
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
Voicebox:Text-Guided Multilingual Universal Speech Generation at ScaleWe present Voicebox, a state-of-the-art speech generative model built upon Meta’s non-autoregressive flow matching model. By learning to solve atext-guided speech infilling task with a large scale of data, Voicebox outperforms single purposeAI models across speech tasks through in-context learning. Voicebox can synthesize spe

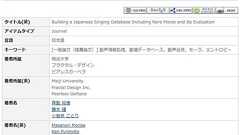
声優の小岩井ことりさんは9月15日、明治大学の森勢将雅専任准教授らと共同執筆した論文が電子情報通信学会で船井ベストペーパー賞を受賞したと発表した。作曲で音声合成分野の研究に貢献した。 受賞した論文は「レアなモーラを含む日本語歌唱データベースの構築と基礎評価」。著者は小岩井さん、森勢専任准教授、ライターの藤本健さん。内容は、AI歌声合成技術などの研究に使えるオリジナル曲を集めたデータベースを作成したというもの。 収録したオリジナル曲には、日本語の音素をできる限り含んだ歌詞、さまざまなパターンのメロディーが織り込んである。これまで歌声合成の分野では、著作権などの問題から童謡を使うことが多かったが、オリジナル曲のみでデータベースを構築することで利用条件の緩和を目指した。
はじめに 事前準備 ソースコード 実装の概要と動かし方 補助的に作成したモジュールの概要 おまけ:訓練済みモデルのリリース 環境音合成実験 音響イベントによる条件付けなし 音響イベントによる条件付けあり 実装の舞台裏とかTIPS おわりに 参考文献 はじめに 下記の雑誌論文が最近出版された。 Yuki Okamoto, Keisuke Imoto, Shinnosuke Takamichi, Ryosuke Yamanishi, Takahiro Fukumori and Yoichi Yamashita, "Onoma-to-wave: Environmental Sound Synthesis from Onomatopoeic Words", APSIPA Transactions on Signal and Information Processing: Vol. 11: No.
シロワニさん氏が趣味で開発したというWindows向けのAIトークソフト「COEIROINK(コエイロインク)」が無料で公開されています。COEIROINKは連絡不要で商用利用もOKなフリー素材キャラクター・つくよみちゃんに好きなテキストを誰でも簡単に読み上げてもらうことが可能なので、自作アニメやボイスドラマのキャラクターボイス、実況動画や解説動画のナレーションなどの作成にお役立ちです。 COEIROINK https://coeiroink.com/ ✨COEIROINKリリース✨ 無料の音声合成エンジン「#COEIROINK」が登場! 文章を読み上げます! ■公式サイト⇒https://t.co/66YStrCYu0 ■COEIROINK開発:シロワニさん様 @shirowanisan ■VOICEVOX開発:ヒホ様 @hiho_karuta 第1弾は「#つくよみちゃん」! 商用利用O

はじめまして、AI システム部の森紘一郎です。音声チームにおいて音声合成をはじめとする音声技術に関する研究開発を担当しています。本記事では、TechCon2020 で発表予定だった内容についてブログ記事にまとめました。 このPart1の記事では音声合成に関する取り組みについて紹介します。また、 Part2の記事 では音声変換に関する取り組みについて紹介します。音声合成のデモは こちら から確認できます。 概要 バーチャルキャラクターやスマートスピーカーなど音声を活用した新たなアプリケーションが広がっています。近年、発展が著しい深層学習は音声分野にも導入が進んでおり、自分好みの声で好きな言葉を喋らせることや、男性の声を女性の可愛らしい声に変換することが可能になってきました。本記事では、最新の音声AI技術を紹介するとともに、音声合成のエンターテインメント分野への導入の試みについて紹介します

2017年、米Googleや米Amazonなどの「スマートスピーカー」と呼ばれるデバイスの普及が日本で始まった。例えば、「ねえGoogle、今日の予定は?」と話しかけると、カレンダーアプリに入力していた予定を流ちょうな日本語で読み上げてくれる。中に人がいるわけではない。デバイスが人の声を認識し、応答となる声を合成しているのだ。 このデバイスが音声で応答するために使用しているコアの技術は、「音声認識」と「音声合成」という2つの技術だ。音声認識は人の声の波形を機械で処理し、どんな文であったかを推定する技術。音声合成は与えられた文やデータから、人が話す音声を合成する技術だ。 ここに、音声認識で推定した文に対して適切な応答文を出力する「対話制御」という技術が加わり、「人の話を聞いて適切な応答を音声で返す」という一連の動作を実現している。音声認識・合成ともに、コンピュータを利用した研究は1950年

目次 (背景)自分の声を結月ゆかりにしたい。前回はあまりクオリティが良くなかったので、手法を変えて質を上げたい。 (手法)声質変換を、低音質変換と高音質化の二段階に分けてそれぞれ学習させた。画像分野で有名なモデルを使った。 (結果)性能が飛躍的に向上し、かなり聞き取れるものになった。 (考察)精度はまだ改善の余地があり、多対多声質変換にすることで精度が向上すると考えられる。今回の結果を論文化したい。 デモ動画 背景多くの人が可愛い女の子になりたいと思っている。 CG技術やモーションキャプチャ技術の向上により、姿は女の子に仮想化できるようになってきた。 しかし、声に関してはまだまだ課題が多い。 声質変換は「遅延」「音質」「複数話者」などの難しい課題がある。 今回は、自分の声を結月ゆかりにするための、低遅延で実現可能な高音質声質変換を目指した。 手法大きく分けて3つの工夫をした。 画像ディープ
昨年はGoogle DeepMindが開発した音声合成用のネットワーク, WaveNetが話題になりましたが、その先をいく仕組みが今後公開されようとしています。Lyrebirdというカナダのスタートアップ企業が開発したテクノロジーです. まずは以下のデモをお聞きください. オバマ、トランプ、ヒラリーとアメリカの政治家の声が見事に再現されています。 この仕組みのすごいのは、1分ほどの声の録音があればそこからその人の声質を再現できるという部分.さらに録音ファイルの音質は問わないとのこと. スタートアップのファウンダーをみると、WaveNetの次にでてきた同様の音声合成のモデル SampleRNNの論文の著者が含まれていました。憶測ですが、SampleRNNの技術が使われているのかもしれません(未確認)。ただし、SampleRNNのときは音声の合成に実時間以上の時間がかかっていたはずですが、Ly

これはドワンゴ Advent Calendar 2017の9日目の記事です。漫画やアニメを見ていると、可愛い女の子になって可愛い女の子と他愛もない会話をして過ごす日常に憧れます。 そんな感じで、可愛い女の子になりたい人は多いと思います1。 しかし残念なことに、現在の技術で真の可愛い女の子になるのはとても難しいです。 じゃあせめて仮想でいいから可愛い女の子になりたいですよね(バーチャルyoutuberキズナアイみたいな)。 しかし、仮に姿を可愛い女の子にしても、声が可愛くなければ願いは叶いません。 ということで、声を可愛くする声質変換を目指してみました。 今回は僕の声をDeepLearningの力を借りて結月ゆかりにしました。 お勉強まずは音声の勉強をします。 これが一番時間かかりました。 最近の音声合成手法は3種類あります。 音響特徴量+vocoder wavenet STFT+位相推定
 1
1リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く




