
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
(映像もつくりました) 正規表現ガチャ(英語名:Regech)という、正規表現から生成されるランダムな文字列でガチャを引ける投稿サイトをNext.jsで個人開発した話です。 筆者について 今までPHPやjQueryで開発をしてきた19歳です。 制作期間は20日ほどです。 もしよければ、読んで・遊んでいってもらえたら嬉しいです! つくったもの 正規表現にマッチするランダムな文字列を生成するアプリです。 例:(にゃん?)+→にゃにゃんにゃんにゃおもしろいガチャができたら投稿することでみんなで遊べるようになります。 ぜひ、おもしろいガチャを作って投稿してください! 正規表現の学習にもおすすめです。英語対応もしてみたので英語環境からアクセスするか、/en/にアクセスすると英語でも見れます。 私のおすすめガチャ 私のおすすめです。他にもおもしろいガチャが投稿されているので遊んでみてください! リ

9月からRuby開発チームにインターンシップとして参加している@makenowjustです。 総合研究大学院大学の学生で、普段は情報セキュリティに関する研究をしています。 インターンシップでは、キャッシュ (メモ化) を利用したRubyの正規表現の高速化を行いました。 ReDoSと呼ばれる、バックトラックが爆発することでマッチング時間が膨大になる脆弱性があります (ReDoSについては、拙作ですがWEB+DB PRESSに掲載された記事があります)。 近年、ReDoSは多く報告されており、Rubyもその例外ではありません (参考1、参考2)。 今回実装した最適化は、ReDoSを防ぐことを目的としたもので、多くの正規表現のマッチング時間が文字列の長さに対して線形となります。 ReDoSが起こる正規表現の例として、/^(a|a)*$/が挙げられます。 今回の修正の前後での実行時間を比較すると、



GMO NIKKOのT.Iです。今回は当社のTRUE データフィードで使用している正規表現検索の効率化についての記事となります。前提(背景と目的)まずは宣伝(笑)当社公式サイトでは上記となっていますが、簡単にいうと・クライアントからデータを預かる・預かったデータを広告媒体毎のフォーマットの変換する・変換したデータを指定された場所に送信するということをやっています。その中のデータの変換時に禁止文言が入ったデータを行ごと除外するということをやっています。大量のデータに禁止文言が入っているかをチェックする必要がある... この記事では、複数文字列の探索について、正規表現よりもトライ木を使った方が速いことを確かめます。最初に問題設定を共有します。次に忙しい人向けにベンチマークの結果を発表します。実装言語に関する注意を挟んで、力まかせな実装を提示します。続いて、正規表現について簡単に説明し、正規表現
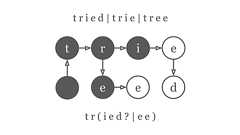
GMO NIKKOのT.Iです。 今回は当社のTRUE データフィードで使用している正規表現検索の効率化についての記事となります。 前提(背景と目的) まずは宣伝(笑) 当社公式サイトでは上記となっていますが、簡単にいうと ・クライアントからデータを預かる ・預かったデータを広告媒体毎のフォーマットの変換する ・変換したデータを指定された場所に送信する ということをやっています。 その中のデータの変換時に禁止文言が入ったデータを行ごと除外するということをやっています。 大量のデータに禁止文言が入っているかをチェックする必要があるのですが、 初期想定では精々10万件に対して100~1000個の禁止文言をチェックする程度(1億回程度)で十分と判断していました。 ですが運用後に禁止文言が3万を超えてしまい、チェック処理が10万件×3万=30億回のチェックを行う場合があり、処理時間がかなり長くなっ

 1
1リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く




