
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
Go言語で書かれたorderedmapというサードパーティパッケージがあります。github.comGoのmapには順序がなく、JSONをデコードすると順序が失われ、それをエンコードするとオブジェクトのキーの順序にソートされます。 これに困る人はそこそこいるようで、順序を保持するmapはいくつか実装されてきました。 その中の一つが、orderedmapというパッケージです。 シンプルなインターフェイスが気に入っています。 orderedmapパッケージの利用例 package main import ( "encoding/json" "fmt" "log" "github.com/iancoleman/orderedmap" ) func main() { src := `{ "z": 1, "x": 2, "y": 3 }` fmt.Println("#map[string]in
When you open a document with an encoding different than the oneit wascreated with,it's not possible to display the originaltext, and instead a garbled mess of corrupted characters are printed out. These are called "mojibake" inJapanese, and the word has also been borrowed into English. While mojibake aren't readable by humans,it turns out that different kinds of mojibake have different visu
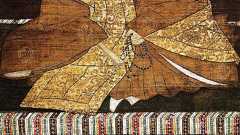
UnicodeのUTF-16エンコーディングではほとんどの文字(コードポイント)は2バイトで表現されるが、Unicodeに後から追加収録された文字の多くは4バイトで表現される。4バイト文字がうまく扱えないプログラムというのはわりとよくある。しかし世界中で広く使われるようになった絵文字がよりによって4バイト文字であるせいで、そのような文字が扱えない問題がよいペースで解決に向かいつつある。それについて少し説明してみようと思う。 Unicodeが80年代から90年代初頭にかけてデザインされたときの目標の一つは、Unicodeに含まれる文字数を65536個以内に収めることだった。現代の文章を実用的なレベルで表すためには、漢字などを含めてもそれだけの種類の文字があれば十分だと考えられたのだ。当然これは1文字を2バイトで表すことを念頭に置いていた。つまりコンピュータの揺籃期から当時に至るまで単純に英語

この記事は MERPAYTECH OPENNESS MONTH の 1 日目の記事です。 メルペイでソフトウェアエンジニアやっている @syu_cream です。 メルペイバックエンドシステムにおけるデータ・ログ収集と活用を促進するためのシステム DataPlatform の仕事をしています。本記事ではこの DataPlatform で用いているデータフォーマット Apache Avro について、簡単な紹介とメルペイにおける導入背景、そして利用事例を示していきます。 ビッグデータ処理基盤においてフォーマット選定は頭を悩まされる課題かと思います。 ログフォーマット選定やスキーマ管理について、少しでもなにか得られるものがあれば幸いです。 Apache Avro の簡単な紹介 Apache Avro はデータがバイナリエンコードされる、軽量で柔軟なデータフォーマットです。 筆者としては B

Healthcare Custom EHR,EMR, ERX, and other types of medical software products Read moreLogistics & Supply Chain Benefit from our in-depth proficiency in devising digital solutions for the transportation industry Read more Industrial IoT solutions Yalantis delivers industrial IoT solutions, device integration, and application development for smart manufacturing. Read more

Pythonでは、複雑なデータの交換や保管する場合、よく Pickleモジュール が使われます。Pickleはデータを外部に出力可能な形式に変換してファイルに変換したり、サーバと通信して送信したりします。Pythonのconcurrent.futures や multiprocessing を使って並列処理を行う場合も、プロセス間のデータ交換に Pickle が使われています。 PEP-574 Pickle protocol 5 with out-of-band data Pickleは汎用的なデータフォーマットを定義していて、データを作成したハードウェアと異なるアーキテクチャのハード上で読み込んでも、ただしく元のデータを再現できるようになっています。 しかし、現在ではPickleの使い方は多様化しており、そういった汎用的なデータフォーマットだけでは効率的にデータの転送や保管を行えないこ
RESTfulAPIのデータフォーマットなどで広く使われているJSON。IETFはJSON仕様「RFC 8259」を発表。従来の仕様をブラッシュアップしつつECMAの仕様との統一も実現した、事実上最後のJSON仕様になると見られる。 IETFからJSON(ジェイソン)の仕様を示した「RFC 8259」(TheJavaScript Object Notation (JSON) Data Interchange Format)が公開されました。 IETFにおけるJSON仕様は、これまで「RFC 7159」が参照されていましたが、RFC 8259の公開によりRFC 7159は廃止(Obsolete)となりました。 RFC 8259は、多数の実装と十分な運用実績を積み重ねたインターネット標準「STD 90」としても参照されます。 ECMAとの統一を実現。事実上最後のJSON仕様になると見られる

iOS 10.3 でAPFSが本番投入されました。それでiPhoneやiPadが文鎮化するなどの深刻な問題はみられなかったものの、やはり無問題とはいかなかったようで。 iOS10.3で不具合の出るアプリは、APFS関連の影響かも(Unicode Normalizationの振る舞いが変わったらしい)。GoodReaderとDropboxの同期でエラーが出るようになったのだが、ファイル名に濁点を含むファイルを除いたら同期できるように。 — 山路達也 (@Tats_y) March 29, 2017 原因を調べてみました。 # !/usr/bin/envperl use strict; use warnings; use feature ':all'; use Encode; use Unicode::Normalize; use utf8; binmode STDOUT, ':utf8';

MacでPDFからコピペした時のNFD問題の対策。MacでPDFからコピペした文字が、濁点/半濁点が離れる。 「お読みください」 「お読みくた゛さい」Macのファインダーのコピーだと見た目的な違いが無いので判別が難しい。 原因MacOSのファイルシステムであるHFS+が使用している、UTF-8の正規化方法が「NFD」というもので、2文字に分けて正規化されてしまうことが原因。Mac でPDF からコピーした濁点/半濁点付きの文字列を Firefox に貼り付けた時におかしくなる問題の対処方法 対策とどこでクリアするか? NFD → NFCに変換をする。 nkf(Network Kanji Filter)で変換が可能。UTF-8にもいろいろある どこで? コピーした時点で変換する。 タスクランナーに組み込んで変換する。 とりあえずの前者の仕組みをMacのAutomaterでシェル

Unicode正規化(ユニコードせいきか、英語: Unicode normalization)とは、等価な文字や文字の並びを統一的な内部表現に変換することでテキストの比較を容易にする、テキスト正規化処理の一種である。一般に、正規化はテキストの文字列を検索や整列のために比較(照合、英語: collation)するときに重要である[1]。 Unicodeの正規化手段の基礎は、文字の合成と分解という概念である。文字の合成とは、基底文字と結合文字の組み合わせによる結合文字列を、単一の符号位置である合成済み文字にする手続きである。たとえば、基底文字 n と結合文字 ~ の組み合わせを単独の ñ 文字に変換する、仮名文字と濁点の結合文字の組み合わせを単独の濁点つき仮名とするなど。分解はその逆で、合成済み文字を結合文字列にする。分解は単一の符号位置を別の単一の符号位置に変換することもある。 Unicod
Test Cases for HTTP Content-Disposition header field (RFC 6266) and the Encodings defined in RFCs 2047, 2231 and 5987 Please send feedback tojulian.reschke@gmx.de. Related Reading Header Encoding RFC 2047 -- "MIME (Multipurpose Internet Mail Extensions) Part Three: Message Header Extensions for Non-ASCIIText" RFC 2231 -- "MIME Parameter Value and Encoded Word Extensions: Character Sets, Language
選定作業にはAOMが公開しているソフトウェアエンコーダaomを使用し、改造によってツールを削減したときの映像品質を比較しました。 映像品質は一般的にビットレートと客観/主観画質のバランスで表されます。 客観画質とは計算によって数値化した画質のことで、代表的な手法としてはPSNRやSSIMがあります。 主観画質とは人の目で映像を評価した画質のことです。 今回は、客観画質としてPSNRを用いた指標(RD性能)を用い、映像品質を比較しました。 PSNRには"30dBを下回ると低品質である"といった基準はありますが、人の目で見たときの評価と必ずしも一致するわけではありません。 そこで、主観画質の評価も並行して実施し、多角的に映像品質低下を防止しました。 選定結果 まず、Superblockサイズを64X64と128X128とで比較しました。 その結果、テストケースのうち約75%でRD性能に変化がな

zip ファイルは最近の仕様ではUTF-8 でファイル名を格納できるのですが、多くの場合レガシーな環境依存文字コードでファイル名が格納された形式が使われています。日本語の場合はWindows に合わせて Shift-JIS (cp932) が使われることが多いです。Python 2 ではzipfile モジュールが返すファイル名はバイト文字列だったのでそのまま cp932 のファイル名が返ってきたのですが、Python 3 では文字列が Unicode に統一されたため、zip ファイルを読み込むとファイル名がデコードされて文字列になって返ってきます。 が、もちろん日本語の慣習がデフォルトの挙動になってるわけではないので、このままでは文字化けしてしまいます。Python 3.4 のzipfile モジュールを読むと次のようになっていました。

いつまでたってもエンジニアを悩ませる問題として「文字コード」があります。 その中でも質が悪いのがMicrosoft ページコード 932 いわゆるWindows-31J だと思います。 Unicode がだいぶ普及したとは言え、まだまだ根深い問題です。本稿では Shift_JIS とWindows-31J の違いについてまとめてみたいと思います。 とは言え筆者自身、Shift_JIS やWindows-31J などが誕生した当時にリアルタイムで歴史を見てきた人間ではありませんので、あくまでWikipedia をベースに筆者なりにまとめたという点をご了承ください。 (誤りがあった場合にはご指摘頂ければ幸いです) Shift_JIS (CP932) の誕生 Shift_JISは、漢字を含む日本語を表現できる文字コードとして1982年に誕生しました。 Shift_JIS はマイクロソ
Deleted articles cannot be recovered. Draft of this article would be also deleted. Are you sure you want to delete this article?40歳目前の中年エンジニアが独りよがりにUnicodeとの思い出を書き綴ってみる。 記憶をベースに細かいことを気にせずに大枠の雰囲気が伝わるように書いてみる。 なぜUnicode? 先日MySQLのバージョンアップを行ったが、その時にCharacter setをutf8からutf8mb4に変換した。MySQLを普段使わない人はutf8mb4なに?と思うかも知れません。そうです、これはMySQL固有のものです。 どうやらMySQLは永らくUTF8は1文字が1~3バイトであることが前提の実装になっていた。 で、4バイトな文字が登場して、「

Python 2 に比べるとずっと楽になったものの、環境によってはPython 3 で予期せぬ UnicodeError に遭遇することがあります。Python 3.6 時点での、Python の各種エンコーディングの扱いを整理してみます。Python のエンコーディング filesystem encoding (sys.getfilesystemencoding()) 主にファイルパスに使うエンコーディングですが、コマンドライン引数にも使われます。 (そうでないとファイルパスをコマンドライン引数に渡したときに困る) また locale が関連するので、実際にはそれ以外にも glibc とかと連携するときに使われます。Python 2 時代の名残りでしょうが、今では filesystem encoding というより system encoding と呼んだほうが実態を表している

こんにちは、hachi8833です。 少し前に、babaさんから「Rubyの内部文字コードはUTF-8じゃないよ」とツッコミがありました。 (追記: 上は会話の途中から切り取りましたのでご了承ください) いきなりの展開にくらくらきましたが、babaさんはさらにたたみかけます。 こうしたことはとっくにご存じの方も多いと思いますが、「Rubyといえば2.0以来UTF-8完全対応なんじゃないの」と勝手に思い込んでた私は脳に掌底を食らったような思いです。ああ、でもこういうことがあるから面白い。 ⚓ プログラミング言語と内部文字コードの関係 まず最初に押さえておきたい点です。プログラミング言語で文字コードに関連する部分は、「文字列」「正規表現」「入出力」「コード中の文字リテラル(""の中など)」「コード中の文字リテラル以外の要素(変数名など)」「ファイル名」などが中心になります。そして文字列に関連し

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く







