
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
機械学習エンジニアの吉田です。今回は、LLM (Large Language Models) を活用して、機械学習モデルに必要なデータのアノテーション作業を効率化する取り組みについて紹介します。 なお、アノテーションにおけるLLMの利用に関しては、クラウドベンダー各社及び社内の法務確認のうえ進めています。この記事で登場するLLMがアノテーション用途で使えることを保証するわけではないのでご留意ください。 背景 LayerXで提供しているバクラクでは、帳票をアップロードするだけで支払金額や支払期日などを自動で読み取るOCRの機械学習モデルを開発しています。 このモデルのデータセットを作成するために、内製のアノテーション基盤を使って日々手作業でアノテーションを行っています。帳票の種類が多く、解釈が複数ある場合もあるため、アノテーション作業は簡単ではありません。モデルの推論結果やユーザーの入力値を
ソフトバンクは、2024年7月22日より、AIの教師データを作成するアノテーションサービス「TASUKI Annotation」において、生成AIサービスの回答精度を向上させる「RAGデータ作成ツール」の提供を開始した。 同ツールは、生成AIサービスにおけるRAG(検索拡張生成)の検索精度を向上させるための、データの構造化や回答の評価といった作業を自動化してくれるツール。図表やテキストなどさまざまな形式のデータを容易に構造化できる機能や、回答の引用元データの参照や生成結果が適切かを自動評価する機能を備える。 また、検証用のRAG環境を利用でき、検証したデータは本番環境へスムーズに移行できる。直感的なUIによって、生成AIに対する専門知識がなくても、誰でも簡単にこれらの作業を進めることが可能だ。

Deleted articles cannot be recovered. Draft of this article would be also deleted. Are you sure you want to delete this article? 背景AWS SageMakerについて勉強していたところ、SageMaker Ground Truthは画像にラベリングを行うものとあったので、実際に触ってみました。 試した事(概要)漫画家の矢吹健太郎先生の作品である「ToLoveる-ダークネス-」のヒロインキャラクター画像に対して、キャラクター名をラベリングしてみました。 例えば、 これは「ヤミ」のラベルを付けて、 これは「モモ」のラベルを付けてみる形です。 試した事(詳細) 1. S3にラベリングを行いたい画像をアップロード 今回は12枚の画像(pngファイル)をアップロードし

こんにちは、MLOpsチームです。先日OCRモデルを学習するためのアノテーションにおいて、作業効率を検証するためのPoCとしてアノテーションUIを開発しました。本記事ではこのアノテーションUIにおける工夫について、試用によって得られた知見をまじえつつ紹介します。 はじめに アノテーションUIを開発することとなった背景について説明します。 アノテーションUIとは アノテーションUIは機械学習の学習データを作成するためのUIです。アノテーションUIはアノテーション作業の効率に強く影響し、アノテーション作業によって得られる学習データの量は機械学習の精度に大きく寄与します。したがって、アノテーションUIは機械学習において最も重要なコンポーネントのひとつといえます。UIを開発した背景 キャディではOSSツールなどのUIを用いてアノテーションが行われていましたが、ここに独自の工夫を導入すれば入力効率


共立出版さまより『Human-in-the-Loop機械学習』をご恵贈いただきました。一通り読み終えたので感想を共有します。 映り込みが激しくて写真を撮るのが難しいことで有名な表紙本書は機械学習モデルを訓練するためのデータを人間がどのように用意するかという問題を扱っています。本書の前半では能動学習というラベル付けデータの選び方の技法が、本書の後半では人間が付けたラベルの管理方法やラベル付けのための適切なインターフェースが紹介されています。機械学習におけるデータをいかに作るかということは私自身とても注目している領域です。『Active Learning from the Web(能動学習を使ってウェブから機械学習データを収集する)』という論文を書いたこともありますし、PDF 翻訳サービスの Readable では能動学習に基づいたアノテーションを実際に行っています。そのため本書は非常に
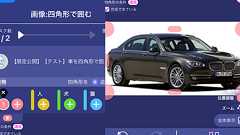
これはGO Inc. Advent Calendar2023 の 12 日目の記事です。 私 kzykmyzw はGO 株式会社でコンピュータビジョンに関する研究開発から実装までを担当しており、本記事もコンピュータビジョンに関連しますが、会社での業務とは無関係です。あまり専門的に深い話はしませんが、ある程度知識のある方を対象としていますのでコンピュータビジョンに関する一般的な用語は解説せずに使います。 はじめに2023 年の 9 月頃に画像認識が可能な GPT-4V(ision) がChatGPT 経由で使えるようになり、2023 年 11 月 6 日に行われた OpenAI DevDay でAPI 経由でも使えるようになったことが発表されました。主な使い方はやはり画像を自然言語で説明させることかと思いますが、普段は物体検出やセマンティックセグメンテーション(以下セマセグ)と

専門家とクラウドワーカーによって行われたラベリング作業と、GPT-4を用いたラベリング作業を比較したところ、GPT-4の作業内容はクラウドワーカーの平均的な作業内容よりも専門家の作業内容に近いものだったことがわかりました。GPT-4に任せることで節約可能な時間は2万時間、節約可能なコストは50万ドル(約6620万円)に上ります。しかし、この事実はクラウドワーキングの先行きが厳しいことも示唆しています。 [2304.03279] Do the RewardsJustify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in theMACHIAVELLI Benchmark https://doi.org/10.48550/arXiv.2304.03279 GPT-4 Outperforms Eli

InnovativeTech: このコーナーでは、テクノロジーの最新研究を紹介するWebメディア「Seamless」を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。Twitter: @shiropen2 スイスのチューリッヒ大学に所属する研究者らが発表した論文「ChatGPT Outperforms Crowd-Workers forText-Annotation Tasks」は、機械学習向け大規模データセットを作成するためのラベル付け作業(アノテーション)において、ChatGPTと人ではどちらがパフォーマンスが良いかを検証した研究報告である。 多くの機械学習モデルでは、学習やテストを行うために高品質なラベル付きデータを必要とする。科学の進歩のため、研究者が特定分野の大規模なラベル付きデータセットを作成して公開する。あとの研究者らは、このデータセット

 Using Amazon SageMaker with Point Clouds: Part 1- Ground Truth for 3D labeling | Amazon Web Services
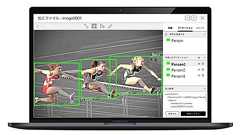
Using Amazon SageMaker with Point Clouds: Part 1- Ground Truth for 3D labeling | Amazon Web ServicesWe will train our detector to specifically detect cars since that’s the most common class in our dataset (32616 of the 42816 total objects in the dataset are labeled as cars). Solution overview In this series, we cover how to visualize and label your data withAmazon SageMaker Ground Truth and demonstrate how to use this data in anAmazon SageMaker training job tocreate an object detection model,

専門部門を発足した理由についてピクスタは「18年に機械学習用途として画像データを販売して以来、年々需要を拡大しており、機械学習案件での売り上げは1年で3倍に拡大している」と説明。アノテーションの付与を内製化することでより柔軟な対応を可能にし、今後も企業のAI開発に寄与したいとしている。 関連記事 人物検知AIの機械学習に「俯瞰人物写真」1000点、ピクスタが発売 画像素材サイト「PIXTA」などを運営するピクスタは、人物検知などのAI開発に使用できる機械学習用素材データセット「俯瞰人物画像素材1000点セット」の販売を始めた。価格は9万9000円から。 “顔だけバーチャルヒューマン”の写真素材、ピクスタが発売 新規事業の可能性探る 画像素材サイト「PIXTA」などを運営するピクスタは、人を模した3DCG「バーチャルヒューマン」の企画・開発を行うCapexと協業し、3DCGと写真を組み合わせ

こんにちは。TURING株式会社でインターンをしている、東京大学学部3年の三輪と九州大学修士1年の岩政です。TURINGは完全自動運転EVの開発・販売を目指すスタートアップです。私たちの所属する自動運転MLチームでは完全自動運転の実現のため、AIモデルの開発や走行データパイプラインの整備を行っています。 完全自動運転を目指すうえで避けて通れない課題の一つに信号機の認識があります。AIが信号機の表示を正しく理解することは、自動運転が手動運転よりも安全な運転を達成するために欠かせません。信号機を確実に認識したうえで、周囲の状況を総合的に判断して車体を制御し、安全かつ快適な走行を実現する必要があります。TURINGでは信号機の認識に取り組むため、15,000枚規模のデータセットを準備し、高精度なモデルのための調査・研究を開始しました。この記事ではデータセットの内製とその背景にフォーカスしつつ


スマートフォンアプリを使ったクラウドソーシングでデータを整備、その効果はAI、機械学習に必要なデータ整備、活用について有識者にインタビューする本連載。前回は、AIが学習するためのデータにラベル付けを行う「アノテーション」を自動化する企業、FastLabelに話を聞いた。 今回は、アノテーション作業をスマホアプリで提供し、クラウドソーシング化することで素早いデータ生成を実現しているAPTOの代表取締役 高品良氏に、アノテーションに対する同社のアプローチなどについて話を聞いた。 APTOは、AIに必要な教師データを作成するアノテーション支援プラットフォームの運営やデータ収集支援事業を手掛ける、2020年に創業したスタートアップ企業だ。同社は、アノテーション作業をクラウドソーシングで効率化できるスマートフォン用アプリ「harBest」を開発、運営している。アノテーション作業の依頼があると、それ
AI活用のボトルネックはデータの整備AIの利用が拡大している。B2C(Business to Consumer)領域でメガプラットフォーマーが提供するサービスだけでなく、B2B(Business to Business)領域のビジネスITにおいてもAIの採用が増えている。 その一因に、企業が保存しているデータの増加がある。特に、IoTセンサーやWeb接続できるカメラなど、日々蓄積される非構造化されたデータは、人間が確認できる容量をはるかに超えている。そこでAIを使ってそのデータを活用したいと考える企業が増えているからだ。 しかし、データをAIで分析するためには準備が必要である。AIが判別できるように、データに「ラベル付け」を行わなければいけない。この作業を「アノテーション」というが、ここに膨大な時間が費やされているという。 その課題解決に目を付け、2020年に創業した企業がFastLab

 Amazon SageMaker Ground Truth が、合成データ生成のサポートを開始
Amazon SageMaker Ground Truth が、合成データ生成のサポートを開始Amazon SageMaker Ground Truth がサポート提供を開始し、手動でラベル付けした実際のデータを大量に集めることなく、ラベル付き合成データを生成できるようになりました。Amazon SageMaker は、Amazon SageMaker Ground Truth Plus とAmazon SageMaker Ground Truth の 2 つのデータラベリングサービスを提供します。どちらのオプションでも、画像、テキストファイル、動画などの生データを識別し、有益なラベルを追加して、機械学習モデル用の高品質のトレーニングデータセットを作成できます。 SageMaker Ground Truth はユーザーに代わってラベル付き合成データを生成するため、実際のデータと合成データを使用して、さまざまなコンピュータービジョンのユースケースで機械学習モデルをトレーニングできま
ソフトバンク株式会社(以下「ソフトバンク」)は、AI(人工知能)を活用したサービスを開発する企業やAIを研究・開発する学術機関向けに、教師データを作成するアノテーション※代行サービス「TASUKI Annotation (タスキアノテーション)」の提供を、2022年6月から本格的に開始しましたのでお知らせします。「TASUKI Annotation」は、ソフトバンクおよびソフトバンクのグループ会社の従業員を対象とした新規事業提案制度「ソフトバンクイノベンチャー」から生まれたサービスです。 昨今、生産性の向上などを目的に企業におけるAIの導入が加速し、自社でAIの開発に取り組む事業会社や、AIの開発を受注するシステム開発会社などが増加しています。一方で、高精度のAIを開発するには、膨大な教師データが必要とされるため、AIエンジニアがその作成に多くの作業時間を費やすことになり、AIモデルの作成

2022-06-28 ソフトバンク、AIの教師データ作成代行サービス「TASUKI Annotation」の提供開始 昨今、企業におけるAIの導入が加速しているが、高精度なAIを開発するには膨大な教師データが必要とされるため、AIモデルの作成など、AIの開発に当たって重要なプロセスに十分な時間を確保できないという課題が生じているという。 そこでソフトバンク株式会社は、AIを活用したサービスを開発する企業やAIを研究・開発する学術機関向けに、教師データを作成するアノテーション代行サービス「TASUKI Annotation(タスキアノテーション)」の提供を、2022年6月から本格的に開始した。 「TASUKI Annotation」は、ソフトバンク社員のエンジニアが発案したサービスで、AIの開発に必要な教師データの作成作業そのものをAIで自動化し、AIの知識を持つ熟練スタッフが、データの品質
リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く






