
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く

「AI処理のボトルネックは演算ではなく、メモリアクセスにある」。そんなタイトルでインテル主催の「Intel Connection 2024」で講演を行なったのは、東京大学 特別教授の黒田忠広氏だ。AIの課題である電力消費とボトルネックを解消すべく、インテルのような北米企業と日本の企業、アカデミアはいま何をすべきか。黒田氏は持論を展開した。 GDP比0.6%の第三期成長期に向かうAI時代の半導体産業 Intel Connection 2024のセッションにおいて、スーパーコンピューター富岳プロジェクトのリーダーである松岡聡センター長からマイクを引き継いだのは、東京大学教授で半導体研究者でもある黒田忠広氏だ。最初に説明したのは、半導体産業の成長について。家電で用いられていた程度だった半導体の市場は1990年代はGDP比0.2%程度だったが、PC市場やインターネットが勃興した1995年頃に0.4

自分の認識をだらだら書くとこうなる。 結局のところ2003年から2011年頃までいちばん延べ計算量が必要だったのはリアルタイムの3Dグラフィックスのレンダリングだったんだ。そこではNVIDIAって会社がPCゲームのプラットフォームを握ってしまっていてそこで技術開発をめっちゃ進めてしまったんだ。 結果的にPlayStation2までは純日本設計だったグラフィックチップが、PlayStation3ではNVIDIAのGPUになってしまったんだ。そこで負けが確定してしまった感じだ。PlayStation3のCPU、CELLに内蔵されているSPUは、世代をどんどん進めていったら最終的にレンダリングもできるグラフィックチップに進化する可能性があったのかもしれないけど次世代が出せなかったのでそこで終わりになってしまった。 NVIDIAは先端を走っているユーザーが何を求めているかをめちゃくちゃちゃんと調査

負荷を抑えて高品質? スマホゲームのグラフィックスを進化させるためにゲームエンジン「Frostbite」が取り組む「FP16化」とは ライター:西川善司 2024年3月に行われたGDC 2024で,「FP16 Shaders in Frostbite」という一風変わったテーマを掲げていたセッションがあった。 簡単に言えば,Electronic Arts(以下,EA)の独自開発ゲームエンジン「Frostbite」で,16bit浮動小数点数(FP16)を徹底活用して性能を改善できるか検討したというものだ。 セッションを担当したAlexis Griffin-Lira氏(Software Engineer,Frostbite. EA)。Frostbiteエンジン開発チームの一員だ 近代ゲームグラフィックスでは,頂点シェーダが扱うジオメトリ(幾何学)的な演算において,単精度と呼ばれる32bit浮動小

GPU禁輸措置で追い詰められる中国と大規模言語モデルの発展2023.11.01 Updated by Ryo Shimizu on November 1,2023, 09:15 am JSTアメリカがGPUを重要物資として中国に対して禁輸措置を行うとの意向を受けて、中国国内ではA800GPUの価格が一枚あたり50万人民元(約1000万円)に達するなどのパニックが起きたようだ。これは通常の価格の5倍にあたる。 A800は、そもそもアメリカ政府の意向を受けて中国市場向けにデチューンした(性能をわざと落とした)モデルで、世界的ベストセラーのA100の70%程度の性能とされている。 しかし中国国内ではAI開発が非常に活発であり、合法的に使えるA800を大量に確保したい中国側の事情と、軍事転用も可能な重要戦略物資を中国に売りたくないアメリカ政府の意向が真正面から対立する形となっている。 筆者
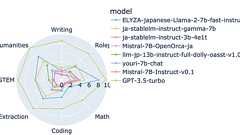
はじめにTuring 株式会社のリサーチチームでインターンをしている東京工業大学 B4 横田研究室の藤井(@okoge_kaz)です。 自然言語処理分野における大規模深層学習の重要性は日に日に高まっていますが、GPT-3, GPT-4 などのモデルの学習には膨大な計算コストがかかり、容易に学習できなくなっています。実際、モデルサイズが近年急速に大きくなっていることにより、学習に必要な計算量(FLOPs)は以下のように年々膨大になっています。近年の大規模モデルでは、NVIDIA H100 80GB であっても 1 つのGPU では、モデルをのせることすらできません。 ComputeTrends Across Three Eras ofMachine Learning より またScaling Laws によると、大規模なモデルは小さいモデルと比較してより優れた性能を発揮するため、自動

Apple’s latestline ofMacs includes their in-house “M1” system-on-chip, featuring a customGPU. This poses a problem for those of us in the AsahiLinux project who wish to runLinux on our devices, as this customAppleGPU has neither public documentation nor open source drivers. Some speculateit might descend from PowerVRGPUs, as used in olderiPhones, while others believe theGPU to be comple
infoThis documentation is a work-in-progress. Use.GPU is inalpha. warning_amberWebGPU is only available in certain browsers. Use.GPU is a set of declarative,reactive WebGPU legos. Compose live graphs, layouts, meshes and shaders, on the fly.It's a stand-aloneTypescript+Rust/WASM library withits ownReact-like run-time. If you're familiar withReact, you will feel right at home.It has a built
Stable Diffusion が来てるねってことで貧者のGPU であるところのColaboratory でいろいろ試したいのだけどノートブック上でPython のコードをこまごまいじりながら試行錯誤するのは微妙に体験が悪い。 ちょっとしたウェブサービスとして立てて実行できるとよいけれど、なかなかクラウドサービスも帯に短し襷に長しという感じでGPU を気軽に借りられるところはなさそうだ……と思ったら、Colab 上に HTTP サーバを立てられることを知ったので、その方法でやってみることにする。 やってみたソースは以下。GitHub - motemen/stablediffusion-server-on-colab README にあるノートブックを開いて Huggingface のトークンを埋め、GPU を選択して実行するとサーバが起動する。サーバが起動する前のセルに表示され

ARMの誕生 ~Sinclair、BBCからNewton、Symbianへ~:RISCの生い立ちからRISC-Vまでの遠い道のり(1/4 ページ) ※現在Armの正しい表記は“大文字A+小文字rm”であるが、今回ご紹介する内容の時期はまだ大文字の“ARM”の時代だったので、あえて“ARM”と記述させていただいた。アメリカではハイパフォーマンス路線に突き進むMIPSやその競合メーカーが一斉にRISCに飛びつくが、それとは別の動きがイギリスで生まれていた。 1978年、CPU(Cambridge Processor Unit) Ltd.という会社がイギリスのケンブリッジで創業した。厳密に言えば、そもそもSinclair ZX80とか、後にはZX Spectrumを世に送り出したクライブ・マールズ・シンクレア卿が興したSoC(Science of Cambridge:もともとはSinclair

渡辺名人が購入した130万円のパソコン、クラウドでそれと同じ性能のもの、1時間50円で使えるよとツイートしたらえらくバズった。 上のツイートは、決して渡辺名人の研究を揶揄するものではなく、書き方次第で最低にも最高にも聞こえるという、そういう物事の二面性みたいなのって面白いよねという意味でツイートしたわけである。 しかし「クラウドの料金そんなに安くねーだろ」「それってGPUだけの値段ですよね?」「値段一桁間違えてない?」「クラウド使ったことない奴の妄想乙」みたいなツッコミをたくさん頂戴している。
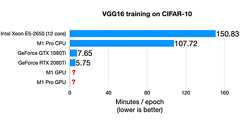
Today,PyTorch officially introducedGPU support forApple’s ARM M1 chips. This is an exciting day forMac users out there, so I spent a few minutes tonight tryingit out in practice. In this shortblog post, I will summarize my experience and thoughts with the M1 chip for deep learning tasks. My M1 Experience So Far Back at the beginning of 2021, I happily sold my loud and chunky 15-inch Intel Ma
はじめに 昨年12月にこんなツイートを見かけました。 かわいいですね。幸いにして論文と実装が公開されていたので、自分でもやってみようと思って、その結果を書いたのが前回の記事です。 読んでいただければわかるとおり、前回の記事の中ではGPUを使わずにアルゴリズムやデータ構造を工夫して近似的に計算しています。結果の画像についてはそんなに悪くないと思っていますが、限界もありました。パーティクルの数も少ないし、一部の画像ではうまく行きませんでした。 やっぱり、もっとちゃんとネコチャンを点描してみたいですよね。 なので、今回の記事ではGPUを使ってアルゴリズムを再現し、よりヴィヴィッドなネコチャンの点描を作成しようと思います。GPUを使って計算するために、WebGPUのRust実装であるwgpuを使用します。ネコチャンの画像を点描にしたい人と、WebGPUに入門してcompute shaderで何か計

概要 こんにちは、機械学習エンジニアの古賀です。 最近、人の動きを時系列で解析するためにグラフデータを扱ったのですが、データ量が大きくなると解析に時間がかかってしまい、効率が悪いと感じることがありました。 そんな中、cuGraph という高速にグラフ分析ができるライブラリが あることを知ったので、どれくらい高速なのか、有名なページランクの計算を題材に他のライブラリと速度を比較してみました。 目次は以下です。 概要 グラフとはPython によるグラフデータの分析 cuGraphとは ページランクとは ページランク値の定義 ページランクとグラフ 検証 実行環境 cuGraph ライブラリのインストール ライブラリのインポート データセット 検証内容・結果 1.NetworkX のグラフ、NetworkX のアルゴリズムを用いてページランクを計算 2.NetworkX のグラフ、cuGr

TheJuliaprogramming language is well-suited forGPU computing thanks to the CUDAnative.jl package, which enables nativeGPUprogramming and generates efficient PTX code.CUDAnative.jl reuses theJulia compiler, avoiding the need for a custom toolchain and keeping the hardware support package small, with only 1300lines of code.The performance ofJulia forGPU computing is comparable to statically

(Disclosure: While I work forGoogle, this is not an officialGoogle product or announcement.) tl;dr: ForJulia onColab withGPUs, first open thisnotebook and run the cell (takes ~15-20 minutes), then open this one to start usingJulia. Recently, @denizyuret brought up onSlack thatit would be nice ifGoogleColab supportedJulia, especially forGPUs. I can’t promise anything about official or

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く







