
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
みなさんこんにちは。 資料デザインのリサーチや分析に取り組むパワーポイントのスペシャリスト、パワポ研です。 いつも企業が出しているパワーポイントの分析結果などを紹介しているのですが、本日は上質なパワーポイントの宝庫である経済産業省の委託調査報告書について、格納場所と素晴らしい理由を紹介します。 委託調査報告書のパワポはどこにあるのかそのままですが、経産省のHPにあります。以下のURLより「委託調査報告書」を確認ください。ご存じの方も多いかもしれませんね。 トップはこんなページになっています。 トップ的なページこの中で、例えば「令和4年度分の掲載一覧(PDF形式:48KB)」を押してみましょう。 令和4年度分の掲載一覧こんな感じのリストがずらっと並べます。エクセルでも同じようなものがダウンロードできます。正直見づらいですが、このリンクの一つ一つが調査報告書になっています。 成果報告資料がなぜ

以前こんな記事を書いたことがあります。 「社員全員Excel経営」で名高い、ワークマン社のサクセスストーリーを論評したものです。2012年にCIOに就任した土屋哲雄常務のリーダーシップのもと、取引データの完全電子化を皮切りに「全社員がExcelを使いこなして数字とデータで経営する」戦略へと移行し、社内のExcelデータ分析資格を一定以上取得しないと管理職に昇進できないとか、はたまた幹部クラスの企画・経営会議ではデータに基づかない議論や提案は相手にすらされないとか、「Excelを社員全員が使えるようになるだけでもここまで企業カルチャーは変わり得るのか」という事例のオンパレードで、関連記事や書籍を読んでいて舌を巻いたのを覚えています。まさしく「ワークマンのすごいデータ活用」だったのです。 一方、個人的に強く印象を受けたのが土屋常務が様々なところでコメントしていた「我が社には突出したデータサイエ

標準 ベイズ統計学 朝倉書店Amazon 発刊当時に話題になっていた『標準ベイズ統計学』。実は訳者のお一人、菅澤翔之助さんからオフィス宛てでご恵贈いただいていたのですが、親父の没後処理やら自分のDVTやら実家の片付けやらで全く手が回らずオフィスに置いたままにしてしまっていたのでした。で、この度改めて拝読してみたら「何故もっと早く読まなかったんだ」と後悔するくらいあまりにも内容が素晴らしかったので、遅まきながら書評記事を書こうと思い立った次第です。 ベイズ統計学というと、殆ど詳しくない人だと「ベイズの定理以外に何があるの?」という印象ぐらいしかないかもしれませんし、一方でとりあえず技法としてやり方だけ覚えてしまった人だと「とりあえずMCMC回せばいいんだよね?」みたいな雑な理解になってしまうかもしれません。いずれにせよこれまで邦書ではベイズ統計学というと超初歩か実装重視かの二択が多かったせい


[重要なお知らせ (2023/8/12)] 現在,スライドの p.10 に不十分な記述があります.ルートの答えは 0 以上の数に限定することに注意してください (たとえば -3 を 2 乗しても 9 ですが,ルート 9 は -3 ではありません).なお,現在筆者のパソコンが修理中でデータがないので,修…

import numpy as np import scipy from scipy.stats import binom %matplotlib inline %config InlineBackend.figure_format = 'svg' import matplotlib import matplotlib.pyplot as plt import seaborn assns print("numpy version :", np.__version__) print("matplotlib version :", matplotlib.__version__) print("sns version :",sns.__version__) numpy version : 1.18.1 matplotlib version : 2.2.2sns version : 0.8.1
![[確率思考の戦略論] 1.確率理論の導入とプレファレンスの数学的説明](/image.pl?url=https%3a%2f%2fcdn-ak-scissors.b.st-hatena.com%2fimage%2fsquare%2f1c2288eb344765bc26ac66fb71d3ea3b95ee9641%2fheight%3d288%3bversion%3d1%3bwidth%3d512%2fhttps%253A%252F%252Fwayama.io%252Fimages%252Favatar.webp&f=jpg&w=240)
政府の経済財政諮問会議で、30代半ばから50代半ばの世帯の所得が20年余り前の同世代と比べて100万円以上減少していたとする調査結果が報告され、岸田総理大臣は、所得の向上に向けて、きめ細かく人への投資に取り組む考えを強調しました。 総理大臣官邸で開かれた経済財政諮問会議には、岸田総理大臣のほか、鈴木財務大臣や山際経済再生担当大臣らが出席し、所得の向上と人的資本の強化などについて、意見が交わされました。 この中で内閣府の担当者は、年代別の世帯の所得の変化について、バブル崩壊後の1994年と2019年を比べた調査結果を報告しました。 それによりますと世帯の所得の中央値は、いわゆる「就職氷河期」世代を含む35歳から44歳の世代では104万円減少していたほか、45歳から54歳の世代では184万円減少していたとしています。 また、25歳から34歳の若い世代の単身世帯では、所得が比較的低い200万円台

世界銀行による男女格差の調査で日本の順位が80位から103位に落ちたとのこと。 https://nordot.app/871377521626415104 具体的な内容がわからなかったので、世界銀行が公開しているデータを見てみた。 元データプレスリリースはこちら https://www.worldbank.org/en/news/press-release/2022/03/01/nearly-2-4-billion-women-globally-don-t-have-same-economic-rights-as-men このリンクから各国別のデータが置かれたページに飛ぶことができる。 日本はこれ https://wbl.worldbank.org/en/data/exploreeconomies/japan/2022 このページを見るとわかるとおり、得点はMobility, Workpl

選挙速報で、8時の投票〆切と共に、各TV局・新聞などのメディアが出す開票速報。 まだ開票もされていないのに議席数が大筋で判明したり、既に当確が出たりするのは何故だと疑問に思う人が結構いるようで。 そういった人達向けとして、統計学の重要さを説いた説明文が非常に解りやすいと話題になっておりました。

(※ 新しい予測を公開しました→ 東京の感染者数を5週間ぶん予測した (6月28日版)) いまこの瞬間にあなたがコロナに感染したとしても、潜伏→発症→検査→確定のタイムラグがありますから、1人の感染者数として発表されるのはずっと先のことです。つまり、ある程度先の未来は、「いま感染したばかりの人々」によってすでに決まっていると言えます。 ここでは、人々の緊張感と行動に影響する「3週前の感染者数の最大値」と、感染に影響する「2週前の人流」という、いずれもこれまで比較的高い相関を示してきたデータを元に、すでに決まっているはずの近い未来である2週ぶんについて、感染者数の推移を予測しました。さらに、予測した結果得られる「今後の感染者数の最大値」を二段ばしごのように活用し、計5週ぶんの未来まで予測しています。(ただし、3週目から先は、いまから変えられる未来でもあります) あれこれ条件を変えたシミュレー
本で読んだ知識をドヤ顔で紹介したら、その実験には再現性がありませんでした。 そんな恥ずかしい記事を書いたブロガーは誰でしょう? そう、私です。 ステレオタイプ脅威はありますん ちょっと前に「ステレオタイプ脅威」の記事が話題になっていた*1。 世の中には「女性は数学に弱い」というような負のステレオタイプがある。自分のアイデンティティがそれに該当していると意識してしまうと、実際にパフォーマンスが落ちるというものだ。これは様々な実験の結果によって示されている。というのが記事で紹介されていた話だった。 ところが現在、その「実験結果」は再現性が無いと言われている。ステレオタイプ脅威の根拠は実験結果にあるというのに、その土台は不確かなものであるのだ。 とくに、最近の研究ではほとんど再現性がないとされている「ステレオタイプ脅威」について、リベラルバイアスにも言及しながら議論しているのが印象的。 日本では

2021/9/10 追記: 改めて更新された話を統合して整理して書き直しました. 以降はこちらを参考にしてください: ill-identified.hatenablog.com 2021/1/15 追記: RStudio 1.4 がリリースされたのでなるべくアップデートしましょう 2020/12/06 追記: Japan.R で今回の話の要約+新情報を『Mac でもWindows でも, PNG でもPDF でもRのグラフに好きなフォントで日本語を表示したい (2020年最終版)/Display-CJK-Font-in-Any-Gpraphic-Device-and-Platform-2020 - Speaker Deck』として発表した. ハイライトは「近々出るRStudio 1.4 があれば fontregisterer はほぼいらなくなる」 2020/10/31 追記: geom

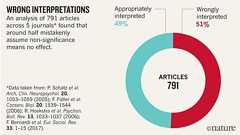
「統計的に有意差がないため、2つのデータには差がない」──こんな結論の導き方は統計の誤用だとする声明が、科学者800人超の署名入りで英科学論文誌「Nature」に3月20日付で掲載された。調査した論文の約半数が「統計的有意性」を誤用しており、科学にとって深刻な損害をもたらしていると警鐘を鳴らす。 「統計的に有意差がない=違いがない」は間違い 例えば、ある薬の効能を調べたいとする。統計学では一般的に「仮説検定」を行って薬を与えたグループとそうでないグループを比較し、薬効の指標となる何らかのパラメータに統計的有意差があるかどうかを見る。仮説検定は、2つの事象の差異が偶然生じたものかどうかを統計的に結論付けるものだ。 もし、統計的有意差がある(薬を与えた群のパラメータの方が有意に大きい)なら「薬には効能がある」という結論を導けるが、有意差がなかった場合はどうだろうか。 「統計的有意差がある=薬効

薬や医療機器の生産実態をまとめた統計で、コンドームの生産量が1か月に4億個を超えたとする誤りがあったことがわかり、厚生労働省が修正しました。 厚生労働省によりますと、この統計では、平成21年12月分に報告された1か月のコンドームの生産量が4億7538万個となっていました。 同じ年の1年間の生産量を上回っていて、インターネット上の匿名のブログで不自然だと指摘され、発覚したということです。 実際の生産量は10分の1以下で、メーカーからの報告の内容に誤りがあったということです。 厚生労働省は29日に修正を行いました。厚生労働省は「お騒がせして申し訳ありません。統計の信頼性の確保に努めていきます」としています。

Executive Summary 統計の信頼性について疑問を呈した柳下毅一郎のツイートを、山形は一蹴した。が、その後勤労統計の集計方法の不備が露見した。ここから、この統計は捏造であり、それが相関しているならすべての統計が捏造だ、という極論を述べたブログが出た。しかし統計は、一かゼロか、完璧かすべて捏造か、というものではない。またその相互の関係も、機械的な関係があるということではない。信頼性の非常に広い幅の中で上下するだけなので、実際にどんな不備があってどのくらい影響を及ぼすのかを具体的に考えないと、妥当性のない陰謀論に流れてしまうだけだ。 はじめに しばらく前に、柳下毅一郎がこんなツイートをした。 アベノミクスで経済がよくなってるとおっしゃるリフレ派の方々は、なぜ財務省の出す経済指標は捏造されてないと信じられるのだろうか。— Kiichiro Yanashita (@kiichiro)

厚生労働省が今年から賃金の算出方法を変えた影響により、統計上の賃金が前年と比べて大幅に伸びている問題で、政府の有識者会議「統計委員会」は二十八日に会合を開き、発表している賃金伸び率が実態を表していないことを認めた。賃金の伸びはデフレ脱却を掲げるアベノミクスにとって最も重要な統計なだけに、実態以上の数値が出ている原因を詳しく説明しない厚労省の姿勢に対し、専門家から批判が出ている。 問題となっているのは、厚労省が、サンプル企業からのヒアリングをもとに毎月発表する「毎月勤労統計調査」。今年一月、世の中の実態に合わせるとして大企業の比率を増やし中小企業を減らす形のデータ補正をしたにもかかわらず、その影響を考慮せずに伸び率を算出した。企業規模が大きくなった分、賃金が伸びるという「からくり」だ。 多くの人が目にする毎月の発表文の表紙には「正式」の高い伸び率のデータを載せている。だが、この日、統計委は算

12日の午前中、いきなりtwitterのタイムラインに「統計所得」なるワードが登場したので何事かと思ったら、西日本新聞が以下のような記事を配信したことがキッカケのようです。 要は、調査対象となる事業所群を新たな手法で入れ替えたから、統計上の所得が実態よりも高めに出ていることが問題だと指摘をした記事のようです。 そして実態と乖離している可能性がある数字で景気判断していいのか、という提起をしています。 反アベノミクス派は、この記事に狂喜乱舞。「もはや公的データすら信用できない」という言葉が飛び交っています。 が、はっきり言って、信用できないのはデータが読めない西日本新聞です。コイツ何言ってんだ?と思いました。 問題点を整理してみましょう。 結局、何が問題なのか?記事を読んでも何を訴えたいのかよく分からなくて、読解力の無い私はきっとAIに代替される存在なのだと感じました。何度か読んで、 毎月勤労

◆人口 ・人口の長期時系列データ 人口というのは最も基本的な統計データだが、検索エンジンで「人口」と検索しても、どこを見たらよいか分からないだろう。 e-Statには人口の統計があるらしいと分かるが、長期の人口統計がどこにあるか、分からない。探し出しても、いくつかの期間に分かれていて、使いにくい。 私が探した限りでは、『日本統計年鑑』にあるこのデータ集が最も使いやすい。ただし、昔は長期に連続した表だったが、いまでは1920年で2つの表に分かれてしまっていて、やや使いにくくなった。 ・人口統計資料集 国立社会保障・人口問題研究所による統計資料集。 江戸時代の人口や世界の人口についての資料も、「Ⅰ.人口および人口増加」率の中にある。 ・将来人口推計 https://www.ipss.go.jp/pp-zenkoku/j/zenkoku2023/db_zenkoku2023/db_r5_suik

確率警察です。軽自動車の安全性について考察してバズった記事を読んで、驚いたので確率についての記事を書きたいと考えた。この記事で伝えたいのは以下の内容になる。 https://anond.hatelabo.jp/20180822005110 確率と割合の違い確率変数と確率分布 誤った理解による軽自動車への風評被害はNG確率と割合割合とは全体に対して部分が占める比率の事。比率とは二値A,Bあり、AのBに対する比率を表す場合、A÷Bで示される値の事を言う。 確率とは全事象の中で、事象Uが発生するか、発生しない割合の事を言う 確率と割合と比率の違い例 全ての宝くじの中で2等の数を1等の数を割ったもの 全ての宝くじの中に対する1等の数または2等の比率は割合 全ての宝くじから1枚を選んだ時に1等または2等である割合が確率比率は特に全体を定義する必要はない。割合と確率は全体が定義されて初めて意味がある。
政策評価と「科学風のウソ」 筆者は経済産業研究所に在籍して15年になるが、立場上からさまざまなシンクタンク・コンサルティング会社などの研究組織や大学で行われた「政策評価」を第三者評価・鑑定して欲しいと関係行政庁の担当から依頼されることがある。 個人的実感として、近年の定量的政策評価への意識の高まりとは裏腹に、依然として(悪意の有無は別として)科学的な証左を用いながら誠に不適切な「政策評価」の類が横行している状況にあると言わざるを得ず、この類の文献や報告書の中には刮目して読まなければならないものが多いことを日々大変残念に思っているところである。 当該問題は日本に限った問題ではなく、Manski(2011)*により類似の問題が米国でも深刻である旨が実名入りの事例を挙げて報告されている。具体的な報告は承知しないが欧州諸国や移行経済国、中国・インドなどの途上国でも推して知るべきであろう。本稿では
リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く




