
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
OpenAI、AIコーディングエージェントをガイドするための「AGENTS.md」サイトを公開OpenAIは2025年8月20日、AIコーディングエージェントをガイドするためのシンプルなフォーマット「AGENTS.md」を案内するサイトを公開した。OpenAI Codexのほか、Amp、GoogleのJules、Cursor、Factory、Roo Codeといったエージェントやツールの開発チームと協力して作ったという。 AGENTS.md The https://t.co/uop4XiFxan microsite is live! Think ofit as a README for agents: asimple, open format forguiding coding agents.It’s been awesome to work alongside peers

私たちは、適切なツールとトレーニングがあれば、すべての開発者がAIエンジニアになれると信じています。GitHub Modelsは、GitHub Codespacesでモデルを使ったプレイグラウンドからコード生成、Azure経由でのデプロイまで、いかにシンプルに行えるかをお見せします。限定パブリックベータへのサインアップはこちらから。 家庭用コンピュータの黎明期から、開発者の創作の主流はコードを使ってソフトウェアをビルド、カスタマイズ、デプロイすることでした。AIの時代となった今日、機械学習モデルを活用する能力という、二次的かつ同様に重要な創造様式が急速に台頭しています。バックエンドとフロントエンドのコードと1つ以上のモデルを含むフルスタックで、生成AIアプリケーションを構築することが増えていながら、ソフトウェア開発者の多くはオープンモデルやクローズドモデルに簡単にアクセスできないままでした

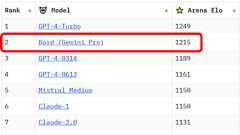
カリフォルニア大学バークレー校・カリフォルニア大学サンディエゴ校・カーネギーメロン大学が協力して設立したオープンな研究組織・Large Model Systems Org(LMSYS Org)は、大規模な機械学習モデルのデータセットやオープンモデル、評価ツールを共同開発しています。LMSYS Orgが自身の開発した大規模言語モデルベンチマークプラットフォームで、GoogleのチャットボットAI「Bard with Gemini Pro」のベンチマークスコアがOpenAIのGPT-4の一部モデルを超えて2位にランクインしたと報告しました。 LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard LM
こんにちは。電通総研コーポレート本部システム推進部の山下です。 最近はChatGPTなどのLarge Language Model(LLM)を利用したAIが話題ですね。 そのLLMを応用したRetrieval-Augmented Generation(RAG)という技術があります。 これは、LLMに文書検索などを用いて関連する情報を与えて回答させることで、 LLMが知識として持っていない内容を回答させたり誤った情報を答えてしまうハルシネーションを抑止する技術です。 今回はこのRAGをLlamaIndexというライブラリを使ってローカル環境で実装する方法について紹介します。 なぜローカル環境でLLMを利用したいのか 大変便利なツールのLLMですが、利用が難しいこともあります。 例えば、機密情報を取扱いたい、外部インターネットへの接続に制限が掛かっているといった場合です。 最終的にOpenAI
マイクロソフト、初心者向け生成AI学習教材「生成AIアプリケーションの開発を始めるために必要な全知識を学べる12講座」を無償公開 コースの内容には、大規模言語モデル(LLM)がどのように動くかを理解する。「生成AI と大規模言語モデルの紹介」、ユースケースに適したAIモデルを選択できるようにする「様々なLLMの調査と比較」、プロンプトの構造と使用法の理解のための「プロンプト・エンジニアリングの基礎」、埋め込み技術を利用したデータ検索アプリケーションを構築する「VectorDatabasesを利用した検索アプリケーションの構築」、外部APIからデータを取得するためFunction Callingを設定する「Function Callingとの統合」など、入門的な内容から高度なアプリケーションの開発まで多岐にわたるレッスンが用意されています。 レッスン内容は日本語による説明と図で構成 各レ

Microsoftやウィスコンシン大学マディソン校などの研究チームが開発し、2023年4月17日に公開した「LLaVA」は「視覚」を持つAIで、画像を入力するとその画像に基づいて返答を行うことができます。2023年10月5日に登場したLLaVA-1.5はさらにクオリティが向上しているとのことなので、実際にGoogleのクラウドコンピューティングサービス「Google Cloud Platform(GCP)」上で動作させてみました。 LLaVA/pyproject.toml at main · haotian-liu/LLaVA https://github.com/haotian-liu/LLaVA2023年4月にリリースされた旧バージョンの性能や、デモサイトの使い方については下記の記事で確認できます。 画像を認識して年齢推測可能&人名クイズにも正答できる無料の高性能チャットAI「LLa

ちょっと古めのドキュメントになってきたので、環境構築以降はぬこぬこさんの「いちばんやさしいローカルLLM」という記事を参考にすることをおすすめします。 https://note.com/schroneko/n/n8b1a5bbc740b こんにちは、Saldraです。普段はPictoriaという会社でAIの美少女の錬成に励んでいるエンジニアです。この記事はローカルLLMの概要をつかむことを目的とします。対象読者は以下です。 なんとなくChatGPT は使ったことある人 ローカル LLM を聞いたことあるけどやったことない人 ローカル LLM とはOpenAIがAPIを公開してから、大規模言語モデル(以降LLMとします)は大きく進化していきました。この進化はOpenAIのAPIだけでなく、ローカルLLMも進化をしています。 ローカルLLMとは「一般向けにファイルとして公開されたモデル」で

DALL-E3を実装日からほぼ毎日使用し面白さにとりつかれています。何となくで触っているため, いまいち思った画像が出来ないことも多々ありましたので今回まじめに作成法を勉強してみました。初級編と名前がついているのは高等テクニックを教えるほどの技術がないだけで後に上級編が控えているという意味ではないです。 0. はじめに DALL-E とはシンプルなテキストのみで画像がつくれるAIです。 簡単なテキストのみで画像生成語源は『ウォーリー探せ』と芸術家の『ダリ』から来ているみたいです。ウィーリーはある種の「探し物」をする, userが提示するテキストのプロンプトから隠された要素やまだ見ぬ画像を「探し出し」生成することらしいです。 ウォーリーをインスパイアした少年1. 問題点, 主に著作権やはり何と言っても著作権問題ではないでしょうか。現在法整備が進行しているところです。OpenAIはコンテンツポ

sponsored 冬こそ始めやすい季節! スマートウォッチとともに外に出よう! 今こそ始めるジョギングやランニング! そんな貴方をガッチリサポートしてくれるスマートウォッチ「HUAWEI WATCH GT 6」 sponsored UltimateプランでRTX 5080相当の性能を堪能、5Kや最大360fpsでのゲームプレイも!PCゲームプレイの選択肢が超広がる! 進化したGeForce NOWが凄すぎる sponsored ダークウェブで攻撃者がやり取りする情報も把握、ASMから進化した“CTEM”=「FortiRecon」 化学メーカーの研究データが漏洩! 脆弱性診断が見落としたVPN装置… どうやったら防げた? sponsored 2025年に多く発生したランサムウェア被害、そのトレンドから考える 最悪の被害「事業停止」を回避するには? ランサムウェア対策・3つのポイント sp

最近流行りのChatGPT。 「色々な作業を自動化した」 「国家試験に合格した」 ニュースで目にする機会も最近は多いと思います。 では、ChatGPTは現段階でどのくらい賢いのでしょうか? 「海外の司法試験で人間を超えた」などの情報をよく耳にしますが、実感が湧きませんよね。 今回は日本人に馴染みの深い大学入学共通テスト(旧センター試験)を題材に、その実力を検証してみました。 実験方法今回は、令和4年度の国語・英語(リーディング)・公民(倫理 /政治・経済)の3科目について実験を行いました。 ※数学・理科等の科目については図表を読み取る問題が多く、正確に試験できないため今回は除外しました。 ポイント①: テキストになおす大学入試センターで公表されている試験問題がPDFのため、ChatGPTに読めるテキスト形式にする必要があります。 今回はGoogle Docsの機能を活用して文字起こしし

株式会社サイバーエージェント(本社:東京都渋谷区、代表取締役:藤田晋、東証プライム市場:証券コード4751)は、最大68億パラメータの日本語LLM(Large Language Model、大規模言語モデル)を一般公開したことをお知らせいたします。 近年、OpenAI社が開発した「ChatGPT」※1 を始めとする生成AI・LLMは急速な進化を遂げており、世界中のあらゆる業界・ビジネスにおいて活用が進んでいます。 一方、既存のLLMのほとんどは英語を中心に学習されているため、日本語および日本文化に強いLLMは少ない状況です。 ■最大68億パラメータの日本語LLM(大規模言語モデル)の公開について こうした背景のもと、当社は日本語LLMの開発に取り組んでおり、このたび一部モデルをHugging Face Hubにて公開いたしました。公開されたモデルはオープンな日本語データ※2で学習したもので


以下の記事を元に、「OpenAIAPI」のファインチューニングの学習データのガイドラインをまとめました。 1. 学習データの書式ファインチューニングするには、単一の入力「プロンプト」とそれに関連する出力 「コンプリーション」 のペアで構成される学習データが必要です。これは、1回のプロンプトで詳細な手順や複数の例を入力するような、ベースモデルの使用方法とは大きく異なります。 「学習データの書式」のガイドラインは、次のとおりです。 ・プロンプトが終了してコンプリーションが開始することをモデルに知らせるため、区切り記号 ("\n\n###\n\n"など) でプロンプトを終了する必要があります。区切り記号は、プロンプトの他の場所で使用されない文字列を指定します。 ・コンプリーションが終了することをモデルに知らせるため、停止記号 ("\n"、"###"など)でコンプリーションを終了する必要がありま

Deleted articles cannot be recovered. Draft of this article would be also deleted. Are you sure you want to delete this article? はじめまして、sonesuke( https://twitter.com/sonesuke ) です。 LLMのニュースを追っかけ続けたので、これからキャッチアップする人用にまとめておきます。 単発のプロンプトテクニックについてはこちらご覧ください。 これだけは知っとけ用語 各手法の説明を読む前に、これらの用語を読んでおくと各手法がわかります。知っている人は飛ばしてください。 プロンプトエンジニアリング 入力(プロンプト)を工夫して性能をあげようというアプローチ。機械学習系で精度アップといえば、追加学習させたりモデルを拡張するのですが

プロンプトを入力するだけで適切なモデルを出力してくれるBlenderのアドオン「BlenderGPT」が登場しました。OpenAIのGPT-4を使用しており、プロンプトを受けてPythonコードを生成します。GitHub - gd3kr/BlenderGPT: Use commands in English to controlBlender withOpenAI's GPT-4 https://github.com/gd3kr/BlenderGPT 導入方法は以下の動画でも確認できます。 3DCG製作ソフト「Blender」にGPT-4を統合する「BlenderGPT」の導入方法を解説 - YouTube まずはGitHubのリポジトリにアクセスします。続いて「Code」をクリックし、「DownloadZIP」をクリックしてZIPファイルをダウンロード。 次にOpenAIのAPI

あるメタファーの空間において二つのメタファーの対比(B)についてGPT4に列挙(1)させ、それからその対比を抽象化(2)させる。その後、抽象化した対比を異なるドメインに応用して具体化(3)させた
リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く








