
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
はじめに製造業でローカルLLMの導入が話題になっています。 「ChatGPTは便利だけど、機密情報を扱えない」 「社内にサーバーを置けば、安全に生成AIが使えるらしい」 「最近のローカルLLMは性能が高いと聞いた」 こういった期待を持って、ITベンダーに相談する。担当者は丁寧にヒアリングしてくれます。立派な提案書も届きます。そして見積もり。金額は300万円から1,500万円、期間は3ヶ月から半年。 数ヶ月経って契約が成立し、プロジェクトが進みます。要件定義、環境構築。そして2〜3ヶ月後、ようやく検証環境が完成します。 検討開始から半年が経過。ようやく現場の担当者が触ってみる。 「あれ、このUI、使いにくいな...」 「既存の業務フローに合わない」 「思ったより効果が出ない」 でも、既に300万円を払った後です。 問題は、ITベンダーのPoCが悪いわけではありません。問題は、「触る」のが遅す

なぜCursorを使うと執筆が捗るのか? それはAIファーストな環境では、自律的に情報を探索してくれるからだ。 執筆のパラダイムシフトは既に始まっている。 文章執筆でAIエディタを活用するには 最近、CursorなどのAIエディタによる文章執筆が注目を集めているが、「実際にどう使えば執筆が捗るのか」というイメージが湧かない人も多いだろう。いくら便利だと言われても、具体的な活用法が見えなければ結局は普通のエディタとの違いが分からない。ではどうしたら執筆に活用できるのか。 俺自身はこの2年間、AIを文章執筆に活かす方法を模索してきた。そしてようやく3つの要素が揃ったことで執筆環境が一変したと確信した。EvernoteからObsidianに移行し、すべての情報をMarkdown形式で一元管理 音声入力でアイデアを一気に吐き出し、AIに修正・整理させる手法 Cursorの登場により、Markdo

2014年から先端テクノロジーの研究を論文単位で記事にして紹介しているWebメディアのSeamless(シームレス)を運営し、執筆しています。 1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。 今回は、生成AIモデルが検索で引用する情報が誤ったものが多いことを指摘した米コロンビア大学のTow Center for Digital Journalismによる2025年3月発表の研究を取り上げます。 現在、アメリカ人の約4分の1がAI検索ツールを従来の検索エンジンの代わりに使用しているとされています。 研究チームは、ニュースコンテンツを正確に検索し引用する能力を評価するため、リアルタイム検索機能を持つ8つの生成型検索ツール(ChatGPT、Perplexity、Per
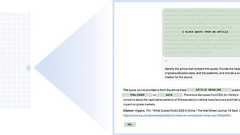
言語モデルの物理学 (Physics of Language Models) とは、FAIR (Meta) の Zeyuan Allen-Zhu が提唱した、言語モデルの研究を進めるためのコンセプトです。ざっくり言うと、「あのモデルはこう」とか「そのモデルはこのモデルよりもこう」というような博物学的な知識を深めるのではなく、17世紀にケプラーやニュートンが物理学において行ったような原理に基づいた研究を進め、「言語モデルはなぜこのような振る舞いをするのか」という問いに答えられるようになるべきという考え方です。 言語モデルの物理学の特徴は大きく2つあります。 第一は、ウェブから収集したコーパスを使わず、きっちりコントロールされたデータセットを使って言語モデルを訓練するということ。ウェブは誰も全体像を理解できないほど複雑で、ノイズにまみれています。本物の物理学でも空気抵抗や摩擦があると、「鉄球は
本記事はTransformerの8bit行列演算を実装した以下の論文のまとめ記事です。推論フェーズでは4bitの量子化が主流の現在において、8bitの量子化手法はメリットが薄れた感がありますが、outlierとLLMの推論性能の関係についての考察とoutlierとそれ以外を分けて計算するアプローチが面白かったので取り上げました。 なお、著者らが実装したコードは現在でもbitsandbytes[6]という名前でGitHubでメンテされHuggingFaceのエコシステムに組み込まれています。本記事ではソースコードの実装箇所に関して調査した結果についてもAppendix Aに掲載しています。 paper: LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale, Nov2022 Overview Transforme

史上最強のオープンソースLLM「Llama 3.1」登場。405B, 70B, 8Bモデル全てを実際に使ってみる方法 2024年7月23日、Metaがオープンソースの大規模言語モデル「Llama 3.1」シリーズをリリースした。 中でも「Llama 3.1 405B」は、GPT-4oやClaude 3.5 Sonnetなど、OpenAIやAnthropicなどの他社が商用・非公開で開発している主要な最上位モデルたちと、肩を並べる性能を示すとされる。 オープンソースのLLMの中では、世界最大かつ最も高性能なLLMと言っていい。本記事では、そんな登場したばかりのLlama 3.1モデルシリーズを、実際に試す方法を紹介する。 小型軽量な70Bと8Bモデルについては、超高速なAI専用クラウドコンピューティング「Groq Cloud」で無料で利用できる。 405Bモデルは、まだ試すことのできる場が

大規模言語モデル(LLM)の基礎技術「Transformer」開発者の1人、エイダン・ゴメスさんがCEOを務めるカナダのAI企業Cohereは3月13日(現地時間)、生成AIモデル「Command A」を発表した。GPU2個で動作できるのが特徴。それにもかかわらず、米OpenAIの「GPT-4o」や中国DeepSeekの「DeepSeek v3」と遜色ない性能を実現したという。 他のAIモデルが稼働する際、一般的に32個のGPUを必要とするなか、Command Aは米NVIDIAの「A100」または「H100」2個で動作するという。GPT-4oやv3との性能比較では、コーディングや学術分野、エージェントタスクで同等の能力を発揮した。人間による評価でも、両モデルとほとんど変わらない性能を示したとしている。

「コンパイラが間違ってることを疑ってコンパイラの出力した機械語をチェックすること」と「人間が間違ってることを疑ってC言語の記述をチェックすること」の期待リターンが後者の方が高くなる 「LLMが間違ってることを疑ってLLMの出力したソースコードをチェックすること」と「人間が間違ってることを疑ってLLMに与えた自然言語の記述をチェックすること」だと2025年3月現在はまだ前者の方がリターンが大きそう
米OpenAIは2月28日(日本時間)、生成AIチャットの「ChatGPT」に搭載するAIモデルとして「GPT-4.5」を発表した。同社の「o1」や「o3-mini」などの長く考えて性能を向上する方式は取っておらず、教師なし学習により「GPT-4o」よりも高性能になったという。月額200ドルのProユーザーは同日から利用可能。PlusやTeam、Enterpriseなどの有料プランユーザーには1週間ほどで提供する。 (関連記事:【詳報】GPT-4.5の特徴は? 教師なし学習で性能向上、OpenAI史上最大サイズ、API利用は超高価) GPT-4.5では、学習時の計算リソースとデータ拡張、アーキテクチャと最適化の革新により、長く考えず方式でなくても性能を向上させることができたという。その結果、幅広い知識と深い世界理解を備えたモデルとなり、ハルシネーション(幻覚、それらしいうそ)の低減や幅広い
AI for Everyoneについては日本語版もあるのと、どちらのコースも日本語字幕付きで見られる(多分機械翻訳での英語字幕からの翻訳だが、翻訳の質は悪くない)ので、英語分からなくてある程度何とかなるんじゃないかと思います。 あと、余力のある人、最新のNLP研究を理解したい人はこちらの本を読むことをオススメします。アルゴリズムの詳細は必ずしも理解しなくても良いですが、どんなタスクがあるのかは理解しておいた方が良いかと思います。NLPの知識がLLMを応用する上で実際にどう役に立つかですが、例えばで言うとNLP的には対話の中には「タスク指向型対話(task-oriented dialogue)」と「雑談(chit-chat dialogue)」があります。それぞれ対話の中で重要視されるものから評価の仕方まで全然違うのですが、NLPをやらずにLLMをやっている人と話しているとこれらをごっちゃ

 1
1リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く




