
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
皆さんは『配列から欠けている数字を見つけろ』と言われたら、どう答えますか? 多くの方は「HashSetで解けばいい」と考えるでしょう。しかし、1000万個の要素で実測したところ、Pythonのsetは945MBもの追加メモリを消費し、処理に2.3秒かかりました。一方、XORを使った解法は追加メモリゼロ、C言語なら1ミリ秒で完了します。 なぜこれほどの差が生まれるのか? XORには単なるトリック以上の深い理論があり、配列の欠損値検出だけでなく、RAID 5のデータ復元やネットワークのエラー検出など、実務で幅広く応用されているのです。 追記: ネットワーク転送時のパケットロスやノイズによるデータ欠損、さらには宇宙線がメモリに衝突してビットが反転する「ソフトエラー」により、配列から要素が失われることがあります。本記事では、Florian Hartmannの「That XOR Trick」1を基
![[速習] 配列から欠けている数字を見つける「XORトリック」の深い理論と実践 - Qiita](/image.pl?url=https%3a%2f%2fcdn-ak-scissors.b.st-hatena.com%2fimage%2fsquare%2f0b154b15631131f57c8997e3e8d59d9b3479fa77%2fheight%3d288%3bversion%3d1%3bwidth%3d512%2fhttps%253A%252F%252Fqiita-user-contents.imgix.net%252Fhttps%25253A%25252F%25252Fqiita-user-contents.imgix.net%25252Fhttps%2525253A%2525252F%2525252Fcdn.qiita.com%2525252Fassets%2525252Fpublic%2525252Ftech-festa-ogp-background-4b5015b2c518c7e6b9062a7c9f5f5e90.png%25253Fixlib%25253Drb-4.0.0%252526w%25253D1200%252526blend64%25253DaHR0cHM6Ly9xaWl0YS11c2VyLXByb2ZpbGUtaW1hZ2VzLmltZ2l4Lm5ldC9odHRwcyUzQSUyRiUyRnMzLWFwLW5vcnRoZWFzdC0xLmFtYXpvbmF3cy5jb20lMkZxaWl0YS1pbWFnZS1zdG9yZSUyRjAlMkYzNTIxNTczJTJGZTBmMGU4NmM4MTg2ZGUzN2NmMGFlNWMxYmIzMzFjNzM5NDIyNjNhOSUyRnhfbGFyZ2UucG5nJTNGMTc1MjIyNTQyMz9peGxpYj1yYi00LjAuMCZhcj0xJTNBMSZmaXQ9Y3JvcCZtYXNrPWVsbGlwc2UmYmc9RkZGRkZGJmZtPXBuZzMyJnM9NjhmYzIyNjMwMzllNGU0NzQyOTE3MGMyZTdjYjExOTY%252526blend-x%25253D120%252526blend-y%25253D467%252526blend-w%25253D82%252526blend-h%25253D82%252526blend-mode%25253Dnormal%252526s%25253Dcc1a59e5a96046a7f38619543aa5f4c8%253Fixlib%253Drb-4.0.0%2526w%253D1200%2526fm%253Djpg%2526mark64%253DaHR0cHM6Ly9xaWl0YS11c2VyLWNvbnRlbnRzLmltZ2l4Lm5ldC9-dGV4dD9peGxpYj1yYi00LjAuMCZ3PTk2MCZoPTMyNCZ0eHQ9JTVCJUU5JTgwJTlGJUU3JUJGJTkyJTVEJTIwJUU5JTg1JThEJUU1JTg4JTk3JUUzJTgxJThCJUUzJTgyJTg5JUU2JUFDJUEwJUUzJTgxJTkxJUUzJTgxJUE2JUUzJTgxJTg0JUUzJTgyJThCJUU2JTk1JUIwJUU1JUFEJTk3JUUzJTgyJTkyJUU4JUE2JThCJUUzJTgxJUE0JUUzJTgxJTkxJUUzJTgyJThCJUUzJTgwJThDWE9SJUUzJTgzJTg4JUUzJTgzJUFBJUUzJTgzJTgzJUUzJTgyJUFGJUUzJTgwJThEJUUzJTgxJUFFJUU2JUI3JUIxJUUzJTgxJTg0JUU3JTkwJTg2JUU4JUFCJTk2JUUzJTgxJUE4JUU1JUFFJTlGJUU4JUI3JUI1JnR4dC1hbGlnbj1sZWZ0JTJDdG9wJnR4dC1jb2xvcj0lMjNGRkZGRkYmdHh0LWZvbnQ9SGlyYWdpbm8lMjBTYW5zJTIwVzYmdHh0LXNpemU9NTYmdHh0LXBhZD0wJnM9NzkzNWE0N2JiOTczYmM0ZmE2OGJjZjI0ZmYxOGM5MzM%2526mark-x%253D120%2526mark-y%253D112%2526blend64%253DaHR0cHM6Ly9xaWl0YS11c2VyLWNvbnRlbnRzLmltZ2l4Lm5ldC9-dGV4dD9peGxpYj1yYi00LjAuMCZ3PTgzOCZoPTU4JnR4dD0lNDBTaGlnZW1vcmlNYXNhdG8mdHh0LWNvbG9yPSUyM0ZGRkZGRiZ0eHQtZm9udD1IaXJhZ2lubyUyMFNhbnMlMjBXNiZ0eHQtc2l6ZT0zNiZ0eHQtcGFkPTAmcz1kODJmMzE4ZjlkN2I5OGFjYjY0Y2YwOGYwNDBlMDE3YQ%2526blend-x%253D242%2526blend-y%253D480%2526blend-w%253D838%2526blend-h%253D46%2526blend-fit%253Dcrop%2526blend-crop%253Dleft%25252Cbottom%2526blend-mode%253Dnormal%2526s%253D8e9fd2cc50111eb1e4f8170976dbfdbf&f=jpg&w=240)
世の中に多くあるエラトステネスの篩の実装、多くあるくせにちょっとしか高速化してないのが悲しいので高速化エラトステネスの篩を書いてみることにします。 エラトステネスの篩の高速化 (1) ← 今ココ エラトステネスの篩の高速化 (2) エラトステネスの篩の高速化 (3) エラトステネスの篩の高速化 (4) エラトステネスの篩の高速化 (5) エラトステネスの篩の高速化 (6) エラトステネスの篩の高速化 (7) 問題設定 とりあえずC++11 くらいで動く物を作りたいと思います。インラインアセンブラやSIMD、並列化は明示的には入れない方針です。あと、エラトステネスの篩自体の高速化を目指すので、結果は一部の具体的な素数の確認と $\pi(x)$ の値で確認することにしますし、その時間は考慮しないことにします。 また、ライブラリ的に使えるよう、将来的には区間篩 (大きな $x$ に対して $

こんにちは👋 長く暑い夏が終わろうとしている今ですが、筆者は秋の季節を満喫しております。 LabBaseでは線形代数学の基礎を使って検索エンジンを構築していますが、レコメンド、検索アルゴリズムによく使われる王道の手法について記事を書くことにしました。 概要 線形代数学の特異値分解(SVD)の知識を活かして、原始的な画像圧縮アルゴリズムをRustで実装します。 SVDとは? SVDは、線形代数学でよく使われる行列の分解です。行列の分解は、同じマトリックスを他のマトリックスに分けて表現することです。SVDの他に、LU三角分解、QR分解などがあります。 SVDは、あるAというマトリックスの列空間と行空間の固有ベクトルを計算して、それぞれをUとVというマトリックスに収めます。さらに、Σという対角行列に、固有値の平方根を入れます。Vの転置行列をV'と定義しますが、以下の分解になります。 Σの体格行

リングバッファのイメージ図 1. リングバッファとは何か 機能的にはFirst In First Out (FIFO)とも呼ばれるキューの一種であるが、リング状にバッファを置いてそれの中でReadとWriteのインデックスがグルグルと回る構造をとる事によって容量に上限ができることと引き換えに高速な読み書き速度を得たものである。キューを単に実装するだけなら山ほど方法があって線形リストを使ってもいいしスタックを2つ使っても原理的には可能だ。その中でもリングバッファを用いた方法の利点はひとえに性能の高さでありメモリ確保などを行わないお陰でシステム系の様々な場所で使われている。 これの実装自体は情報系の大学生の演習レベルの難度であるが少し奥が深い。まずリングバッファのスタンダードなインタフェースと実装は以下のようなものである。 class RingBuffer { public: explicit

Rust でやるゲーム開発アルゴリズムシリーズ、第4弾ぐらいでしょうか? 今回はプログラム的に迷路生成をします。 元々は、四分木による経路探索をテストするために考えたものですが、これはこれで独立した知見になりそうなので別記事にしました。 自然に見える迷路とは 何をもって自然な迷路というかは、人によると思いますが、ここでは次のような感じのものを指します。 ある程度迷路としての構造を持ちながらも、分岐やループを持ち、道幅をいくらか持つことによってエージェント同士がすれ違えるようにします。 また、壁の形状にノイズを加えて単調にならないようにしています。 総合的には、鍾乳洞のような天然の洞窟というほどは自然ぽくはありませんが、完全に人工的な環境というわけでもない、ほどほどに自然な迷路を目指します。 このような地形のプロシージャル生成については、様々な方法があります。 ここで紹介するのはごく一部で、
![[Rust] 自然に見える迷路の生成](/image.pl?url=https%3a%2f%2fcdn-ak-scissors.b.st-hatena.com%2fimage%2fsquare%2f8dacf1b0b1560cad1913c4519c3f590ef6fcd12b%2fheight%3d288%3bversion%3d1%3bwidth%3d512%2fhttps%253A%252F%252Fres.cloudinary.com%252Fzenn%252Fimage%252Fupload%252Fs--nb2LL6oy--%252Fc_fit%25252Cg_north_west%25252Cl_text%253Anotosansjp-medium.otf_55%253A%2525255BRust%2525255D%25252520%252525E8%25252587%252525AA%252525E7%25252584%252525B6%252525E3%25252581%252525AB%252525E8%252525A6%2525258B%252525E3%25252581%25252588%252525E3%25252582%2525258B%252525E8%252525BF%252525B7%252525E8%252525B7%252525AF%252525E3%25252581%252525AE%252525E7%25252594%2525259F%252525E6%25252588%25252590%25252Cw_1010%25252Cx_90%25252Cy_100%252Fg_south_west%25252Cl_text%253Anotosansjp-medium.otf_37%253Amsakuta%25252Cx_203%25252Cy_121%252Fg_south_west%25252Ch_90%25252Cl_fetch%253AaHR0cHM6Ly9saDMuZ29vZ2xldXNlcmNvbnRlbnQuY29tL2EvQUFUWEFKeG5tZ0ZYQlJsZjJpZVh1QWlwOG9LaFdpT2FSczg2dXRzWlcwN3o9czk2LWM%253D%25252Cr_max%25252Cw_90%25252Cx_87%25252Cy_95%252Fv1627283836%252Fdefault%252Fog-base-w1200-v2.png&f=jpg&w=240)
アルゴリズム図鑑 絵で見てわかる26のアルゴリズム 作者:石田保輝,宮崎修一翔泳社Amazon アルゴリズム図鑑を眺めていて、二分ヒープ構造は優先度付きキューに使われることを知った。面白いなーと思うと同時に、そういえば二分ヒープ構造の実装をしたことがなく、あまり理解できていないことに気づいた。そこで簡単にRubyで実装をしてみたのでメモ。簡単なテストケースを作ったので多分合ってると思うけど、もしかしたらバグっているかも... 二分ヒープの詳細は二分ヒープ -Wikipediaも参考。 【2023/01/03 14:01追記】要素数が1の時に要素が空にならないバグがあったので修正しました。コメントありがとうございます。https://github.com/shibayu36/algorithms/commit/6c2ce588f7bc7fb890c6a560c7ab062c6f531a9a

基本的なデータ構造であるヒープについて、概要、計算量と実装、そして最もシンプルな応用であるヒープソートを紹介します。MITが講義や資料を公開しているMIT OpenCourseWareのアルゴリズムとデータ構造の講義 が非常にわかりやすかったので、その内容に沿ってまとめました。この記事ではHeaps and Heap Sortの内容を以下の順序で解説します。 ヒープの概要ヒープの表現ヒープの構築ヒープの計算量ヒープの実装ヒープソート1. ヒープの概要ヒープ (heap) は優先度付きキュー (priority queue) の実装の1つです。優先度付きキューは集合 (set) を扱うデータ型で、集合に含まれる要素が何らかの優先度 (priority) 順に取り出されるという特徴を持っています。学会のポスター発表を回るときや、旅行先での観光地巡りでは、優先度に基づいて要素を取り出すことが重要
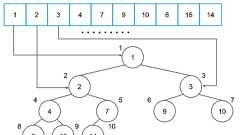
ID を採番するときによく使われるUUID Version 4 の課題として「順序性がなくソートしにくい」という側面があり,ULID (Universally Unique Lexicographically Sortable Identifier) を使えばソートできるようになるという記事を前に書いた. kakakakakku.hatenablog.com 関連して調査をしていたら,標準化団体 IETF (Internet Engineering Task Force) によって,UUID Version 6, 7, 8 という新しい仕様が提案(ドラフト段階)されていることを発見した❗️UUID Version 6, 7, 8 の目的を簡単にまとめると「タイムスタンプ情報を使ってソートできる ID を採番できるようにする」となり,もしこの仕様が取り込まれると,UUID を活用する幅がさ

東大卒、TNK出身の勝俣社長と、慶應卒の金田氏が主要経営陣とのこと。 株主にもエアトリやトレンダーズなど上場企業が並びます。 こちらのアルゴリズム社が、年商40億円、利益率はキーエンス超えしているとのこと。。その一方で、このインタビュー記事の中身を読んでも事業は全く不明。 ベギラマくんからも、「事業内容を話さないという強い意志を感じる」と指摘されています。 話題になっていたアルゴリズムさん面白い。スポンサードで2本記事出しているけど、絶対に事業内容を話さないという強い意思を感じる。Wantedly見てもほぼ事業内容は記載がない。でも人手は欲しい。M&Aも積極的。 つまり事業モデルは一定カネがある企業であれば真似ができるので早めにEXITしたいのか。 pic.twitter.com/nkMxQ5DuT2 — ベギラマくん (@cogitopp) October 13,2022 今回はこちら

なぎせ ゆうき @nagiseゲームで 「壁をすり抜けるバグどうなってんだ!?」 みたいに言われがちですけども、プログラミングやると 「すり抜けない衝突判定、どうやってんだ!?」 ってなりますからね🤔2022-09-28 17:07:17 リンクWikipedia 衝突判定 衝突判定(しょうとつはんてい、Collision Detection)とは、「2つ以上のオブジェクトの交差を検出する」という計算機科学上の問題であり、具体的には「ある物体が別の物体に当たったか(衝突したか)どうか」を判定するプログラム処理のことを指す。ロボット工学、計算物理学、コンピュータゲーム、コンピュータシミュレーション、計算幾何学など、さまざまなコンピューティング分野で応用されている。 衝突判定のアルゴリズムは、2Dオブジェクト同士の衝突判定と3Dオブジェクト同士の衝突判定に分けることができる。 ビ 14

はじめに このドキュメントは,主に競技プログラミングで出題される問題を解く際に利用できるアルゴリズムやデータ構造をまとめたものです.特定の問題にはあまりフォーカスしないため,問題を解く際の考察の仕方等の内容はありません.詳しく,正確に,分かりやすく書いていこうと思っています. このドキュメントは執筆途中です. 想定する読者C++を用いたプログラミングに慣れている方を読者として想定しており,C++言語の仕様や,文法にはあまり触れません.また,計算量という用語についても説明しません.ただし,償却計算量など,計算量の見積もりが複雑なものについては必要に応じて説明します. コードについて このドキュメントで登場するコードは,可読性向上のため,以下のようなコードがファイルの先頭に記述してあることを前提としています.また,適切な問題を用いてコードの検証がなされている場合は,コード周辺にのように,検証
絶対に勝てない6x6リバーシを作りました。あなたは黒番、AIが白番です。 絶対に勝てない6x6リバーシを作りました! ぜひ挑戦してみてくださいhttps://t.co/Ul5n3q9jMp— Yusuke Endoh (@mametter) December 30, 2021 これは何? 6x6の盤面のリバーシは後手必勝 *1 であることが知られています。 このAIは白番(後手)で完璧にプレイします。つまり黒番のあなたは絶対に勝てません。無力感を楽しんでください。技術的な話 このAIはWebAssemblyになっているので、全部あなたのブラウザの上で動いてます。真のサーバーレスです。AIのソースコードはRustで書きました。わりと堅実なゲーム木探索になってます。UIは普通にTypeScriptとthree.jsで実装しました。github.com 作った順に説明します。 盤面の表現

Deleted articles cannot be recovered. Draft of this article would be also deleted. Are you sure you want to delete this article? とても久しぶりです! 1 年ぶりの投稿となりました、大槻 (通称、けんちょん) です。 去年、『AtCoder 版!マスター・オブ・整数』と題して、プログラミングコンテストで出題される整数問題を解くときに有効な考え方を特集する記事を 2本書きました!AtCoder 版!マスター・オブ・整数 (素因数分解編)AtCoder 版!マスター・オブ・整数 (最大公約数編) 今回はその続編として、素数を列挙するアルゴリズムであるエラトステネスの篩を特集していきます。なお今回の記事の内容は、競プロへの応用を意識していますが、純粋に数学的興味に

画像は公式サイトより 東京大学素粒子物理国際研究センター(ICEPP)の研究者が選定・執筆した、量子コンピューティングを手を動かして学びたい人向けの入門教材「量子コンピューティング・ワークブック」が無料公開されている。SNS上では本教材について「面白そう!」「いい時代になったなぁ」などのコメントが見られる。本教材は、量子力学や計算科学の前提知識を極力必要とせず、大学1年程度の数学とPythonプログラミングの知識があれば、ゼロから量子コンピューティングを自習できるような教材を目指しているという。 公式サイトより 内容は「量子コンピュータに触れる」「超並列計算機としての量子コンピュータ」「量子ダイナミクスシミュレーション」「ショアのアルゴリズム」「グローバーのアルゴリズム」「変分法と変分量子固有値ソルバー」「量子・古典ハイブリッド機械学習」「補足」で成り立っている。 公式サイトでは「私たち

指針 厳密解法に対しては、解ける問題例の規模の指針を与える。数理最適化ソルバーを使う場合には、Gurobi かmypulpを用い、それぞれの限界を調べる。動的最適化の場合には、メモリの限界について調べる。 近似解法に対しては、近似誤差の指針を与える。 複数の定式化を示し、どの定式化が実務的に良いかの指針を示す。 出来るだけベンチマーク問題例を用いる。OR-Libraryなどから問題例をダウンロードし、ディレクトリごとに保管しておく。 解説ビデオもYoutubeで公開する. 主要な問題に対してはアプリを作ってデモをする. 以下,デモビデオ: 注意 基本的には,コードも公開するが,github自体はプライベート そのうち本にするかもしれない(予約はしているが, 保証はない).プロジェクトに参加したい人は,以下の技量が必要(github, nbdev, poetry, gurobi); ペー
真偽はともかく、ちょっととんでもない論文が出てきたんだが。国際暗号学会の未査読論文だが、素因数分解を (RSA を破壊するレベルで) 劇的に高速化するアルゴリズムを開発したと主張している。 https://t.co/ApzLqRmjqR

こんにちは!エンジニアリンググループ マルチデバイスチーム 新卒1年目の小林です。 エムスリーでは、2週間に1度、Tech Talkという社内LT会(現在はリモートで)が開催されています。これは、とある回の発表テーマリストです。Tech Talkのとある回の発表テーマリスト このように、最近エムスリーでは文字列が流行っている(?)ようなので、その勢いに乗って私も文字列照合アルゴリズムについて書きたいと思います!(業務とは全然関係ない話です) Knuth-Morris-PrattやBoyer-Mooreアルゴリズムは解説記事がたくさん出ていると思うので、この記事ではシンプルかつ高速なQuick-SearchとQuite-Naiveアルゴリズムについて説明し、速度比較を行った結果についてご紹介します。 文字列照合アルゴリズムとは テキストとパターンという文字列が与えられたときに、中に出現す

今回は、以下のように指定しました。表示オプションはデフォルトのままです。 地点を選ぶ:東京 項目を選ぶ(データの種類):時別値 項目を選ぶ(項目):気温 期間を選ぶ:2019/1/1~2019/12/6 データの項目は「日時」「気温」「品質情報」「均質番号」の4種類。品質情報、均質番号は、観測値が正常かどうかに関する情報です。各項目の詳細については、同サイトの「ダウンロードファイル(CSVファイル)の形式」ページを参照してください。 ファイルの先頭5行には、次の画像のような項目が入っています。このまま使うとやや面倒なので、あらかじめ先頭5行分は削除し、全てデータ行のみのCSVファイルに加工しておきます。CSVファイルの仕様にはバリエーションがあり、その全てに対応するとコードが複雑になりますので、今回は気象庁のCSVデータに基づき、次の仕様を前提とします。 文字種は、ANK(1バイト文字)

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く







