Lambdaカクテル
京都在住Webエンジニアの日記です
Facebookが開発した圧縮アルゴリズムZstandardについて調べた(非常に高速)(今日から使えます)
Common Lispの処理系であるSBCLをインストールしようとしたら、追加でlibzstd-develというのを新たに要求されるようになっていた。見るからに圧縮系のライブラリだけれど聞き慣れないのでちょっと調べてみた。
ちょろっと調べたところ、以下のことが分かった:
- Zstandard(ゼットスタンダード?)というのが正式な名前。
- Facebookが開発した。
- Deflateよりも速いことを主眼においている。
- BSDライセンス。
- Linuxカーネルまわりで使えるようになっているほか、一部のディストロではパッケージの圧縮フォーマットとして使われているようだ。
- Webというよりはどちらかといえばバックエンド的な箇所で使われている印象がある。
zstd コマンド使ってみた
他の名だたる圧縮アルゴリズム同様、Linuxで直接ファイルに対してこれを実行して圧縮するためのバイナリが用意されている。zstdでリポジトリを検索すれば、大抵のディストロには入っているみたいだ。
使い方はgzipとかxzとかと大して変わらなくて、ファイルを渡せば圧縮される。gzipなどと違って勝手に元ファイルを置換したりはしないという差異があった。
動画を圧縮させる
適当にそのへんにあった3GiBくらいの録画ファイル(内容は、昨日のNHKの7時のニュースを録画したM2TSファイル)を圧縮させた:
$ du foo.m2ts3317243 ...$ time zstd foo.m2tszstd 14.27s user 4.24s system 134% cpu 13.792 total$ du foo.m2ts.zst3075652 ...
94%くらいになった。
同じことを、deflateアルゴリズムを使っているgzipにやらせてみる:
$ time gzip foo.m2ts > foo.m2ts.gzgzip -c > 124.46s user 2.16s system 99% cpu 2:06.76 total$ du foo.m2ts.gz3075624 ...
ほぼ同じサイズになったが、かなり時間がかかった。というかzstdがめちゃくちゃ速い。
テキストを圧縮させる
録画ではなく、テキストっぽいファイルも圧縮させてみる。とはいえ巨大なテキストを持ち合わせていないので、手元にあるEmacsの設定ディレクトリを全部TARにつめこんだ。これはおおむね巨大なテキストと呼んでもさしつかえないのではないか。で、これをzstdとgzとで圧縮させることにした。
$ du -d0 .619956$ cd ../$ tar -cvf emacs.tar emacsd$ du emacs.tar598064$ time zstd emacs.tarzstd emacs.tar 1.39s user 0.54s system 144% cpu 1.338 total$ du emacs.tar.zst448852
75%くらいになった。gzipでも試してみる:
$ time gzip -c emacs.tar > emacs.tar.gzgzip -c emacs.tar > emacs.tar.gz 17.46s user 0.36s system 99% cpu 17.814 total$ du emacs.tar.gz471256
zstdほど小さくならなかったし、かなり遅かった。timeの様子を見るに、マルチコアを活かせていない雰囲気がある。
zstdコマンド良さそう /tar からも呼び出せます
結論として、なかなか使い勝手の良さそうなコマンドという印象を受けた。かなり速くてそこそこのサイズに圧縮できてめでたい。
ところでtarから直接zstdが使えると楽しそう、と思ったところ、最近のtarではtar acf foo.tar.zst foo/のように書く(つまり、zの代わりにaを使ってアルゴリズムを自動判定させる)ことで直接呼び出せるようになっている。もしくは--zstdと書くと良いみたい。以下の記事によればzstdの自動認識はtar 1.31以降で対応している:
比較のコーナー
折角なので、いくつかの圧縮アルゴリズムを比較して、データを取ってみることにした。
アルゴリズムとファイルとの組み合わせを網羅してくれるScalaスクリプトを書く。zstdとgzに加えて、xz、bzip2、そして最近各種ブラウザがサポートしているbrotliを比較することにした。
#!/usr/bin/env ammimport scala.concurrent.duration.FiniteDurationimport $ivy.`org.typelevel::cats-core:2.8.0`import $ivy.`io.circe::circe-core:0.14.1`import $ivy.`io.circe::circe-generic:0.14.1`import os.Pathval pwd = os.pwdval FILES: Seq[Path] = Seq(pwd /"emacsd2.tar", pwd /"video.m2ts")finalcaseclass Result(command:String, file:String, originalSize: Long, compressedSize: Long, durationSeconds: Long)@main def main() = {import cats.implicits._import io.circe._, io.circe.syntax._, io.circe.generic.auto._val compressionMap = Map("zstd" -> zstd,"gz (deflate)" -> gz,"bzip2" -> bz2,"xz" -> xz,"brotli" -> brotli, )val runner = (command: (String, (Path => Path)), file: Path) => {val (compressed, dur) = time(command._2(file))val size = os.size(compressed) Result(command._1, file.toString, os.size(file), size, dur.toSeconds) }val result = (compressionMap.toSeq, FILES) mapN { runner }// write as JSON lines (line-separated JSON objects) result map ( _.asJson.noSpaces ) foreach ( println _ )}val zstd = (file: Path) => { os.proc("zstd", file).call() Path(file.toString +".zst")}val gz = (file: Path) => { os.proc("gzip","-k", file).call() Path(file.toString +".gz")}val bz2 = (file: Path) => { os.proc("bzip2","-k", file).call() Path(file.toString +".bz2")}val xz = (file: Path) => { os.proc("xz","-k", file).call() Path(file.toString +".xz")}val brotli = (file: Path) => { os.proc("brotli","-k","-q","5", file).call() Path(file.toString +".br")}
Scalaスクリプトについては以下の拙著記事を参考。
これを実行してシャワーを浴びていると以下のようなJSON Linesが得られた*1:
{"command":"gz (deflate)","file":"emacsd2.tar","originalSize":612413440,"compressedSize":482561907,"durationSeconds":19}{"command":"gz (deflate)","file":"video.m2ts","originalSize":3322680040,"compressedSize":3149433518,"durationSeconds":132}{"command":"xz","file":"emacsd2.tar","originalSize":612413440,"compressedSize":427691276,"durationSeconds":204}{"command":"xz","file":"video.m2ts","originalSize":3322680040,"compressedSize":2846310580,"durationSeconds":1295}{"command":"zstd","file":"emacsd2.tar","originalSize":612413440,"compressedSize":459619827,"durationSeconds":1}{"command":"zstd","file":"video.m2ts","originalSize":3322680040,"compressedSize":3149463466,"durationSeconds":14}{"command":"bzip2","file":"emacsd2.tar","originalSize":612413440,"compressedSize":471944261,"durationSeconds":57}{"command":"bzip2","file":"video.m2ts","originalSize":3322680040,"compressedSize":3125718016,"durationSeconds":312}{"command":"brotli","file":"emacsd2.tar","originalSize":612413440,"compressedSize":450331830,"durationSeconds":11}{"command":"brotli","file":"video.m2ts","originalSize":3322680040,"compressedSize":3099375473,"durationSeconds":76}
これをさらにPandas / Seabornで可視化する。Pandasのread_jsonは、lines = Trueを渡すことによってJSON Linesをパースできるので覚えておくと便利ですよ。
import pandasas pdimport seabornas snsimport matplotlib.pyplotas pltdf = pd.read_json("result.jsonl", lines=True)print(df)sns.set_theme(style="whitegrid")ax = sns.barplot(df.query('file == "video.m2ts"'), x="file", y="durationSeconds", hue="command")for iin ax.containers: ax.bar_label(i,)plt.legend(loc='upper right')plt.savefig("./result-video-dur.png")
あとはファイル名の部分などをちびちび入れ替えながらグラフを生成した。作業用マシンになぜかpandasとかが入っていなくて、それをインストールする時間が一番苦痛でした。
ビデオを圧縮
ビデオはそもそもあまり冗長なデータが出現しないのか、軒並みだいたい同じくらいのサイズになった。LZMAアルゴリズムを使うxzがめちゃくちゃ頑張りを見せた。

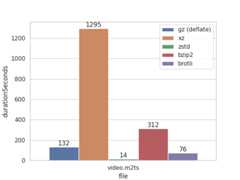
zstdがそこそこの圧縮率の割にものすごい速度を出している。
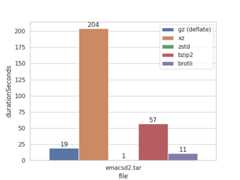
テキストを圧縮
テキスト圧縮はbrotliがかなりコスパの良さを見せた。brotliはHTMLやJS等に登場する語彙をあらかじめ格納した辞書を圧縮に使うため、ランタイムのサイズ(辞書のサイズが120KBくらいらしい)と引き換えに高圧縮率を誇る。そして、それよりも遥かに高速なzstdもすごい。

圧縮率 / 必要な秒数
圧縮率を秒数で割ることで、総合的な時間あたりのコスパが見えてくる。

やはりzstdのコスパの良さが目立つ。特にテキストデータではコスパがとても良い。brotli圧縮は特にテキストを圧縮する場合に効力を発揮するようだ。あとはどこまで圧縮率を強めたいかで考えることになるのではないかと思う。
見ていない箇所
メモリフットプリントなどの要素は見ていません。また、一部が破損した場合にリカバーするためのユーティリティがどれだけ充実しているか、といった要素も見ていません。例えば、bzip2は修復用のユーティリティであるbzip2recoverを持っていたりします。
まとめ
バッチ処理といったユースケースで速度が欲しいときはかなり優秀な選択肢になるのではないかと思いました。日頃の作業でちょっと圧縮して何かをしたいときも、時間を節約しつつそこそこの圧縮率が出るので便利だと思います。大抵のディストロに入っているし、今すぐ使えそうです!
*1:絶対パスが冗長だったので、そこだけ手で直しています