ML pipelines

Page Summary
Production Machine Learning prioritizes automated pipelines over individual models to accommodate evolving data and ensure accuracy through regular retraining.
Pipelines streamline the ML workflow by automating data collection, model training, validation, and deployment for enhanced efficiency and reliability.
Two primary pipeline functions exist: serving pipelines for delivering predictions and a combination of data, training, and validation pipelines for updating the model to combat staleness.
Model staleness varies based on data dynamism, necessitating training frequency adjustments, ideally with daily training and deployment as a best practice.
Version-controlled repositories are crucial for managing datasets, ensuring reproducibility, compliance, and auditability, while logging predictions and ground truth aids in monitoring model quality.
In production ML, the goal isn't to build a single model and deploy it. The goalis to build automated pipelines for developing, testing, and deploying modelsover time. Why? As the world changes, trends in data shift, causing models inproduction to go stale. Models typically need retraining with up-to-date data tocontinue serving high-quality predictions over the long term. In other words,you'll want a way to replace stale models with fresh ones.
Without pipelines, replacing a stale model is an error-prone process. Forexample, once a model starts serving bad predictions, someone will need tomanually collect and process new data, train a new model, validate its quality,and then finally deploy it. ML pipelines automate many of these repetitiveprocesses, making the management and maintenance of models more efficient andreliable.
Building pipelines
ML pipelines organize the steps for building and deploying models intowell-defined tasks. Pipelines have one of two functions: delivering predictionsor updating the model.
Delivering predictions
The serving pipeline delivers predictions. It exposes your model to the realworld, making it accessible to your users. For example, when a user wants aprediction—what the weather will be like tomorrow, or how many minutesit'll take to travel to the airport, or a list of recommended videos—theserving pipeline receives and processes the user's data, makes a prediction, andthen delivers it to the user.
Updating the model
Models tend to go stale almost immediately after they go into production. Inessence, they're making predictions using old information. Their trainingdatasets captured the state of the world a day ago, or in some cases, an hourago. Inevitably the world has changed: a user has watched more videos and needsa new list of recommendations; rain has caused traffic to slow and users needupdated estimates for their arrival times; a popular trend causes retailers torequest updated inventory predictions for certain items.
Typically, teams train new models well before the production model goes stale.In some cases, teams train and deploy new models daily in a continuous trainingand deployment cycle. Ideally, training a new model should happen well beforethe production model goes stale.
The following pipelines work together to train a new model:
- Data pipeline. The data pipeline processes user data to createtraining and test datasets.
- Training pipeline. The training pipeline trains models using the newtraining datasets from the data pipeline.
- Validation pipeline. The validation pipeline validates the trained modelby comparing it with the production model usingtest datasets generated bythe data pipeline.
Figure 4 illustrates the inputs and outputs of each ML pipeline.
ML pipelines

Figure 4. ML pipelines automate many processes for developing andmaintaining models. Each pipeline shows its inputs and outputs.
At a very general level, here's how the pipelines keep a fresh model inproduction:
First, a model goes into production, and the serving pipeline startsdelivering predictions.
The data pipeline immediately begins collecting data to generate newtraining and test datasets.
Based on a schedule or a trigger, the training and validationpipelines train and validate a new model using the datasetsgenerated by the data pipeline.
When the validation pipeline confirms the new model isn't worse than theproduction model, the new model gets deployed.
This process repeats continuously.
Model staleness and training frequency
Almost all models go stale. Some models go stale faster than others. Forexample, models that recommend clothes typically go stale quickly becauseconsumer preferences are notorious for changing frequently. On the other hand,models that identify flowers might never go stale. A flower's identifyingcharacteristics remain stable.
Most models begin to go stale immediately after they're put into production.You'll want to establish a training frequency that reflects the nature of yourdata. If the data is dynamic, train often. If it's less dynamic, you might notneed to train that often.
Train models before they go stale. Early trainingprovides a buffer to resolve potential issues, for example, if the data ortraining pipeline fails, or the model quality is poor.
A recommended best practice is to train and deploy new models on a daily basis.Just like regular software projects that have a daily build and release process,ML pipelines for training and validation often do best when ran daily.
Check Your Understanding
Serving pipeline
The serving pipeline generates and delivers predictions in one of two ways:online or offline.
Online predictions.Online predictionshappen in real time,typically by sending a request to an online server and returning aprediction.For example, when a user wants a prediction, theuser's data is sent to the model and the model returns the prediction.
Offline predictions.Offline predictionsare precomputedand cached. To serve a prediction, the app finds the cached predictionin the database and returns it. For example, a subscription-based servicemight predict the churn rate for its subscribers. The modelpredicts the likelihood of churning for every subscriber and caches it. Whenthe app needs the prediction—for instance, to incentive userswho might be about to churn—it just looks up the precomputedprediction.
Figure 5 shows how online and offline predictions get generated and delivered.
Online and offline predictions

Figure 5. Online predictions deliver predictions in real time. Offlinepredictions are cached and looked up at serving time.
Prediction post-processing
Typically, predictions get post-processed before they're delivered. For example,predictions might be post-processed to remove toxic or biased content.Classification results mightgo through a processto reorder results instead of showing the model's raw output, for instance,to boost more authoritative content, present a diversity of results,demote particular results (like clickbait), or remove results for legalreasons.
Figure 6 shows a serving pipeline and the typical tasks involved in deliveringpredictions.
Post-processing predictions
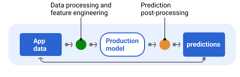
Figure 6. Serving pipeline illustrating the typical tasks involved todeliver predictions.
Note that thefeature engineeringstep is typically builtwithin the model and not a separate, stand-alone process. The data processingcode in the serving pipeline is often nearly identical to the data processingcode the data pipeline uses to create training and test datasets.
Assets and metadata storage
The serving pipeline should incorporate a repository to log model predictionsand, if possible, the ground truth.
Logging model predictions lets you monitor the quality of your model.By aggregating predictions, you can monitor the general quality of yourmodel and determine if it's starting to lose quality. Generally,the production model's predictions should have the same average asthe labels from the training dataset. For more information, seeprediction bias.
Capturing ground truth
In some cases, theground truthonly becomes availablemuch later. For example, if a weather app predicts the weather six weeksinto the future, the ground truth (what the weather actually is) won'tbe available for six weeks.
When possible, get users to report the ground truth by adding feedbackmechanisms into the app. A mail app can implicitly captures user feedback whenusers move mail from their inbox to their spam folder. However, this onlyworks when user correctly categorize their mail. When users leave spam intheir inbox (because they know it's spam and never open it), the trainingdata becomes inaccurate. That particular piece of mail will be labeled"not spam" when it should be "spam." In other words,always try to find waysto capture and record the ground truth, but be aware of the shortcomingsthat might exist in feedback mechanisms.
Figure 7 shows predictions being delivered to a user and logged to arepository.
Logging predictions
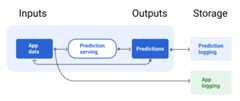
Figure 7. Log predictions to monitor model quality.
Data pipelines
Data pipelines generate training and test datasets from application data. Thetraining and validation pipelines then use the datasets to train and validatenew models.
The data pipeline creates training and test datasets with the same features andlabel originally used to train the model, but with newer information. Forexample, a maps app would generate training and test datasets from recenttravel times between points for millions of users, along with other relevantdata, like the weather.
A video recommendation app would generate training and test datasets thatincluded the videos a user clicked on from the recommended list (along with theones not clicked), as well as other relevant data, like watch history.
Figure 8 illustrates the data pipeline using application data to generatetraining and test datasets.
Data pipeline

Figure 8. Data pipeline processes application data to createdatasets for the training and validation pipelines.
Data collection and processing
The tasks for collecting and processing data in data pipelines will probablydiffer from theexperimentation phase (where you determined thatyour solution was feasible):
Data collection. During experimentation, collecting data typicallyrequires accessing saved data. For data pipelines, collecting data mightrequire discovering and getting approval to access streaming logs data.
If you need human-labeled data (like medical images), you'll need aprocess for collecting and updating it as well.
Data processing. During experimentation, the right features came fromscraping, joining, and sampling the experimentation datasets. For the datapipelines, generating those same features might require entirely differentprocesses. However, be sure to duplicate the data transformations from theexperimentation phase by applying the same mathematicaloperations to the features and labels.
Assets and metadata storage
You'll need a process for storing, versioning, and managing your training andtest datasets. Version controlled repositories provide the followingbenefits:
Reproducibility. Recreate and standardize model training environmentsand compare prediction quality among different models.
Compliance. Adhere to regulatory compliance requirements forauditability and transparency.
Retention. Set data retention values for how long to store the data.
Access management. Manage who can access your data through fine-grainedpermissions.
Data integrity. Track and understand changes to datasets over time,making it easier to diagnose issues with your data or your model.
Discoverability. Make it easy for others to find your datasets andfeatures. Other teams can then determine if they'd be useful for theirpurposes.
Documenting your data
Good documentation helps others understand key information about your data, likeits type, source, size, and other essential metadata. In most cases, documentingyour data in a design doc is sufficient.If you plan on sharing or publishing your data, usedata cardsto structure the information. Data cards make it easier for others to discoverand understand your datasets.
Training and validation pipelines
The training and validation pipelines produce new models to replace productionmodels before they go stale. Continually training and validating new modelsensures the best model is always in production.
The training pipeline generates a new model from the training datasets, and thevalidation pipeline compares the quality of the new model with the one inproduction using test datasets.
Figure 9 illustrates the training pipeline using a training dataset totrain a new model.
Training pipeline

Figure 9. The training pipeline trains new models using the mostrecent training dataset.
After the model is trained, the validation pipeline uses test datasets tocompare the production model's quality against the trained model.
In general, if the trained model isn't meaningfully worse than the productionmodel, the trained model goes into production. If the trained model is worse,the monitoring infrastructure should create an alert. Trained models with worseprediction quality could indicate potential issues with the data or validationpipelines. This approach works to ensure the best model, trained on the freshestdata, is always in production.
Assets and metadata storage
Models and their metadata should be stored in versioned repositories to organizeand track model deployments. Model repositories provide the followingbenefits:
Tracking and evaluation. Track models in production and understand theirevaluation and prediction quality metrics.
Model release process. Easily review, approve, release, or roll backmodels.
Reproducibility and debugging. Reproduce model results and moreeffectively debug issues by tracing a model's datasets and dependenciesacross deployments.
Discoverability. Make it easy for others to find your model. Other teamscan then determine if your model (or parts of it) can be used for theirpurposes.
Figure 10 illustrates a validated model stored in a model repository.
Model storage

Figure 10. Validated models are stored in a model repository for trackingand discoverability.
Usemodel cardsto document and share key information about your model, like its purpose,architecture, hardware requirements, evaluation metrics, etc.
Check Your Understanding
Challenges building pipelines
When building pipelines, you might encounter the following challenges:
Getting access to the data you need. Data access might requirejustifying why you need it. For example, you might need to explain how thedata will be used and clarify how personal identifiable information (PII) issues will be solved. Be preparedto show a proof-of-concept demonstrating how your model makes betterpredictions with access to certain kinds of data.
Getting the right features. In some cases, the features used in theexperimentation phase won't be available from the real-time data. Therefore,when experimenting, try to confirm that you'll be able to get the samefeatures in production.
Understanding how the data is collected and represented. Learning howthe data was collected, who collected it, and how it was collected (alongwith other issues) can take time and effort. It's important to understandthe data thoroughly. Don't use data you're not confident in to train a modelthat might go to production.
Understanding the tradeoffs between effort, cost, and model quality.Incorporating a new feature into a data pipeline can require a lot ofeffort. However, the additional feature might only slightly improve themodel's quality. In other cases, adding a new feature might be easy.However, the resources to get and store the feature might be prohibitivelyexpensive.
Getting compute. If you need TPUs for retraining, it might be hard toget the required quota. Also, managing TPUs is complicated. For example,some parts of your model or data might need to be specifically designed forTPUs by splitting parts of them across multiple TPU chips.
Finding the right golden dataset. If the data changes frequently,gettinggolden datasetswith consistent and accurate labels can be challenging.
Catching these types of problems during experimentation saves time. For example,you don't want to develop the best features and model only to learn they're notviable in production. Therefore, try to confirm as early as possible that yoursolution will work within the constraints of a production environment.It's better to spend time verifying a solution works rather than needingto return to the experimentation phase because the pipeline phase uncoveredinsurmountable problems.
Key Terms:Except as otherwise noted, the content of this page is licensed under theCreative Commons Attribution 4.0 License, and code samples are licensed under theApache 2.0 License. For details, see theGoogle Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2025-08-25 UTC.