
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
現行のデジタルコンピュータは、あらゆるデータを内部的にはONとOFFの2つの状態を1ケタとした「ビット」で扱っています。この文章を書いている文字もその例外ではなく、ビット列と文字の対応関係をまとめた「文字コード」によって管理されています。 ところで話は少し変わりますが、ビットを複数集めた「バイト」という単位もあります。ここで簡単な質問です。1バイトは何ビットでしょうか? 1バイトは何ビットか さすがに簡単すぎましたね、1バイトは8ビットです。ここで湧いてくる疑問、ではなぜ8ビットなのでしょうか? その答えの一つは、単純で非常につまらないものです。それは単にそう決まっているからです。 工学的な決まりごとは往々にして、なんらかの規格で定められているものです。もちろん1バイトのビット数も規格で定められています。 ではここでまた問題です。1バイトを8ビットとした規格はいつ定められたでしょうか? A

TOPフォーカスUnicode全文字入力アプリ・Unicode Padを作って10年。少年期に抱いた文字コード愛の正体【フォーカス】 Unicode Pad開発者 株式会社estie データマネジメント事業本部 スタッフエンジニア Lin(山本 亮介) 2018年にSoundHound Inc.日本支社にてキャリアをスタート。日本語の車載音声アシスタントのバックエンド開発に従事。2023年4月、株式会社estieに入社。データパイプラインや共通データAPIの設計・実装などを担当し、現在はスタッフエンジニアを務める。個人では大学時代の2014年にAndroidアプリ「Unicode Pad」を個人開発し、リリース。通称のLinは、配偶者の名前が由来。ニックネームを設定したのは、「ヤマモト」も「リョウスケ」もそれぞれ社内に同音の社員が在籍しており、シンプルで「unique」な呼び名が欲しくなっ

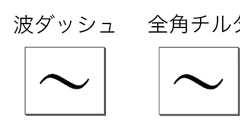
どうも、『人文×社会』の中の人です。 今回は、WindowsとMacで起こった「波ダッシュ」をめぐるドタバタ劇をご紹介したいと思います。 波ダッシュといえば、「〜」という記号。どこにもドタバタする要素がないように思えますが、実は今でも組版業界で問題となっている大混乱があります。 波ダッシュと全角チルダ「それ、不等号ですよ! 紛らわしい約物3連発!」の記事でもご紹介したように、見た目が「〜」に見える約物には、2種類あります。 「波ダッシュ」と「全角チルダ」です。 「波ダッシュ」は、日本語で範囲を表すときに使われる約物です。「明治〜大正」みたいな感じで使います。 「全角チルダ」は、半角チルダ(~)の全角版です。チルダは「漸近的に等しい」ことを表す数学記号として使われます。つまり、全角イコール(=)の仲間です。(他にも半角チルダは、コンピュータ上のホームディレクトリを表したり、プログラミング言語
はじめにmacOS では濁点や半濁点が含まれるファイル名でたびたび問題が発生しています。この問題は NFD 問題と言われたりUTF-8-MAC 問題と言われることがありますが、必要な情報が正確に書かれているところは少なく、正しく解説してある所でも情報が古く(主に HFS+ 時代の話に)なっており、読むと逆に混乱してしまう場合があります。macOS 標準アプリや誰かが作ったアプリであればバグが修正されるまで待つだけですが、自分が作ったアプリやシェルスクリプトなどではこれがどういう問題なのかを理解しなければバグが修正できません。この記事ではそれらを整理し直して、(可能な限り正確に)解説したいと思います。検証はmacOS 15.3(補助的に 15.5)で行っています。 この問題は、Mac で作成したzip ファイルをWindows で展開したときに、濁点や半濁点を含むファイルに Wi

この記事は 2024 TSG Advent Calendar 3日目の記事です。昨日の記事は @__dAi00 さんの記事AivisSpeechを使ったDiscordボットの作成 ①AivisSpeechをGoogle Cloud Runにデプロイする でした。12/5 公開予定の続編も楽しみです。 今回は、初日に公開した以下の記事の副産物です。 import unicodedata #Python 3.12 まで 1000000000000.0 #Python 3.13 から 1000000.0 print(unicodedata.numeric("兆")) 大変だ。Python 3.13 から「5000 兆円」が 50 億円になってしまう(?) unicodedata.numeric メソッドと Unicode 例によって Unicode が関係してきます。前編でも触れたとおり、
本記事は 【Advent Calendar2023】 17日目の記事です。 🎄 16日目 ▶▶ 本記事 ▶▶ 18日目 🎅 こんにちは。 2年目の草野です。年末が近づいてきましたね。 今回はAdvent Calendarの執筆に参加ということで、2023年の業務の中で印象深かったUnicodeについて少しお話したいと思います。 そもそもUnicodeとは サロゲートペア文字 突然ですが…… 異体字セレクタとの出会い 異体字セレクタって? 全く同じ意味を持つ文字、異体字 異体字セレクタの誕生 具体例 結局私の名字はどう書くの? おわりに そもそもUnicodeとは みなさんご存じの通り、Unicodeは文字を表すための国際的な標準規格の1つです。 一般的には [U+91CE] のように、16進数で表記されます。 常用文字は [U+0000] ~ [U+FFFF] の16進数4文字=2バ

コンテンツ一覧 インデックスページ←いまここ コンピュータ上での数値の扱い コンピュータで文字を扱うには? ASCIIとJISローマ字 JIS漢字コード:JIS第一・第二水準 JIS補助漢字・第三・第四水準漢字中国の文字コード台湾の文字コード Unicode 大規模文字集合 参考資料(書籍)本ページを作るにあたって参考にした書籍です。 川俣晶『パソコンにおける日本語処理文字コードハンドブック』技術評論社 芝野耕司編『JIS漢字字典』日本規格協会 漢字文献情報処理研究会編『電脳中国学』『電脳中国学II』『電脳中国学入門』好文出版 小池和夫/府川充男/直井靖/永瀬唯/『漢字問題と文字コード』 太田出版 1999 安岡孝一/素子『文字コードの世界』 東京電気大学出版局 1999 ユニコード漢字情報辞典編纂委員会編 『ユニコード漢字情報辞典』 三省堂 2000 小林/安岡/戸村/三上編 bi
TL;DR Shift_JISにしただけでコンパイラが通らなくなる恐ろしい事件とその回避法について。 \ (¥)のASCIIコードは0x5c 表、能は良くないUTF-8は神2023/12/06追記 誤りがあったので訂正します。こんな読まれると思ってなかったので正直ちょっとびっくりしていますが、いろいろコメントありがとうございました。(ツイート等全て拝見しました。) Shift_JISが悪いわけではない(デフォルトのエンコーディング設定の問題)→追記しましたUTF-8にはUTF-FSSという仕様でこの問題が回避されている→マジでタメになる知識ありがとうございます OSによってデフォルトのエンコーディング設定が異なるせいで、デフォルト環境での動作がOSにより異なる→なるほど?(調査中) CRLFとLF問題では→なるほど?(調査中) そんな問題何を今更→UTF-8が出てから生まれたからです

2003年には「プレーンテキストなんてものは全く存在しない」と言われ、テキストの解読には文字コードの情報が必須となっていました。しかし、2023年になるまでの20年の間に絵文字などのおかげでUnicodeの利用率は98%へと到達し、再び文字コードを気にせずにすむ時代がやってきています。そんな時代において、正しくUnicodeを使うために必要な知識をエンジニアのニキータ・プロコポフさんが解説しています。 The Absolute Minimum Every Software Developer Must Know About Unicode in2023 (Still No Excuses!) @ tonsky.me https://tonsky.me/blog/unicode/ Unicodeの歴史と利用率の推移をまとめたグラフは下図の通り。2000年代後半から急速に普及が進んでいったこ

2023.05.10 官報に使われる「官報文字」というものがあります。 そこには渡辺さんの「辺」の異体字が140文字も登録されています。 日本語の常用漢字には2136文字ありますが、そこには邉や邊などは入っていません。 そこでJISの第四水準までを含むJIS X 0213という標準を定め、スマホやパソコンではここまでを標準的に表示できるようにしています。 ところが我が国の戸籍で使ってもよいとされている文字はそれを遙かに超えていて、少なくとも55,270文字もあります。 全ての国民の氏名をコンピュータで扱えるようになることを目指して、戸籍統一文字や住基ネット用の統一文字を網羅した「文字情報基盤」を2011年に策定し、それにあわせたフォントを作成し、無償で提供しています。 この「文字情報基盤」(MJ)には、58,862文字が含まれています。 しかし、このMJを全庁的に採用している自治体は、川口

皆様こんにちは、NewsPicksエンジニアの米澤です。 先日2023/03/30は、こちらでアナウンスしていた通り、サービスの停止を伴うシステムメンテナンスを実施させて頂きました。NewsPicksをご利用頂いている皆様には、ご迷惑おかけいたしました。 今回はこのメンテナンスの中で行われたDBテーブルのmigrationについてお話ししたいと思います。 ことの始まり やったこと 方針決め utf8mb4に対応していないテーブルを調べる migrationを作成する 影響範囲を調べる 開発環境でリハーサルを行う メンテナンスの日 最後に ことの始まりNewsPicksではバグの検知にBugSnagを利用しています。 ある時、BugSnagにこんなエラーが通知されてきました。 org.springframework.orm.hibernate4.HibernateJdbcExcepti

関連記事 25人のAIが一緒に暮らしたら、自我は芽生えるか? ゲームの中で検証 バレンタインなど勝手に企画 米スタンフォード大学とGoogle Researchに所属する研究者らは、ChatGPTなどで制御したキャラクター25人が1つの町で一緒に生活したらどうなるかを検証した研究報告を発表した。 「サーバに致命的な不具合」のスマホゲー、「修正不可能と判断」でそのままサービス終了 問題発生から2日でゲームの開発・運営を手掛けるインゲームは、スマートフォンゲーム「戦策三国志」(iOS/Android)の不具合を修正できず、サービスの提供を終了したと発表した。 任天堂「ご迷惑をおかけし申し訳ございません」 「ポケモンSV」アップデート配信 SNSではバグ報告の声多数 任天堂とポケモン社が、「ポケットモンスター スカーレット・バイオレット」の更新データを配信する。新機能を追加した他、いくつかのバ

世界中の文字を収集して文字コードを付与する規格「Unicode」では、バージョンアップごとに次々と絵文字が追加されたり、画像じゃなく文字で出力するためコピー&ペーストが可能なカレンダーを作成できたりと、文字を使ったさまざまな表現を使うことができます。そのようなUnicodeの「目に見えない文字」はどういった種類があってどのように利用できるのかをまとめた「Invisible Characters」では、目に見えないUnicode文字をコピペして使えたり、テキスト内に含まれる目に見えないUnicode文字を検出したりすることができます。 Unicode characters you can not see https://invisible-characters.com/ 人気のオンラインマルチプレイヤーゲーム「Among Us」では、プレイヤー名を設定する際に空白のままにしたり、空白スペース

Pythonがファイルを開くときなどに使われるエンコーディングはロケール(WindowsではANSIコードページ)依存でした。 Unixの世界ではどんどんUTF-8ロケールが一般的になっている一方、WindowsのANSIコードページはなかなかUTF-8になりません。 そのために、Unixユーザーが open(filepath) のようにエンコーディングを指定しないままUTF-8を仮定するコードを気軽に書いてしまって、Windowsユーザーがエラーで困るといった問題が発生します。 また、Windowsでもメモ帳(Notepad.exe)やVSCodeはすでにUTF-8をデフォルトのエンコーディングで使用しています。ANSIコードページがUTF-8になるのを待っていたらどんどん周りの環境から置いていかれ、レガシー化してしまいます。Pythonがデフォルトで利用するエンコーディングをWind
A static site to link people to when their code is displayingJapanese wrong. View the Project onGitHub heistak/your-code-displays-japanese-wrong Why am I here? If someone gave you a link to this page, that person probably thinks your code displaysJapanese wrong. In short, from a nativeJapaneseeye, yѳur ҭєxҭ lѳѳκs κιnd ѳf lικє ҭЋιs. This page will give you a brief description of the glyph appe
美乳テーブルとは 「美乳テーブル」という物がある。 「EUC-JP の文章を Shift_JIS だと誤認識されない様に、EUC-JP 固有のバイト値を文章先頭付近に埋め込んでおく」という物。 具体的に、Shift_JIS には 0xFD と 0xFE が現れず、EUC-JP にはそれが現れるので、その値を含む文字コードを書いておこうという事で、その文字の集合に付いた名前。 “美” = 0xC8FE、“乳” = 0xC6FD。 各文字エンコーディングの事情 但し、これは EUC-JP での話。 一応、文章の先頭付近に日本語の文字を書いておくのは、他の文字エンコーディングでも認識のヒントにはなるけど。 逆に「Shift_JIS の文章を EUC-JP だと誤認識されない様にする」には、EUC-JP にはないバイト値の 0x80〜0xA0 を書けばいいんだろうけど、これは沢山ありそうだから、慎
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTTTech Conference #4 講演資料)

きっかけ 以下のツイートで「埼玉埼⽟問題」と康煕部首を知りました。 「埼玉」と「埼⽟」の話。unicodedata.normalize('NFKC', '「埼玉」と「埼⽟」') でいけそう https://t.co/kte0sxDvZT — Haruhiko Okumura (@h_okumura) July 11, 2020 康煕部首とは ⼀⼁⼂⼃⼄⼅⼆⼇⼈⼉⼊⼋⼌⼍⼎⼏⼐⼑⼒⼓⼔⼕⼖⼗⼘⼙⼚⼛⼜⼝⼞⼟⼠⼡⼢⼣⼤⼥⼦⼧⼨⼩⼪⼫⼬⼭⼮⼯⼰⼱⼲⼳⼴⼵⼶⼷⼸⼹⼺⼻⼼⼽⼾⼿⽀⽁⽂⽃⽄⽅⽆⽇⽈⽉⽊⽋⽌⽍⽎⽏⽐⽑⽒⽓⽔⽕⽖⽗⽘⽙⽚⽛⽜⽝⽞⽟⽠⽡⽢⽣⽤⽥⽦⽧⽨⽩⽪⽫⽬⽭⽮⽯⽰⽱⽲⽳⽴⽵⽶⽷⽸⽹⽺⽻⽼⽽⽾⽿⾀⾁⾂⾃⾄⾅⾆⾇⾈⾉⾊⾋⾌⾍⾎⾏⾐⾑⾒⾓⾔⾕⾖⾗⾘⾙⾚⾛⾜⾝⾞⾟⾠⾡⾢⾣⾤⾥⾦⾧⾨⾩⾪⾫⾬⾭⾮⾯⾰⾱⾲⾳⾴⾵⾶⾷⾸⾹⾺⾻⾼⾽⾾⾿⿀⿁⿂⿃⿄⿅⿆⿇⿈⿉⿊⿋⿌⿍⿎⿏⿐⿑⿒⿓⿔⿕ KangXi Radica

$utf8Str = "❶❷❸❹❺"; $sjisStr = mb_convert_encoding($utf8Str, 'SJIS-mac'); echo(mb_detect_encoding($sjisStr, ['UTF-8','SJIS-mac', 'SJIS-win', 'SJIS'])); // SJIS-win ← SJIS-macに変換したはずなのに、何故かSJIS-winと判定されてしまいます。 そもそもSJIS-macってなんだよって話ですが、単にMacJapaneseのエイリアスです。 従ってMacJapaneseと書いても同じく、正しく誤判定されます。 そしてコメント欄にThis is a bug inPHP's mbstring extension『mbstringエクステンションのバグじゃよ』という人が現れています。 間違ったコードを書いたときに自分のせいでは

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く






