
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
Geminiの特長Geminiという大規模言語モデルシリーズは、元々GoogleのAI研究チームが開発したBERTというTransformerのうちのエンコーダ部分を切り出して作られたモデルから発展したものです。 Transformerは、入力シーケンスを理解するエンコーダと、出力を生成するデコーダから構成されていますが、BERTはエンコーダ部分だけを使用しています。 これが何を意味しているかというと、文章の要約や翻訳など、入力されたテキストの文脈や全体像を理解することに長けているモデルです。 そのBERTから発展した(と思われる。非公表)モデルであるGeminiも、当然その長所を受け継いでいるため、200万トークンという超長文(ロングコンテキスト)を扱うことができます。 と、長くなりましたが、要は、Geminiは長いトークンや入力の処理は得意ですよ、ということです。 Geminiでの文字


Deleted articles cannot be recovered. Draft of this article would be also deleted. Are you sure you want to delete this article? はじめにWhisperAPI を利用せずにローカル環境でリアルタイム文字起こしに挑戦してみました。本家Whisperだと音声ファイル形式以外の入力がうまくいかなかったため、faster-whisper を利用しました。 手探りで挑戦しましたので、何かご指摘がありましたらお教えいただければ幸いです。 効率的に文字起こしを行うための関連記事 [ローカル環境] faster-whisper を利用してリアルタイム文字起こしに挑戦2 [Windows]文字起こしにデスクトップ音を利用する試み faster-whisperのパラメータを調べ
![[ローカル環境] faster-whisperを利用してリアルタイム文字起こしに挑戦 - Qiita](/image.pl?url=https%3a%2f%2fcdn-ak-scissors.b.st-hatena.com%2fimage%2fsquare%2f0a6d757549674c12d4cf30c9a2a5d6fdaea2d9b1%2fheight%3d288%3bversion%3d1%3bwidth%3d512%2fhttps%253A%252F%252Fqiita-user-contents.imgix.net%252Fhttps%25253A%25252F%25252Fqiita-user-contents.imgix.net%25252Fhttps%2525253A%2525252F%2525252Fcdn.qiita.com%2525252Fassets%2525252Fpublic%2525252Farticle-ogp-background-afbab5eb44e0b055cce1258705637a91.png%25253Fixlib%25253Drb-4.0.0%252526w%25253D1200%252526blend64%25253DaHR0cHM6Ly9xaWl0YS11c2VyLXByb2ZpbGUtaW1hZ2VzLmltZ2l4Lm5ldC9odHRwcyUzQSUyRiUyRnMzLWFwLW5vcnRoZWFzdC0xLmFtYXpvbmF3cy5jb20lMkZxaWl0YS1pbWFnZS1zdG9yZSUyRjAlMkY1NTM1MjglMkZhMzg5NjljOTNhYzA5NGUyMmNiZTRjZWYwMjUzZjg4ZjY5Y2ExYTJjJTJGeF9sYXJnZS5wbmclM0YxNjc5Nzk4OTQxP2l4bGliPXJiLTQuMC4wJmFyPTElM0ExJmZpdD1jcm9wJm1hc2s9ZWxsaXBzZSZiZz1GRkZGRkYmZm09cG5nMzImcz0xM2M0ODRkN2E2MjVhMjI1N2RmNmY0NDYyZTg3YjNiZg%252526blend-x%25253D120%252526blend-y%25253D467%252526blend-w%25253D82%252526blend-h%25253D82%252526blend-mode%25253Dnormal%252526s%25253D50e3ee8cdfb1fc5ebdffe113a38ab710%253Fixlib%253Drb-4.0.0%2526w%253D1200%2526fm%253Djpg%2526mark64%253DaHR0cHM6Ly9xaWl0YS11c2VyLWNvbnRlbnRzLmltZ2l4Lm5ldC9-dGV4dD9peGxpYj1yYi00LjAuMCZ3PTk2MCZoPTMyNCZ0eHQ9JTVCJUUzJTgzJUFEJUUzJTgzJUJDJUUzJTgyJUFCJUUzJTgzJUFCJUU3JTkyJUIwJUU1JUEyJTgzJTVEJTIwZmFzdGVyLXdoaXNwZXIlRTMlODIlOTIlRTUlODglQTklRTclOTQlQTglRTMlODElOTclRTMlODElQTYlRTMlODMlQUElRTMlODIlQTIlRTMlODMlQUIlRTMlODIlQkYlRTMlODIlQTQlRTMlODMlQTAlRTYlOTYlODclRTUlQUQlOTclRTglQjUlQjclRTMlODElOTMlRTMlODElOTclRTMlODElQUIlRTYlOEMlOTElRTYlODglQTYmdHh0LWFsaWduPWxlZnQlMkN0b3AmdHh0LWNvbG9yPSUyMzFFMjEyMSZ0eHQtZm9udD1IaXJhZ2lubyUyMFNhbnMlMjBXNiZ0eHQtc2l6ZT01NiZ0eHQtcGFkPTAmcz1mM2VhN2M0YmIzY2Y0OTFmNTQ0YzlmMjk1MmNkMGZiYw%2526mark-x%253D120%2526mark-y%253D112%2526blend64%253DaHR0cHM6Ly9xaWl0YS11c2VyLWNvbnRlbnRzLmltZ2l4Lm5ldC9-dGV4dD9peGxpYj1yYi00LjAuMCZ3PTgzOCZoPTU4JnR4dD0lNDByZXJpaWFzdSZ0eHQtY29sb3I9JTIzMUUyMTIxJnR4dC1mb250PUhpcmFnaW5vJTIwU2FucyUyMFc2JnR4dC1zaXplPTM2JnR4dC1wYWQ9MCZzPTBkMDhkMTk5ZTZmZTM2MTcwODgzZmFkMzM0ZmUzNjI1%2526blend-x%253D242%2526blend-y%253D480%2526blend-w%253D838%2526blend-h%253D46%2526blend-fit%253Dcrop%2526blend-crop%253Dleft%25252Cbottom%2526blend-mode%253Dnormal%2526s%253De04d71436627fa88cf686413ed39b782&f=jpg&w=240)
地方拠点の一つ、九州支社に所属しています。サーバ・ストレージを中心としたSI業務に携わってましたが、現在は技術探索・深堀業務を経て、ローカルLLMを中心としたAIソリューションを主軸に対応しています。 2018年に難病を患ったことにより、定期的に入退院を繰り返しつつ、2023年には男性更年期障害の発症をきっかけに、性的違和の治療に一歩足を踏み出しています。 【IIJ2022TECHアドベントカレンダー 12/8(木)の記事です】Whisperの追加学習に挑む2022年の冬2022年アドベントカレンダー企画だそうです。 いかがお過ごしでしょうか。 私はもう興味を引くものに没頭するしか楽しみがないもんで、PCに向かってぼんやり面白いネタはないかなーと探す日々です。 最近はすっかりディープラーニングにズブズブで、とうとう数式かくのが面倒なあまり手書き入力のためのペンタブレットを買いました

アプリや専用デバイスを使った、日本語の「自動文字起こし」に関連するサービスには、近年多くの関心が集まっている。背景にはスマホやAIを活用する音声認識のテクノロジーが飛躍を遂げたことや、コロナ禍の影響を受けてリモートワークが普及したことなどがある。iPhoneに対応する「UDトーク」も自動文字起こしに対応する注目のアプリだ。開発者に特徴を聞いた。iPhone/iPadでも使える日本語対応の自動文字起こしアプリ コミュニケーション支援・会話の見える化アプリをうたう「UDトーク」は、Shamrock Records(シャムロック・レコード)の代表兼エンジニアである青木秀仁氏が開発を手がけている。 モバイル版アプリはiOS/Android/Fire OSの各プラットフォームに対応する。ほかにも音声認識の結果を修正したり、事前に作成した原稿をスマホやタブレットに送信する一部機能を搭載するMac版/

 AWS、アレクサと同様の会話理解力を持つ「Amazon Lex」日本語対応を発表。日本語で会話する音声ボットやチャットボットが開発可能に
AWS、アレクサと同様の会話理解力を持つ「Amazon Lex」日本語対応を発表。日本語で会話する音声ボットやチャットボットが開発可能にAWS、アレクサと同様の会話理解力を持つ「Amazon Lex」日本語対応を発表。日本語で会話する音声ボットやチャットボットが開発可能にAmazon Lexを利用することで、「すべてのデベロッパーがAmazonAlexaに採用されている深層学習技術と同じ技術を利用できる」(Amazon Lexの説明文から)とされています。Amazon Lexは、自動音声認識による音声からテキストへの変換機能と、テキストの内容からその意図を認識する自然言語理解機能を備えています。 つまり、電話やオンライン会議などを経由して日本語の音声をAmazon Lexに入力すると、いわゆる文字起こしのようにその内容をテキストに変換してくれます。 そしてこの音声から変換されたテキストや、Slackなどのテキストチャットなどで入力されたテキストの内容から、Amazon Lexはその意図などを理解し、会話の中から必要な
情報管理LOGの@yoshinonです。 ここ最近は、「自動化」「音声入力」といったキーワードが、賑わっていますね。情報管理LOGでも、かなりこれについては激推ししています。さて今回は、文字起こしの自動化についてやってみたいと思います。文字起こしの自動化については、Macが先行していてWindowsの情報があまり見られなかったので、今回はWindowsについて深く掘り下げてみたいと思います。文字起こしの自動化が出来るようになると、議事録の作成などがほぼ自動化できるので、今まで苦痛だった仕事がとても楽になりますよ。 ※追記:Virtualが、Visualになっていましたので、修正しました…(恥ずかしい)。 ここ最近の自動文字起こし界隈(?)では、Mac勢がかなり優勢で盛り上がりを見せています。ここ最近の記事をいくつかご紹介します。 「神なの?」文字起こしが自動になる未来がやってきたとライター

Google、DNNを用いるオープンソース音声認識システム「Kaldi」と同社機械学習ライブラリ「TensorFlow」とを統合。強力な自動音声認識(ASR)システム開発へ 2017-08-29Googleは、DNN(Deep NeuralNetwork)を用いているオープンソースの音声認識システム「Kaldi」と、同社が提供する機械学習ライブラリ「TensorFlow」とを統合したことを発表しました。 この統合により、Kaldiを使用している自動音声認識(ASR)などの開発者は、TensorFlowを使用して、Kaldiの音声認識パイプラインにDeep learningモデルを展開することができます。 統合することで、自然言語モデルをトレーニングするASRの場合、開発サイクルが一桁も短縮されたと報告します。 TensorFlowでKaldiを使い始めるには、Kaldi repoをチェ

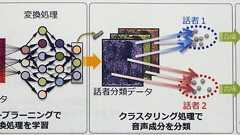
三菱電機は研究成果披露会で、同社独自のAI技術「ディープクラスタリング」を用いた音声分離技術を発表した。この技術では、マイク1本で録音した複数話者の同時音声を分離し、きれいに再現できる。従来の技術では原音再現率が51%だったが、三菱電機の音声分離技術の場合90%以上となる。 答えではなく、解き方を学ぶ スマートフォンやカーナビなどの音声認識機能は、雑音や複数の人の声が混じると正しく機能しないことが多い。音を聞き分けて再現する技術自体は既に存在するが、精度の面でまだ十分とはいえない。マイク1本で取得した音声を分離し再現する技術の場合は特にだ。 三菱電機が同社独自のAI技術「ディープクラスタリング」を用い、音声分離技術を開発したのにはこのような背景がある。三菱電機は2017年5月24日の研究成果発表会で、マイク1本で録音した複数話者の同時音声を分離し、きれいに再現する様子を披露した。 ディープ
昨今話題になっている音声認識デバイス。一番身近なところでは、iPhoneのSiriやアンドロイドに搭載された会話認識機能が思い浮かぶ。昨年に大ヒットした、話しかけて操作するAmazonの人工知能スピーカー『エコー(Echo)』もその一つだ。エコーに話しかければ、搭載されたAI「アレクサ(Alexa)」が情報を処理。ネット検索はもちろん、天気予報を聞いたり、アラームをセットしたり、音楽を再生させたりできる。その上、「アマゾンの商品を注文する」という機能まであるから驚きだ。しかし最近では、このエコーで思わぬハプニングが起きている。 ことの発端はアメリカのダラスに住む6歳の女の子がアマゾンエコーに「ドールハウスとクッキーを買って」とお願いしたことだ。数日後、約160ドル(約1万8千円)相当のドールハウスと2kgにもなる大量のクッキーが家へ配達されて、女の子の母親はびっくり。結果、届いた高価なドー

博士論文 背景雑音と話者の違いに頑健な音声認識 2013年1月28日 指導教員 峯松 信明 教授 電気系工学専攻 37-107091 鈴木 雅之 あらまし音声認識は様々なシステムの要素技術として利用されている.例えば,カーナビシステ ム,スマートフォンの音声対話システム,企業のコールセンタにおける電話自動応対シス テムなど,その応用範囲は多岐に渡る.音声認識の精度を高めることは,これらのシステ ムのユーザ満足度を向上させることに直結する.そのため,音声認識の精度を向上させる ために研究を進めていくことが重要である.音声認識の精度は,様々な要因によって低下してしまうことが知られている.例えば背 景雑音が音声に重畳してしまった場合,何も対処を行わないと音声認識精度は大幅に低下 してしまう.他にも,話者の違い,マイクとの距離,部屋の残響,話している内容と,様々 な要因によって音声認識精度
 1
1リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く



