LLMs: What's a large language model?

Page Summary
Large language models (LLMs) predict sequences of tokens and outperform previous models due to their vast number of parameters and broader context gathering capabilities.
Transformers, the leading architecture for LLMs, utilize encoders to process input and decoders to generate output, often for tasks like translation.
Self-attention, a core concept in Transformers, allows the model to weigh the importance of different words in relation to each other, enhancing context understanding.
LLMs are trained using masked predictions on massive datasets, enabling them to learn patterns and generate text based on probabilities.
While LLMs offer benefits like clear text generation, they also present challenges like hallucinations, computational costs, and potential biases.
A newer technology,large language models (LLMs)predict a token or sequence of tokens, sometimes many paragraphs worth ofpredicted tokens. Remember that a token can be a word, a subword (a subset ofa word), or even a single character. LLMs make much better predictionsthan N-gram language models or recurrent neural networks because:
- LLMs contain far moreparametersthan recurrent models.
- LLMs gather far more context.
This section introduces the most successful and widely used architecturefor building LLMs: the Transformer.
What's a Transformer?
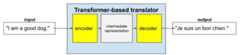
Transformers are the state-of-the-art architecture for a wide variety oflanguage model applications, such as translation:

Full transformers consist of an encoder and a decoder:
- Anencoder converts input text into an intermediate representation. An encoder is an enormousneural net.
- Adecoder converts that intermediate representation into useful text. A decoder is also an enormous neural net.
For example, in a translator:
- The encoder processes the input text (for example, an English sentence) intosome intermediate representation.
- The decoder converts that intermediate representation into output text (forexample, the equivalent French sentence).
Click the icon to learn more about partial Transformers.
This module focuses on full Transformers, which contain both an encoderand a decoder; however, encoder-only and decoder-only architectures alsoexist:
- Encoder-only architectures map input text into an intermediaterepresentation (often, anembedding layer).Use cases for encoder-only architectures include:
- Predicting any token in the input sequence (which is the conventional role of language models).
- Creating a sophisticated embedding, which could serve as the input for another system, such as a classifier.
- Decoder-only architectures generate new tokens from the text already generated. Decoder-only models typically excel at generating sequences;modern decoder-only models can use their generation power to createcontinuations of dialog histories and other prompts.
What is self-attention?
To enhance context, Transformers rely heavily on a concept calledself-attention.Effectively, on behalf of each token of input, self-attention asksthe following question:
"How much does each other token of input affect the interpretation of thistoken?"
The "self" in "self-attention" refers to the input sequence. Some attentionmechanisms weigh relations of input tokens to tokens in an output sequence likea translation or to tokens in some other sequence. Butself-attention onlyweighs the importance of relations between tokens in the input sequence.
To simplify matters, assume that each token is a word and the completecontext is only a single sentence. Consider the following sentence:
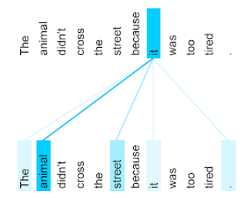
The animal didn't cross the street because it was too tired.
The preceding sentence contains eleven words. Each of the eleven words ispaying attention to the other ten, wondering how much each of those ten wordsmatters to itself. For example, notice that the sentence contains the pronounit. Pronouns are often ambiguous. The pronounit typically refers to arecent noun or noun phrase, but in the example sentence, which recent noundoesit refer to—the animal or the street?
The self-attention mechanism determines the relevance ofeach nearby word tothe pronounit. Figure 3 shows the results—the bluer the line, the moreimportant that word is to the pronounit. That is,animal is moreimportant thanstreet to the pronounit.
Conversely, suppose the final word in the sentence changes as follows:
The animal didn't cross the street because it was too wide.
In this revised sentence, self-attention would hopefully ratestreet asmore relevant thananimal to the pronounit.
Some self-attention mechanisms arebidirectional, meaning that theycalculate relevance scores for tokenspreceding andfollowing the word beingattended to. For example, in Figure 3, notice that words on both sides ofit are examined. So, a bidirectional self-attention mechanism can gathercontext from words on either side of the word being attended to. By contrast, aunidirectional self-attention mechanism can only gather context from wordson one side of the word being attended to. Bidirectional self-attention isespecially useful for generating representations of whole sequences, whileapplications that generate sequences token-by-token require unidirectionalself-attention. For this reason, encoders use bidirectional self-attention,while decoders use unidirectional.
What is multi-head multi-layer self-attention?
Each self-attention layer is typically comprised of multipleself-attentionheads. The output of a layer is a mathematical operation (for example,weighted average or dot product) of the output of the different heads.
Since the parameters of each head are initialized to random values, differentheads can learn different relationships between each word being attended to andthe nearby words. For example, the self-attention head described in the previoussection focused on determining which noun the pronounit referred to.However, other self-attention heads within the same layer might learn thegrammatical relevance of each word to every other word, or learn otherinteractions.
A complete transformer model stacks multipleself-attention layers on top ofone another. The output from the previous layer becomes the input for the next.This stacking allows the model to build progressively more complex and abstractunderstandings of the text. While earlier layers might focus on basic syntax,deeper layers can integrate that information to grasp more nuanced concepts likesentiment, context, and thematic links across the entire input.
Click the icon to learn about Big O for LLMs.
Self-attention forces every word in the context tolearn the relevance of all the other words in the context. So, it is temptingto proclaim this an O(N2) problem, where:
- N is the number of tokens in the context.
As if the preceding Big O weren't disturbing enough, Transformerscontain multiple self-attention layers and multiple self-attention heads perself-attention layer, so Big O is actually:
O(N2 · S · D)
where:
- S is the number of self-attention layers.
- D is the number of heads per layer.
Click the icon to learn more about how LLMs are trained.
You probably will never train an LLM from scratch. Training anindustrial-strength LLM requires enormous amounts of ML expertise,computational resources, and time. Regardless, you clicked the icon tolearn more, so we owe you an explanation.
The primary ingredient in building an LLM is a phenomenal amountof training data (text), typically somewhat filtered. The first phaseof training is usually some form ofunsupervisedlearning on that training data.Specifically, the model trains onmasked predictions, meaning thatcertain tokens in the training data are intentionally hidden. The model trainsby trying to predict those missing tokens. For example, assume the followingsentence is part of the training data:
The residents of the sleepy town weren't prepared for what came next.
Random tokens are removed, for example:
The ___ of the sleepy town weren't prepared for ___ came next.
An LLM is just a neural net, so loss (the number of masked tokens themodel correctly considered) guides the degree to which backpropagation updatesparameter values.
A Transformer-based model trained to predict missing data graduallylearns to detect patterns and higher-order structures in the data to get cluesabout the missing token. Consider the following example masked instance:
Oranges are traditionally ___ by hand. Once clipped from a tree, __ don't ripen.
Extensive training on enormous numbers of masked examples enable an LLMto learn that "harvested" or "picked" are high probability matches for thefirst token and "oranges" or "they" are good choices for the second token.
An optional further training step calledinstructiontuning can improve an LLM's ability to follow instructions.Why are Transformers so large?
Transformers contain hundreds of billion or even trillions ofparameters.This course has generally recommended building models with a smallernumber of parameters over those with a larger number of parameters.After all, a model with a smaller number of parameters uses fewer resourcesto make predictions than a model with a larger number of parameters.However, research shows that Transformers with more parametersconsistently outperform Transformers with fewer parameters.
But how does an LLMgenerate text?
You've seen how researchers train LLMs to predict a missing word or two, and youmight be unimpressed. After all, predicting a word or two is essentially theautocomplete feature built into various text, email, and authoring software.You might be wondering how LLMs can generate sentences or paragraphs orhaikus about arbitrage.
In fact, LLMs are essentially autocomplete mechanisms that can automaticallypredict (complete) thousands of tokens. For example, consider a sentencefollowed by a masked sentence:
My dog, Max, knows how to perform many traditional dog tricks.___ (masked sentence)
An LLM can generate probabilities for the masked sentence, including:
| Probability | Word(s) |
|---|---|
| 3.1% | For example, he can sit, stay, and roll over. |
| 2.9% | For example, he knows how to sit, stay, and roll over. |
A sufficiently large LLM can generate probabilities for paragraphs and entireessays. You can think of a user's questions to an LLM as the "given" sentencefollowed by an imaginary mask. For example:
User's question: What is the easiest trick to teach a dog?LLM's response: ___
The LLM generates probabilities for various possible responses.
As another example, an LLM trained on a massive number of mathematical "wordproblems" can give the appearance of doing sophisticated mathematical reasoning.However, those LLMs are basically just autocompleting a word problem prompt.
Benefits of LLMs
LLMs can generate clear, easy-to-understand text for a widevariety of target audiences. LLMs can make predictions on tasks they areexplicitly trained on. Some researchers claim that LLMs can also makepredictions for input they werenot explicitly trained on, but otherresearchers have refuted this claim.
Problems with LLMs
Training an LLM entails many problems, including:
- Gathering an enormous training set.
- Consuming multiple months and enormous computational resources andelectricity.
- Solving parallelism challenges.
Using LLMs toinfer predictions causes the following problems:
- LLMshallucinate,meaning their predictions often contain mistakes.
- LLMs consume enormous amounts of computational resources and electricity.Training LLMs on larger datasets typically reducesthe amount of resources required for inference, though the larger trainingsets incur more training resources.
- Like all ML models, LLMs can exhibit all sorts of bias.
Exercise: Check your understanding
Except as otherwise noted, the content of this page is licensed under theCreative Commons Attribution 4.0 License, and code samples are licensed under theApache 2.0 License. For details, see theGoogle Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2026-01-02 UTC.