiently create composable platform components and solutions forGoogle Cloud resources. Using Terraform, the data platform team writescode that specifies the chosen end-state and lets the tool figure out how toachieve that state. This declarative approach lets the data platform team treatinfrastructure resources as immutable artifacts for deployment acrossenvironments. It also helps to reduce the risk of inconsistencies arisingbetween deployed resources and the declared code in source control (referred toasconfiguration drift). Configuration drift caused by ad hoc and manualchanges to infrastructure hinders safe and repeatable deployment of IaCcomponents into production environments.
Common IaC templates for composable platform components include usingTerraform modules for deploying resources such as a BigQuery dataset, Cloud Storagebucket, or Cloud SQL database. Terraform modules can be combined intoend-to-end solutions for deploying complete Google Cloud projects, includingrelevantresources deployed using the composablemodules.Example Terraform modules can be found in theTerraform blueprints for Google Cloud.
Each Terraform module should by default satisfy security guardrails andcompliance policies that your organization uses. These guardrails and policiescan also be expressed as code and be automated using automated complianceverification tooling such as Google Cloudpolicy validation tool.
Your organization should continuously test the platform-provided Terraformmodules, using the same automated compliance guardrails that it uses to promotechanges into production.
To make IaC components and solutions discoverable and consumable for domainteams that have minimal experience with Terraform, we recommend that you useservices such asService Catalog.Users who have significant customization requirements should be allowed tocreate their own deployment solutions from the same composable Terraformtemplates used by existing solutions.
When using Terraform, we recommend that you follow the Google Cloudbest-practices as outlined inBest practices for using Terraform.
To illustrate how Terraform can be used to create platform components, thefollowing sections discuss examples of how Terraform can be used to exposeconsumption interfaces and to consume a data product.
Expose a consumption interface
A consumption interface for a data product is a set of guarantees on the dataquality and operational parameters provided by the data domain team to enableother teams to discover and use their data products. Each consumption interfacealso includes a product support model and product documentation. A data productmay have different types of consumption interfaces, such as APIs or streams, asdescribed inBuild data products in a data mesh.The most common consumption interface might be a BigQueryauthorized dataset, authorized view, or authorized function. This interfaceexposes a read-only virtual table, which is expressed as a query into the datamesh. The interface does not grant reader permissions to directly access theunderlying data.
Google provides an exampleTerraform module for creating authorized views without granting teams permissions to the underlying authorized datasets. Thefollowing code from this Terraform module grants these IAMpermissions on thedataset_id authorized view:
module "add_authorization" { source = "terraform-google-modules/bigquery/google//modules/authorization" version = "~> 4.1" dataset_id = module.dataset.bigquery_dataset.dataset_id project_id = module.dataset.bigquery_dataset.project roles = [ { role = "roles/bigquery.dataEditor" group_by_email = "ops@mycompany.com" } ] authorized_views = [ { project_id = "view_project" dataset_id = "view_dataset" table_id = "view_id" } ] authorized_datasets = [ { project_id = "auth_dataset_project" dataset_id = "auth_dataset" } ]}If you need to grant users access to multiple views, granting access to eachauthorized view can be both time consuming and harder to maintain. Instead ofcreating multiple authorized views, you can use anauthorized dataset to automatically authorize any views created in the authorized dataset.
Consume a data product
For most analytics use cases, consumption patterns are determined by theapplication that the data is being used in. The main use of a centrally providedconsumption environment is for data exploration before the data is used withinthe consuming application. As discussed inDiscover and consume products in a data mesh, SQL is the most commonly used method for querying data products. For this reason,the data platform should provide data consumers with a SQL application forexploration of the data.
Depending on the analytics use case, you may be able to use Terraform to deploythe consumption environment for data consumers. For example, data science is acommon use case for data consumers. You can use Terraform to deployVertex AI user-managed notebooks to be used as a data science developmentenvironment. From the data science notebooks, data consumers can use theircredentials to sign in to the data mesh to explore data to which they have accessand develop ML models based on this data.
To learn how to use Terraform to deploy and help to secure a notebookenvironment on Google Cloud, seeBuild and deploy generative AI and machine learning models in an enterprise.
Provide common services
In addition to self-service IaC components and solutions, the data platformteam might also take ownership over building and operating common sharedplatform services used by multiple data domain teams. Common examples of sharedplatform services include self-hosted third-party software such as businessintelligence visualization tools or a Kafka cluster. In Google Cloud, thedata platform team might choose to manage resources such as Dataplex Universal Catalogand Cloud Logging sinks on behalf of data domain teams. Managing resourcesfor the data domain teams lets the data platform team facilitate centralizedpolicy management and auditing across the organization.
The following sections show how to use Dataplex Universal Catalog for centralmanagement and governance within a data mesh on Google Cloud, and theimplementation of data observability features in a data mesh.
Dataplex Universal Catalog for data governance
Dataplex Universal Catalog provides a data management platform that helps you tobuild independent data domains within a data mesh that spans the organization.Dataplex Universal Catalog lets you maintain central controls for governing andmonitoring the data across domains.
With Dataplex Universal Catalog an organization can logically organize their data(supported data sources)and related artifacts such as code, notebooks, and logs, into aDataplex Universal Catalog lake that represents a data domain. In the followingdiagram, a sales domain uses Dataplex Universal Catalog to organize its assets,including data quality metrics and logs, into Dataplex Universal Catalog zones.
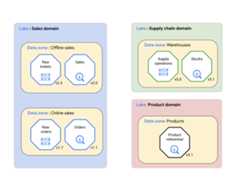
As shown in the preceding diagram, Dataplex Universal Catalog can be used tomanage domain data across the following assets:
- Dataplex Universal Catalog allows data domain teams to consistently managetheir data assets in a logical group called a Dataplex Universal Catalog lake.The data domain team can organize their Dataplex Universal Catalog assetswithin the same Dataplex Universal Catalog lake without physically moving dataor storing it into a single storage system. Dataplex Universal Catalog assetscan refer to Cloud Storage buckets and BigQuerydatasets stored in multiple Google Cloud projects other than theGoogle Cloud project containing the Dataplex Universal Catalog lake.Dataplex Universal Catalog assets can be structured or unstructured, or bestored in an analytical data lake or data warehouse. In the diagram, thereare data lakes for the sales domain, supply chain domain, and product domain.
- Dataplex Universal Catalog zones enable the data domain team to furtherorganize data assets into smaller subgroups within the sameDataplex Universal Catalog lake and add structures that capture key aspects ofthe subgroup. For example, Dataplex Universal Catalog zones can be used togroup associated data assets in a data product. Grouping data assets into asingle Dataplex Universal Catalog zone allows data domain teams to manageaccess policies and data governance policies consistently across the zoneas a single data product. In the diagram, there are data zones for offlinesales, online sales, supply chain warehouses, and products.
Dataplex Universal Catalog lakes and zones enable an organization to unifydistributed data and organize it based on the business context. This arrangementforms the foundation for activities such as managing metadata, setting upgovernance policies, and monitoring data quality. Such activities allow theorganization to manage its distributed data at scale, such as in a data mesh.
Data observability
Each data domain should implement its own monitoring and alerting mechanisms,ideally using a standardized approach. Each domain can apply the monitoringpractices described inConcepts in service monitoring, making the necessary adjustments to the data domains. Observability is a large topic, and isoutside of the scope of this document. This section only addresses patterns whichare useful in data mesh implementations.
For products with multiple data consumers, providing timely information to eachconsumer about the status of the product can become an operational burden. Basicsolutions, such as manually managed email distributions, are typically prone toerror. They can be helpful for notifying consumers of planned outages, upcomingproduct launches, and deprecations, but they don't provide real-time operationalawareness.
Central services can play an important role in monitoring the health and qualityof the products in the data mesh. Although not a prerequisite for a successfulimplementation of the data mesh, implementing observability features can improvesatisfaction of the data producers and consumers, and reduce overall operationaland support costs. The following diagram shows an architecture of data meshobservability based onCloud Monitoring.

The following sections describe the components shown in the diagram, which areas follows:
- Uptime checks to show the overall state of data products.
- Custom metrics to give helpful indicators about data products.
- Operational support by the central data platform team to alert data consumers of changes in the data products that they use.
- Product scorecards and dashboards to show how data products are performing.
Uptime checks
Data products can create simple custom applications that implementuptime checks. These checks can serve as high-level indicators of the overall state of the product.For example, if the data product team discovers a sudden drop in data quality ofits product, the team can mark that product unhealthy. Uptime checks that areclose to real time are especially important to data consumers who have derivedproducts that rely on the constant availability of the data in the upstream dataproduct. Data producers should build their uptime checks to include checking theirupstream dependencies, thus providing an accurate picture of the health of theirproduct to their data consumers.
Data consumers can include product uptime checks into their processing. Forexample, a composer job that generates a report based on the data provided by adata product can, as the first step, validate whether the product is in the"running" state. We recommend that your uptime check application returns astructured payload in the message body of its HTTP response. This structuredpayload should indicate whether there's a problem, the root cause of the problemin human readable form, and if possible, the estimated time to restore theservice. This structured payload can also provide more fine-grained informationabout the state of the product. For example, it can contain the healthinformation for each of the views in the authorized dataset exposed as aproduct.
Custom metrics
Data products can have various custom metrics to measure their usefulness. Dataproducer teams can publish these custom metrics to their designateddomain-specific Google Cloud projects. To create aunified monitoring experience across all data products, a central data mesh monitoring projectcan be given access to those domain-specific projects.
Each type of data product consumption interface has different metrics to measureits usefulness. Metrics can also be specific to the business domain. Forexample, the metrics for BigQuery tables exposed through views orthrough the Storage Read API can be as follows:
- The number of rows.
- Data freshness (expressed as the number of seconds before themeasurement time).
- The data quality score.
- The data that's available. This metric can indicate that the data isavailable for querying. An alternative is to use the uptime checksmentioned earlier in this document.
These metrics can be viewed as service level indicators (SLI) for a particularproduct.
For data streams (implemented as Pub/Sub topics), this list can bethe standard Pub/Sub metrics, which are available through topics.
Operational support by the central data platform team
The central data platform team can expose custom dashboards to displaydifferent levels of details to the data consumers. A simple status dashboardthat lists the products in the data mesh and uptime status for those productscan help answer multiple end-user requests.
The central team can also serve as a notification distribution hub to notifydata consumers about various events in the data products they use. Typically,this hub is made by creatingalerting policies. Centralizing this function can reduce the work that must bedone by each data producer team. Creating these policies doesn't require knowledgeof the data domains and should help avoid bottlenecks in data consumption.
An ideal end state for data mesh monitoring is for the data product tag templateto expose the SLIs and service-level objectives(SLOs) that the product supports when the product becomes available. The centralteam can then automatically deploy the corresponding alerting using servicemonitoring with the Monitoring API.
Product scorecards
As part of the central governance agreement, thefour functions in a data mesh can define the criteria tocreate scorecards for data products. These scorecards can become an objectivemeasurement of data product performance.
Many of the variables used to calculate the scorecards are the percentage oftime that data products are meeting their SLO. Useful criteria can be thepercentage of uptime, average data quality scores, and percentage of productswith data freshness that does not fall below a threshold. To calculate thesemetrics automatically usingPrometheus Query Language (PromQL), the custom metrics and the results of the uptime checks from the centralmonitoring project should be sufficient.
What's next
- Learn more aboutBigQuery.
- Read aboutDataplex.
- For more reference architectures, diagrams, and best practices, explore theCloud Architecture Center.
Except as otherwise noted, the content of this page is licensed under theCreative Commons Attribution 4.0 License, and code samples are licensed under theApache 2.0 License. For details, see theGoogle Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2024-09-03 UTC.