
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
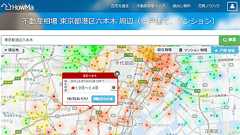
見知らぬ土地に引っ越す際に適正な価格の家を探したり、今の自宅を賃貸・売却する際に価格を決めたりするには、何か参考になる情報を集めたいものです。そんなときに使える無料の不動産情報サイトが「HowMa(ハウマ)」で、日本全国の不動産情報を地域・物件ごとに算出し、戸建とマンションの相場価格「ハウマッ値」を調べることが可能とのことで、実際に使ってみました。 [HowMa]不動産取引をもっと楽しくもっと身近に https://www.how-ma.com/ ◆地図から不動産相場を検索 HowMaでは選択した地域の不動産相場を自動推計して、エリア内の不動産の価格を地図上で視覚的に見ることができます。まずはHowMaにアクセスして、トップページの検索ボックスに相場価格を調べたい地名や住所を入力し、「検索」ボタンをクリック。今回は東京都品川区の不動産相場を調べてみることにします。 しばらく待っていると、東
「メディア芸術データベース(開発版)」にアクセスいただきありがとうございます。 2017年3月31日より、「メディア芸術データベース(開発版)」のURLを変更いたしました。 ブックマーク(お気に入り)に旧サイトを登録されている場合は、 新サイト(https://mediaarts-db.bunka.go.jp)へ変更をお願いいたします。 10秒後に自動的に新サイト(https://mediaarts-db.bunka.go.jp)に移動します。 Thank you for accessing the Media ArtDatabase (Development Version). On March 31 2017, the URL for the Media ArtDatabase (Development Version) changed. In ten seconds, you w
はじめにAmazon Redshiftは、Amazon Web Services(AWS)が提供するデータウェアハウス(DWH)サービスで、2013年2月に正式リリースされ、同6月4日には東京リージョンでも利用可能になりました。既存のDWHと比較しても安価で、PostgreSQLベースで容易に高速なデータ分析が可能であることなどが知られており、注目も高まっています。 ところが、日本国内では「使ってみた」という情報は非常に少ないです。幸運にも筆者は、限定プレビューの段階からRedshiftに触れる機会に恵まれました。そこで、今回は「こんな使い方をしてみました」「こんなところでつまずいた」といったことを中心に紹介したいと思います。 なお、本記事は限定プレビュー~サービス開始当初の米国東部リージョンでの使用結果を元に執筆しており、当時のAPIバージョンは2012-12-01です。東京リージョン

GSKの医療用医薬品を使用される患者さまとご家族の皆さま向けの医薬品情報です。製品を正しくご使用いただくための情報を掲載しています。下記の「ご利用上の注意」をお読みの上、ご利用ください。 このページに掲載されている情報は、医療機関で弊社医療用医薬品の処方を受けた方に、医薬品についての一般的な情報や、適正にご使用いただくための情報を提供するものであり、医学的アドバイスを提供するものではありません。 医療に関する判断は、患者さんの特性を考慮し、医師と患者さんとの相談の上で行うものです。治療上の質問は、医師にご相談ください。 このページに掲載されている情報は、日本国内に居住されている方のためのものです。

従来のデータベースをメモリに載せるだけではだめなのか? インメモリとカラム型データベースの可能性を調べる(その2) 現代のサーバは1台で複数のプロセッサを備え、数百ギガバイトから数テラバイトのメインメモリを搭載可能です。これは多くの企業で利用されているデータベースがそのままメモリに載るほどの容量です。 大量のメモリを搭載したサーバを用いれば、OracleDatabaseやSQL ServerやDB2など従来のディスクベースのデータベースでも、データベースをまるごとメインメモリのバッファキャッシュに載せることができます。そうすればディスクアクセスのボトルネックは事実上ほとんどなくせるため、高速なデータベースアクセスが実現します。 だとしたら、データベースをすべてメモリに載せる機能を備えたインメモリデータベースを、わざわざ使う必要はあるのでしょうか? この疑問は、以前の記事「キャッシュの大き

カラム型データベースはなぜ集計処理が高速で、トランザクションが苦手なのか。インメモリとカラム型データベースの可能性を調べる(その4) 現在主流となっているOracle、SQL Server、DB2などのリレーショナルデータベースは事実上すべて、行(ロー)指向で内部の処理を行っています。一方で、最近急速に注目されているのが、列指向で内部処理を行い、大量データの集計や分析処理に優れた「カラム型データベース」(あるいはカラム指向データベース、カラムナーデータベース)です。 カラム型データベースはSybase IQやNetezza、Verticaなどデータウェアハウス専用のデータベースで主に採用されています。また、SQL Serverには「ColumnStore Index」、Oracle Exadataには「Hybrid Columnar Compression」と呼ばれるカラム型データベースの

BigQueryはカラム型データストアの一種で、テラバイトクラスの大規模データに対して大量の並列処理を行うことで高速に結果を得ることが可能。グーグル 佐藤一憲氏の発言によると、 OLAP/DWH/Data Miningで行われるようなread onlyのad hocクエリをきわめて高速(数秒〜数十秒)に実行します。 とのこと。SQLによる問い合わせが可能 この高速性に加え、BigQueryではSQLを問い合わせ言語に使えるという点にも大きな特徴があります。数秒程度のレスポンスとSQL文による記述は、大規模データに対するアドホックな処理を行うのに適したサービスだといえるでしょう。 BigQueryのSQLの構文は「Query Reference」で解説されていますが、SELECT文にFROM、WHERE、JOIN、HAVING、GROUP BY、ORDER BY、LIMITなどが使えるため
The visual search engine for animated characters. We index characters byeye color, hair color, hair length, age, gender, and animal ears. Increase your fun by becoming a member today! Take part in Dragon Battles. Wish your favorite characters a Happy Birthday.Build a Family Tree. And so much more.Login | Register
 Amazonクラウド、SSD上の新NoSQLデータベース「DynamoDB」を公開。性能をダイナミックに上げ下げ可能
Amazonクラウド、SSD上の新NoSQLデータベース「DynamoDB」を公開。性能をダイナミックに上げ下げ可能Amazonクラウド、SSD上の新NoSQLデータベース「DynamoDB」を公開。性能をダイナミックに上げ下げ可能 「DynamoDBは、15年にわたる大規模なNoSQLデータベースとクラウドサービスから学んだことの集大成だ」(DynamoDB is the result of 15 years of learning in the areas of large scale non-relationaldatabases and cloud services.)。Amazon Web Serviceが新サービスとしてβ公開したDynamoDBについて、Amazon.comのCTOであるWerner Vogels氏は自身のブログAll Things Distributedのエントリ「Amazon DynamoDB – a Fast andScalable NoSQLDatabase

無料会員様やプレミアム会員様(5日間無料)はハンドル名で「みんなの名字の由来」に珍しい名字の由来や登録されていない名字ルーツの追加表記ができ、ご自分の幅広い名字由来の知識を多くの検索者に知っていただくことができます。更に、知りたい名字を「情報求む」欄に掲載できます。 ※追加更新された情報に関しては、不適切な表記がないかを日々運営事務局で管理しておりますので安心してご利用ください。 ユーザーの皆様は当サイトを無料でお使いいただけます。 ※ランキングや人数、読み、解説などの名字データをご利用される場合は、「参考資料 名字由来net」「名字由来netより引用」「出典 名字由来net」などと記載、そしてURLへリンクしていただき、自由にご活用ください。 ※引用元の記載なく無断での商用利用(ニュースサイト,Youtubeなどの動画,まとめサイトなど含みます)は利用規約に反するため、問い合わせ窓口にご

正規化とは、データを一元管理するための理論です。 1データ1箇所の原則を実現するために、1970年にE.F.Codd氏がリレーショナルモデルの理論として提案しました。正規化の理論は、データの冗長性を排除し、更新時の整合性を維持しやすくすることを目指しています。 具体的には、属性間の関連性を分析し、属性の最適なグループ化を図ることを目的としています。 一般には第3正規化まで行えば十分といわれていますが、本来は、あてはまる場合にはきちんと第5正規化まで行う必要があります。 まず、正規化の処理をする際によく出てくる関数従属という用語の意味を復習しておきましょう。 ◎ 関数従属とは ある属性Aの値が決まると他の属性Bの値が一意に決まるとき、「属性Bは、属性Aに関数従属である」(A→B)といいます。 完全従属とは、2の属性A、Bの間でA→Bが成立し、Aが複数の属性の集合で成り立っている場合、Aのいか

上記における「ベクレル(Bq/kg)」は、放射性物質そのものが放射線を出す能力(放射能)の強さを表す単位です。 放射性物質をたき火にたとえると、火の強さに相当します。 暫定規制値は、放射線から身を守るためのひとつとして、飲食を控えた方がよいと判断される目安として示されたものです。 (詳細、原子力安全委員会の指標 「原子力施設等の防災対策について」のP.108、資料6、参考) 暫定規制値を超えた食品は販売できないことが法律で決まっています(食品衛生法第6条第2号)。 暫定規制値を超えた場合はその場合は、出荷制限が行われ、当該農作物等については、現在、市場に流通しておりません。(原子力災害対策特別措置法) 出荷制限対象となった農産物については毎週放射線量の検査を実施し、3週連続で規制値を下回った 場合は市町村などの単位で制限を解除できるようになりました。本サイトにおきましても、科学的・客観
グーグルがNoSQL軽量ライブラリ「LevelDB」をオープンソース化。SQLiteとの比較ベンチマークも公開 キーバリュー型データストアは、いわゆるNoSQLデータベースの代表的な種類の1つ。LevelDBは以下のような特徴を備えています。 基本的な操作は、Put(key,value), Get(key), Delete(key) 1つのトランザクションとして複数の変更操作が可能 データは自動的に圧縮し保存されるSQLite、Kyoto TreeDBとの比較ベンチマークも LevelDBはC++で書かれたライブラリで、今後のChromeブラウザのIndexedDBはLevelDBで実装されると説明されています。 Upcoming versions of theChrome browser include an implementation of theIndexedDBHTML5
データベース設計の話をしていて、「連番の主キーは業務上意味のないデータだから、テーブルに持たせるのはムダだ。複合主キーにするべき」という意見を聞く機会がありました。 脊髄反射で「ないわー」と思ったものの、理由を上手く説明できなかったので、改めて考えてみました。 その結果、次のような結論に至りました。 単一の連番カラムによる主キーと、複合カラムによる主キーとで迷ったら 実装をシンプルにし、業務変更の影響範囲を小さくするために、複合主キーを避ける というわけで、調べたことや考えたことをメモしておきます。# 間違っている部分があれば、教えていただけると嬉しいです。 (2011/07/25 追記)複合主キーとサロゲートキーについては、要件やシステムに依存して多様な判断がありうると思います。にもかかわらず、「避けるべき」というタイトルにしたのは極端でした。申し訳ありません。ご指摘下さった皆さん、あり

MySQLのmasterとslave 1:1にして参照をslave向けるのってやりたがる人多いみたいだけど、性能たいして上がらない割に可用性落ちるだけだからやめようキャンペーン 2011-06-19 00:16:30 via YoruFukurouMySQL はレプリケーションが簡単に構成できるのですが、時折 master 1台 に対して slave 1台、更新処理は master に、参照は slave に、という構成を目にします。 個人的にはこの構成はお勧めでないと思っているので、その理由を考察してみます。 1. 可用性が落ちる 当然ですが、master, slave のどちらが落ちても影響を受けるために可用性が低下します。 2. 全体の性能がほとんど上がらない master 1台ですべてのクエリを処理する場合と比べて、可用性が落ちる引き換えとして見合った性能向上が得られるか、という
日本ヒューレット・パッカード(日本HP)は2011年4月26日、データベースに関する新戦略の発表会を開催した。新戦略では「データベース ロックリリース」をキーワードに、特定のベンダーの製品にロックインされがちなデータベース環境を、他のベンダー製品上に移行しやすくするサービスを提供する。これにより、データベースベンダーに対するユーザーの価格交渉力を高めることを狙いとする。 日本HP エンタープライズサーバー・ストレージ・ネットワーク事業統括の杉原博茂執行役員(写真1)は、新戦略を発表した背景として「ユーザーのコストを削減するには、データベースソフトに支払うライセンス費用を見直すことが必須になっている」ことを指摘する。日本HPの試算で2005年の同一性能モデルと現在のコスト構成を比べてみると、ハードウエア費用は20分の1以下になっているのに対し、データベースは30%強ほど下がっているに過ぎない

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く





