
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
生成AI(人工知能)を含む最新のAI研究動向を知るため、世界中の研究者やエンジニアが参照しているのが、論文速報サイト「arXiv(アーカイブ)」である。米OpenAI(オープンAI)や米Google(グーグル)などAI開発を主導するIT企業の多くが、研究成果をarXivに競って投稿している。 そんなarXivの投稿論文から、2024年5月(1日~31日)にSNSのX(旧Twitter)で多く言及されたAI分野の注目論文を紹介する。調査には米Meltwater(メルトウォーター)のSNS分析ツールを利用した。対象はXの全世界のオリジナル投稿、コメント、再投稿、引用投稿である。調査は、日経BPが2024年1月に新設したAI・データラボの活動の一環として実施した。 Transformer並みの拡張性をLSTMで実現 5月に最も多く言及された論文は、オーストリアの研究チームが発表した「xLSTM:



「Graph Game」はニューラルネットワークの構造をグラフで作成するゲームです。AI技術の発展と共に頻繁に目にするようになった「ニューラルネットワーク」をどの程度理解しているか試せるゲームとのことなので、実際にプレイしてみました。 Graph Game - By Sabrina Ramonov https://graphgame.sabrina.dev/ サイトにアクセスするとこんな感じ。「RNN」「LSTM Cell」「GRU Cell」「ResNetBlock」「Deep RNN」という5つのステージが用意されています。まずは「RNN」をクリックしてみます。 「x_t」「h_t」「y_t」という3つの箱が出現しました。それぞれの箱はデータを表しており、上が出力で下が入力となっています。「x_t」の上の○をクリックし、ドラッグして「h_t」の下に接続します。 緑の線で接続が表示され
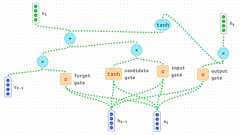
こんにちは、スーパーソフトウエアの船木です。 時系列データの未来の値をディープラーニングで予測する方法を見ていきます。RNN(再帰型ニューラルネットワーク)の一種であるLSTMを使いますが、複雑な数式やロジックではなく実用性やメリットを感じてもらうために入門的な内容です。興味を持った人は、より詳しく数式や論文にあたってもらえればと思います。 また、当然ですが投資取引への勧誘等を目的にしたものではなく、本情報を利用した際の取引等は全て自己の責任において行ってください。 LSTMとは「Long Short Term Memory」の略で、長・短期記憶と呼ばれるディープラーニングのアーキテクチャです。元々RNNは古いアウトプットを次のインプットとして使用することで学習していきますが、長期的な特徴の学習には向いていない仕組みでした。 LSTMの特徴として、RNNの仕組みに加えて長期的記憶をアウトプ
![LSTMで株価予測入門 [Python,Keras] | スーパーソフトウエア東京](/image.pl?url=https%3a%2f%2fcdn-ak-scissors.b.st-hatena.com%2fimage%2fsquare%2fcaa374fff15f84ed4dec099f839bc87e8b2d48b5%2fheight%3d288%3bversion%3d1%3bwidth%3d512%2fhttps%253A%252F%252Fcdn.supersoftware.jp%252Fwp-content%252Fuploads%252F2020%252F03%252F27123346%252Fheader_img7.jpg&f=jpg&w=240)
文書の数が多い場合、単語の種類(ボキャブラリ)も多くなり単語の次元が大幅に増えていきます。 一方、一つの文書に含まれる単語の数には限りがあるため、これは全体として疎行列になります。 また、単語が各次元として扱われますが、文書ごとの出現順序など、単語間での関連性を示す情報は抜け落ちたものとなります。 それに対して低次元(通常数百次元程度)の密な行列で単語の意味を定義する方法があります。 これは、「分散表現」や「埋め込み表現」と言われるものになっております。 この表現を獲得するため手法は様々なものがありますが、ここではWord2Vecを紹介します。 元論文 : Efficient Estimation of Word Representations in Vector Space 具体的な実装についての解説 :word2vec Parameter Learning Explained Wor

見てのとおり、一部のDBのバージョン文字列はかなり長いです。 一度に文字列全体が取得できる状況では長い文字列でも問題はありませんが、応答の内容/時間をもとにバイナリサーチにより1bitずつ特定していく場合、長い文字列の取得にはそれなりの時間がかかります。 さらに、バイナリサーチではなく、LIKE演算子で1文字(または1単語)ずつ特定していく場合には、もっと長い時間がかかります。次の例ではPostgreSの後の1文字を特定しようとしていますが、正解を探すには考えられるすべての文字を試すことになります。 ... CASE WHEN version() LIKE 'PostgreSa%' THEN ... ELSE ... END ... ... CASE WHEN version() LIKE 'PostgreSb%' THEN ... ELSE ... END ... ... CASE WH

はじめに 医療・介護・ヘルスケア・シニアライフの4つの領域で高齢社会の情報インフラを構築している株式会社エス・エム・エスのAnalytics&Innovation推進部( 以下、A&I推進部)でデータ分析基盤開発を担当している長谷川です。 A&I推進部はエス・エム・エス社内のデータを横断的に収集し、データの分析や加工から、データに基づく施策までを行う部門で、現在は介護事業者向け経営支援サービスである「カイポケ」や、介護職向け求人情報サービスである「カイゴジョブ」のデータ分析やレコメンドシステムの開発を行っています。 今回はその中で「カイゴジョブ」における介護求人の課題をディープラーニングによる分類モデルで改善した取り組みについて紹介します。 介護業界の課題 具体的な説明に入る前に、簡単に介護求人の課題感を説明します。 ご存じの通り、昨今の日本は少子高齢化が進み、介護にまつわる課題が毎日のよ

Abstract• Transformer モデルをテキスト生成タスクで使用する場合、計算コストに難がある • 計算コストを抑えつつ Transformer の予測性能を活かすために、Positional Encoding を LSTM に置き換えた LSTM+Transformer モデルを考案 • 生成にかかる時間を Transformer の約 1/3(CPU 実行時)に抑えることができた はじめにTransformer は現在の自然言語処理分野における代表的な深層学習モデルの1つです。さまざまなベンチマークを総なめにしたGoogle の BERT とその派生系 (XLNet, ALBERT,etc.) や、OpenAI の GPT-2 など、最近の研究のベースにあるのが Transformer です。 Transformer の特徴として、LSTM などの従来の RNN にあっ

目次。 目次。 先にこちらを読んでください。 はじめに。 LSTMで日経平均株価予測を行うプログラムを書いてみた話。 上場企業、約4000社の株価予測。 値上がり・値下がり正答率。 1営業日後予測。 5営業日後予測。 元本増加率。 1営業日後予測。 5営業日後予測。 SN比。 1営業日後予測。 5営業日後予測。 時系列データを実際に可視化してみる。 元本増加率が1000番目に高い銘柄。 1営業日後予測。 5営業日後予測。 元本増加率が2000番目に高い銘柄。 1営業日後予測。 5営業日後予測。 元本増加率が3000番目に高い銘柄。 1営業日後予測。 5営業日後予測。 元本増加率が3948番目(最下位)に高い銘柄。 1営業日後予測。 5営業日後予測。 元本増加率が1番目に高い銘柄。 1営業日後予測。 5営業日後予測。 考察とか。 ソースコード(プログラムコード)。 入力する株価データの用意(

3つの要点 ✔️ 慢性腎臓疾患(CKD)の長期的な傾向を抽出する時系列深層学習モデルの提案 ✔️ ランダムサンプリングされた患者データによる T-LSTM を使用 ✔️ 不規則な時間特性を考慮した学習により、CKD患者特有のプロファイルを特定 Learning Deep Representations from Clinical Data for Chronic Kidney Disease written by Duc Thanh Anh Luong,Varun Chandola (Submitted on 1 Oct 2018 (v1), last revised 9 Feb 2019 (this version, v2)]) Comments: Published by arXiv Subjects: Machine Learning (cs.LG);Machine Learnin

 1
1リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


