
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
はじめに 2021年12月に発見されたLog4jのCVE-2021-44228は、稀に見るレベル、まさに超弩級の脆弱性となっています。今回、私はTwitterを主な足がかりとして情報収集を行いましたが、(英語・日本語どちらにおいても)かなりWAFそのものが話題になっていることに驚きました。ある人は「WAFが早速対応してくれたから安心だ!」と叫び、別の人は「WAFを回避できる難読化の方法が見つかった。WAFは役に立たない!」と主張する。さらにはGitHubに「WAFを回避できるペイロード(攻撃文字列)一覧」がアップロードされ、それについて「Scutumではこのパターンも止まりますか?」と問い合わせが来るなど、かなりWAFでの防御とその回避方法について注目が集まりました。 実はWAFにおいては、「回避(EvasionあるいはBypass)」との戦いは永遠のテーマです。これは今回Log4jの件で

The State ofJava:Trends And Data For One of the World’s Most PopularProgramming Languagesの意訳記事です。 現代のソフトウェア産業は広大で、プログラミング言語の選択肢には事欠かきません。しかし、Javaエコシステムのような単一の技術スタックであっても、その市場について有益な結論を出すのは難しいことがあります。Javaは信じられないほどの成功を収めており、ほぼすべての主要な産業や経済部門で利用されていますが、このことがJavaエコシステムの状態について一つの断定的な視点を持つことを困難にしている部分もあります。 しかし、だからといって、世界の状況を評価できないわけではありません。 毎日、何千万ものJava仮想マシン(JVM)がNew Relicとデータを共有しています。このレポートを作成するにあたり
プログラミング言語を作る時には、途中で変えることが極めて難しいデザイン選択を最初に行わないといけないことがあります。今回は川合史朗さんがGaucheを設計した時に行ったデザイン選択の判断について話を伺いました。また、浮動小数点数のトリッキーさについても話をしています。出演者: 川合史朗 (@anohana)、Rui Ueyama (@rui314) https://turingcomplete.fm/17 ハッシュタグは#tcfmです。 TCFMはサポーターの投げ銭によって収益を上げています。このコンテンツに課金してもいいよという方はぜひクリエイター支援サイトPatreonから登録してご協力ください。 イントロ (0:00) セキュキャン参加者募集中 (0:41) 俳優のオーディションとその心構え (2:43) 川合史朗さんが出演している映画がサンフランシスコで上映されます (5:16)

セッションIDやアクセストークン、はたまた業務上で使う一意の識別子など、いろんなところで一意のIDを生成しなきゃいけないケースが存在します。 そこで世間で使われているIDの生成方法について調べてみました。 選択基準 ID生成における要求として、以下の観点が上げられるかと思います。 生成の速度 大量にデータを短期間で処理し、それらにIDを付与する場合、ID生成そのものがボトルネックとなることがあります。 推測困難性 IDを機密情報と結びつける場合、IDを改ざんされても、機密データが見れないようにできている必要があります。 順序性 採番した順にデータをソートする必要がある場合は、IDがソートキーとして使えないといけません。 それぞれについて各生成手段を評価します。 ID生成の手段 データベースの採番テーブル 採番用のテーブルを作り、そこで番号をUPDATEしながら取得していくやりかたです。古い


Internet Engineering Task Force (IETF) D. M'Raihi Request for Comments: 6238 Verisign, Inc. Category: Informational S.Machani ISSN: 2070-1721 Diversinet Corp. M. Pei Symantec J. Rydell Portwise, Inc. May 2011 TOTP: Time-Based One-Time Password Algorithm Abstract This document describes an extension of the One-Time Password (OTP) algorithm, namely the HMAC-based One-Time Password (HOTP) algorithm,
Ruby + OpenSSLで署名Ruby + OpenSSLでRSAやECDSA署名するには、OpenSSLコマンドで普通に PKCS#5の秘密鍵と公開鍵を準備してこんな感じで署名生成、署名検証すればヨロシ。 # ECDSAの署名生成 prvKey = OpenSSL::PKey::EC.new(File.read(PKCS#5秘密鍵PEM)) hashed = OpenSSL::Digest::SHA1.digest(署名対象メッセージ) sigVal = prvKey.dsa_sign_asn1(hashed) # ECDSAの署名検証 pubKey = OpenSSL::PKey::EC.new(File.read(PKCS#5公開鍵PEM)) hashed = OpenSSL::Digest::SHA1.digest(data) isValid = pubKey.dsa_ver
【東京】【聴講者募集】JJUG ナイト・セミナー 「ビール片手にLT&納涼会」の発表資料です。 https://jjug.doorkeeper.jp/events/28182

Python で実装され、その後Java にも移植されたソートアルゴリズムである TimSort が盛大にバグっていることが発見されました。 このバグがどのようにして発生するのかについては、以下のドキュメントを精査して下さい。 TimSort fails with ArrayIndexOutOfBoundsException on worst case long arrays OpenJDK’sjava.utils.Collection.sort() is broken: Thegood, the bad and the worst case どんなことが起こるのか 通常の利用では想定しえない場所でArrayIndexOutOfBoundsExceptionが発生します。 例えば、以下のようなスタックトレースになります。 Exception in thread "main" jav

Xamarin Advent Calendar3日目のエントリーです。今年は全部埋まっていて気楽ですね! まあ去年も2回書いただけですが。 さて、もうだいぶ前になりましたが、Xamarin Evolve 2014のライトニングトークで、Xamarin.Androidでちょろっと実装していたproguardサポートについて話しました。今日はそのネタについて書こうと思います。LTで話したことに、必要になりそうな前提知識をちまちまと追加しただけで、その後追加された目新しいニュースはありません。 はじめに残念なお知らせですが、このproguardサポートの機能、秘密ではないのですが次のリリースでは大々的に告知されません。何が起こったかというと…IDEに必要なコードが何も追加されていなかった上に、QAが何もやってないことが判明したんですね(!)。そんなわけで、10月には「5.0に入れるよ!」としゃべ
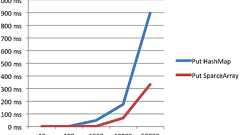
 AndroidのSparseArrayは本当に速いのか測定してみた
AndroidのSparseArrayは本当に速いのか測定してみた前回のエントリで紹介したBundleSaverを作成する際に、SparseArrayというクラスの存在を知りました。 SparseArrayは、Android向けにつくられたパフォーマンスに優れたHashMap代用とのことで、その使い方と気になる性能について調べてみました。 実際に測定することでメリットやデメリットがわかったので、ご紹介します。 SparseArrayってなぁに? どう使うの? HashMap と SparseArray の性能比較 考察 まとめ 参考(計測に利用したクラス) 1. SparseArrayってなぁに? SparseArrayは、キーにintを利用することを前提としたHashMapだと考えると分かりやすいかと思います。 (Integerではなく、intです。) また、SparseArrayでは、値にObject型を格納できますが、値がint, booleanの
運営元のロゴ Copyright © 2007-2025 All Rights Reserved by Gijutsu-Hyoron Co., Ltd. ページ内容の全部あるいは一部を無断で利用することを禁止します。個別にライセンスが設定されている記事等はそのライセンスに従います。

ゼロから作るKubernetesによるJupyter as a Service ーKubernetes Meetup Tokyo #43

Solr 3.5 から新たに加わる言語判定機能に、拙作の言語判定ライブラリ langdetect が正式に採用されたようで。 言語判別機能の追加 (Solr 3.5) http://lucene.jugem.jp/?eid=455 LanguageDetection - Solr Wiki http://wiki.apache.org/solr/LanguageDetection もともと Apache Nutch などの言語判定に不満で作り始めたこと、そして実際に社内(サイボウズ)で langdetect を Solr に組み込んで利用していることを考えれば、本懐と言ってもいいくらい。 ありがたや。 でも、今日の話はそっちではなくて。 その langdetect の Issue Board にて教えていただいた「メールアドレスの正規表現がめちゃめちゃ遅くなることがある」件について。 論よ
「青空文庫」をテキストマイニング! 前回の「いまさら聞けないHadoopとテキストマイニング入門」では、Hadoopとテキストマイニングの概要や構成、MapReduceの仕組み、Hadoopの活用場面などを解説し、Hadoopの実行環境を構築しました。今回から、Hadoopを使い、テキストマイニングのMapReduceプログラムを作成していきます。 「青空文庫」というサイトをご存じでしょうか。青空文庫は、著作権が切れた日本の文学作品を掲載しているWebサイトで、青空文庫の全データをDVDや、BitTorrentによる配信で入手できます。今回は、このデータを使ってテキストマイニングを行いましょう。 前回、テキスト分類で、著者の性別、年齢、地域、職業などの属性も推定できると書きましたが、青空文庫は、他のデータにはない、著者属性があります。青空文庫の作品は、著作権が切れて、作者がなくなっている場
ちょっとOverlayfsの実装、読んでみました(A briefreport of overlayfs source code reading)

オブジェクト指向は、人によって理解が違って、それを上手く共有出来ないと凄い認識違いが起きたりするので、ここで自分の考え方をまとめてます。 ここでいうオブジェクト指向は、クラスベースのオブジェクト指向のことです。 制限と拡張 オブジェクト指向は、それまで出来ていたことに対する制限とそれまで出来なかったことという拡張の2つの側面があります。 制限 カプセル化(※1) 言語仕様として、公開範囲を決められる 拡張 ポリモーフィズム 継承やインタフェースを用いる事により、様々なテクニックが使える この2つは、全くの別の概念として説明されることが多いですが、どちらも「相手に必要な情報しか渡さない」と考える事が出来ます。 カプセル化 相手に必要ない「内部構造と実装」を隠蔽する ポリモーフィズム 相手に必要ない「必要としてる型以外の情報」を隠蔽する これを確認するために、オブジェクト指向が出来るまでの流れ

Javaでコレクションクラスを作ってそのイテレータを実装する場合、Javaにはクロージャが無いので、外部イテレータを使うことがほとんどだと思います。 例えばint値のコレクションとイテレータを自作するときは、まず以下のようにIntIteratorとIntIterableを用意して public interface IntIterator { boolean hasNext(); int next(); } public interface IntIterable { IntIteratoriterator(); } 以下のように実装します。 public class IntArray implements IntIterable { private int[] array; private int length; public IntArray(int[] array) { this.a
リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く





