Model-Based Transfer Learning

Daisy picture (source: flowers dataset)
In many machine learning cases, the learner has access to a very small amount of labeled data. This is the case for example in radiology when we want to learn a tumor classification task from X-ray images. The number of images available will be very small compared to the complexity of the task. On the other hand, there are very large labeled image datasets likeImageNet on which huge neural networks have been pre-trained to classify different types of items. AlthoughImageNet items differ significantly from X-ray images, the features extracted by a neural network on both task will be more or less the same (filters, contour, contrast…). Thus, a widely used transfer learning method consists in transferring pre-trained networks on particular datasets.
In this type of transfer, the learner has access to a\(f_S\) source model with parameters\(\beta_S\) (for example a largeResNet50 neural network) which has been trained on a source dataset\((X_S, y_S)\) which is no longer available (for computing power or confidentiality reasons for example). This is called “source-free domain adaptation” or “model-based transfer” (see theClassification oftransfer methods). In most cases, a small set of labeled target data\((X_T, y_T)\) is available. The goal is then to specify\(f_S\) on\((X_T, y_T)\) by modifying the\(\beta_S\) parameters. This is calledfine-tuning. In general this approach is more efficient than learning a\(f_T\) model directly on\((X_T, y_T)\) (with few data we lack information).
Here, we will study this type of transfer on a case of flowers classification. We use theflowers dataset and transfer methods from theADAPT library. We will see how to use ADAPT deep transfer methods on an image dataset.
[15]:
importosimportnumpyasnpimporttensorflowastfimportmatplotlib.pyplotaspltfromPILimportImage
First, you have to download the datasethere. Then store it in a path folder specified bypath_to_flower_dataset. The dataset contains 5 different flower classes: daisy, dandelion, rose, sunflower and tulip.
As the dataset is too big to fit in RAM on the notebook, we will use thedataset generator of Tensorflow to fetch the images in the folder at each batch. For this we will create the list of path to the images and the list of labels.
[8]:
path="flowers/flowers/"# path to the downloaded flowers datasetX_path=[]y=[]fig,axes=plt.subplots(1,5,figsize=(16,5))i=0forr,d,finos.walk(path):fordirectind:ifnot".ipynb_checkpoints"indirect:forr,d,finos.walk(os.path.join(path,direct)):forfileinf:path_to_image=os.path.join(r,file)ifnot".ipynb_checkpoints"inpath_to_image:X_path.append(path_to_image)y.append(direct)axes[i].imshow(plt.imread(X_path[-1]))axes[i].set_title(y[-1])i+=1plt.show()

We will now onehotencode the labels and create two index sets for train and test. We consider that the learner has access to a small train dataset of 20% of the total dataset, that corresponds to 863 data.
[12]:
fromsklearn.preprocessingimportOneHotEncoderfromsklearn.model_selectionimporttrain_test_splitone=OneHotEncoder(sparse=False)y_lab=one.fit_transform(np.array(y).reshape(-1,1))np.random.seed(0)train_indexes,test_indexes=train_test_split(np.arange(len(X_path)),train_size=0.2,shuffle=True)print("Train size:%i, Test size:%i"%(len(train_indexes),len(test_indexes)))
Train size: 863, Test size: 3455
As we have said before, the whole image dataset might take too much space in RAM, so we create two dataset generators that fetch the data from the path and preprocess in the ResNet50 format. We also create a load function for the ResNet, in this function we set thetrainable parameter of theBatchNormalizationLayer toFalse to avoid problems later during fine-tuning (see theTensorflow documentation about the issuewith BatchNormalization). We don’t take the last layer of the ResNet which is used to give the classes, because the ResNet has not been trained to classify between the 5 classes of flowers.
[31]:
fromtensorflow.keras.applications.resnet50importResNet50,preprocess_inputfromtensorflow.keras.modelsimportload_modeldefgenerator_train(only_X=False):foriintrain_indexes:image=Image.open(X_path[i])image=image.resize((224,224),Image.ANTIALIAS)X=np.array(image,dtype=int)ifonly_X:yieldpreprocess_input(X)else:yield(preprocess_input(X),y_lab[i])defgenerator_test(only_X=False):foriintest_indexes:image=Image.open(X_path[i])image=image.resize((224,224),Image.ANTIALIAS)X=np.array(image,dtype=int)ifonly_X:yieldpreprocess_input(X)else:yield(preprocess_input(X),y_lab[i])data_train=tf.data.Dataset.from_generator(generator_train,output_types=(tf.float32,tf.float32),output_shapes=([224,224,3],[5]))data_test=tf.data.Dataset.from_generator(generator_test,output_types=(tf.float32,tf.float32),output_shapes=([224,224,3],[5]))X_train=tf.data.Dataset.from_generator(generator_train,args=(True,),output_types=tf.float32,output_shapes=[224,224,3])X_test=tf.data.Dataset.from_generator(generator_test,args=(True,),output_types=tf.float32,output_shapes=[224,224,3])defload_resnet50(path="resnet50.hdf5"):model=ResNet50(include_top=False,input_shape=(224,224,3),pooling="avg")foriinrange(len(model.layers)):ifmodel.layers[i].__class__.__name__=="BatchNormalization":model.layers[i].trainable=Falsereturnmodel
Training a model from scratch
To get an idea of the potential gain of using transfer, we will first look at the perfroamnces that can be obtained by training a model using only the 863 flowers data that we have. We will create a convolutional model and train it on this small training dataset.
[35]:
fromtensorflow.kerasimportModel,Sequentialfromtensorflow.keras.layersimportDense,Input,Dropout,Conv2D,MaxPooling2D,Layerfromtensorflow.keras.layersimportFlatten,Reshape,BatchNormalizationfromtensorflow.keras.optimizersimportAdamclassRescaling(Layer):def__init__(self,scale=1.,offset=0.):super().__init__()self.scale=scaleself.offset=offsetdefcall(self,inputs):returninputs*self.scale+self.offsetdefget_model(input_shape=(224,224,3)):inputs=Input(input_shape)modeled=Rescaling(1./127.5,offset=-1.0)(inputs)modeled=Conv2D(32,5,activation='relu')(modeled)modeled=MaxPooling2D(2,2)(modeled)modeled=BatchNormalization()(modeled)modeled=Conv2D(48,5,activation='relu')(modeled)modeled=BatchNormalization()(modeled)modeled=MaxPooling2D(2,2)(modeled)modeled=Conv2D(64,5,activation='relu')(modeled)modeled=BatchNormalization()(modeled)modeled=MaxPooling2D(2,2)(modeled)modeled=Conv2D(128,5,activation='relu')(modeled)modeled=BatchNormalization()(modeled)modeled=MaxPooling2D(2,2)(modeled)modeled=Flatten()(modeled)modeled=Dropout(0.5)(modeled)modeled=Dense(5,activation="softmax")(modeled)model=Model(inputs,modeled)model.compile(optimizer=Adam(0.001),loss='categorical_crossentropy',metrics=["acc"])returnmodelmodel=get_model()model.summary()
Model: "functional_5"_________________________________________________________________Layer (type) Output Shape Param #=================================================================input_4 (InputLayer) [(None, 224, 224, 3)] 0_________________________________________________________________rescaling_3 (Rescaling) (None, 224, 224, 3) 0_________________________________________________________________conv2d_12 (Conv2D) (None, 220, 220, 32) 2432_________________________________________________________________max_pooling2d_12 (MaxPooling (None, 110, 110, 32) 0_________________________________________________________________batch_normalization_12 (Batc (None, 110, 110, 32) 128_________________________________________________________________conv2d_13 (Conv2D) (None, 106, 106, 48) 38448_________________________________________________________________batch_normalization_13 (Batc (None, 106, 106, 48) 192_________________________________________________________________max_pooling2d_13 (MaxPooling (None, 53, 53, 48) 0_________________________________________________________________conv2d_14 (Conv2D) (None, 49, 49, 64) 76864_________________________________________________________________batch_normalization_14 (Batc (None, 49, 49, 64) 256_________________________________________________________________max_pooling2d_14 (MaxPooling (None, 24, 24, 64) 0_________________________________________________________________conv2d_15 (Conv2D) (None, 20, 20, 128) 204928_________________________________________________________________batch_normalization_15 (Batc (None, 20, 20, 128) 512_________________________________________________________________max_pooling2d_15 (MaxPooling (None, 10, 10, 128) 0_________________________________________________________________flatten_3 (Flatten) (None, 12800) 0_________________________________________________________________dropout_3 (Dropout) (None, 12800) 0_________________________________________________________________dense_3 (Dense) (None, 5) 64005=================================================================Total params: 387,765Trainable params: 387,221Non-trainable params: 544_________________________________________________________________
[24]:
model.fit(data_train.batch(32),epochs=20,validation_data=data_test.batch(32))
Epoch 1/2027/27 [==============================] - 120s 4s/step - loss: 2.8724 - acc: 0.3835 - val_loss: 4.0791 - val_acc: 0.1667Epoch 2/2027/27 [==============================] - 104s 4s/step - loss: 2.2739 - acc: 0.4705 - val_loss: 2.9788 - val_acc: 0.3080Epoch 3/2027/27 [==============================] - 105s 4s/step - loss: 2.0500 - acc: 0.5342 - val_loss: 1.9133 - val_acc: 0.3540Epoch 4/2027/27 [==============================] - 107s 4s/step - loss: 1.5245 - acc: 0.5979 - val_loss: 1.7637 - val_acc: 0.4295Epoch 5/2027/27 [==============================] - 106s 4s/step - loss: 1.2288 - acc: 0.6802 - val_loss: 2.0211 - val_acc: 0.4379Epoch 6/2027/27 [==============================] - 103s 4s/step - loss: 1.0851 - acc: 0.6825 - val_loss: 2.2675 - val_acc: 0.4370Epoch 7/2027/27 [==============================] - 105s 4s/step - loss: 1.0882 - acc: 0.7034 - val_loss: 2.4987 - val_acc: 0.4356Epoch 8/2027/27 [==============================] - 101s 4s/step - loss: 0.9022 - acc: 0.7590 - val_loss: 2.7729 - val_acc: 0.4368Epoch 9/2027/27 [==============================] - 102s 4s/step - loss: 0.7166 - acc: 0.7949 - val_loss: 2.3677 - val_acc: 0.4619Epoch 10/2027/27 [==============================] - 102s 4s/step - loss: 0.6266 - acc: 0.8216 - val_loss: 2.8385 - val_acc: 0.4507Epoch 11/2027/27 [==============================] - 104s 4s/step - loss: 0.6592 - acc: 0.8169 - val_loss: 3.2013 - val_acc: 0.4408Epoch 12/2027/27 [==============================] - 105s 4s/step - loss: 0.6172 - acc: 0.8239 - val_loss: 2.9562 - val_acc: 0.4779Epoch 13/2027/27 [==============================] - 104s 4s/step - loss: 0.5411 - acc: 0.8586 - val_loss: 2.7651 - val_acc: 0.4834Epoch 14/2027/27 [==============================] - 102s 4s/step - loss: 0.4897 - acc: 0.8667 - val_loss: 3.1419 - val_acc: 0.4637Epoch 15/2027/27 [==============================] - 100s 4s/step - loss: 0.3559 - acc: 0.8934 - val_loss: 2.4262 - val_acc: 0.5334Epoch 16/2027/27 [==============================] - 102s 4s/step - loss: 0.2727 - acc: 0.8980 - val_loss: 3.1428 - val_acc: 0.4935Epoch 17/2027/27 [==============================] - 100s 4s/step - loss: 0.2547 - acc: 0.9154 - val_loss: 2.6615 - val_acc: 0.5378Epoch 18/2027/27 [==============================] - 103s 4s/step - loss: 0.1269 - acc: 0.9571 - val_loss: 2.8480 - val_acc: 0.5621Epoch 19/2027/27 [==============================] - 100s 4s/step - loss: 0.1670 - acc: 0.9513 - val_loss: 2.7825 - val_acc: 0.5531Epoch 20/2027/27 [==============================] - 100s 4s/step - loss: 0.1152 - acc: 0.9548 - val_loss: 2.6780 - val_acc: 0.5647
[24]:
<tensorflow.python.keras.callbacks.History at 0x7f833adf4748>
[28]:
acc=model.history.history["acc"];val_acc=model.history.history["val_acc"]plt.plot(acc,label="Train acc - final value:%.3f"%acc[-1])plt.plot(val_acc,label="Test acc - final value:%.3f"%val_acc[-1])plt.legend();plt.xlabel("Epochs");plt.ylabel("Acc");plt.show()

We observe that the performances on the test dataset are not at the level of the train, we have about 57% of accuracy, which is not very satisfactory. There is some overfitting here since the train score reaches 95%, the network we used could perhaps be optimized to increase the test score but we will study here the effect of using a pre-trained model.
Model-based Transfer
We will now look at what can be obtained by using the ResNet, we will study two ways of transferring:
Features Extraction**: We use directly the last hidden layer of the ResNet as input features for a new smaller model.
Fine-Tuning**: We train a new smaller model on top of the ResNet and fine-tune the weights of the ResNet at the same time
We will use a neural network with two hidden layers of 1024 neurons as task network after the ResNet, the last layer has 5 neurons for the 5 classes.
[29]:
defget_task():model=Sequential()model.add(Dense(1024,activation="relu"))model.add(Dropout(0.5))model.add(Dense(1024,activation="relu"))model.add(Dropout(0.5))model.add(Dense(5,activation="softmax"))returnmodel
Features Extraction
We create two data setsX_train_enc andX_test_enc from the outputs of the ResNet:
[41]:
resnet50=load_resnet50()X_train_enc=resnet50.predict(X_train.batch(32))X_test_enc=resnet50.predict(X_test.batch(32))print("X train shape:%s"%str(X_train_enc.shape))
X train shape: (863, 2048)
Let’s fit then atask network on the train set:
[39]:
task=get_task()task.compile(loss="categorical_crossentropy",optimizer=Adam(0.001),metrics=["acc"])task.fit(X_train_enc,y_lab[train_indexes],epochs=20,batch_size=32,validation_data=(X_test_enc,y_lab[test_indexes]))
Epoch 1/2027/27 [==============================] - 1s 34ms/step - loss: 1.2552 - acc: 0.6257 - val_loss: 0.4388 - val_acc: 0.8495Epoch 2/2027/27 [==============================] - 1s 26ms/step - loss: 0.4964 - acc: 0.8297 - val_loss: 0.3922 - val_acc: 0.8692Epoch 3/2027/27 [==============================] - 1s 28ms/step - loss: 0.3568 - acc: 0.8806 - val_loss: 0.4007 - val_acc: 0.8703Epoch 4/2027/27 [==============================] - 1s 27ms/step - loss: 0.2544 - acc: 0.9154 - val_loss: 0.3593 - val_acc: 0.8868Epoch 5/2027/27 [==============================] - 1s 25ms/step - loss: 0.1809 - acc: 0.9351 - val_loss: 0.4353 - val_acc: 0.8729Epoch 6/2027/27 [==============================] - 1s 26ms/step - loss: 0.1650 - acc: 0.9409 - val_loss: 0.3978 - val_acc: 0.8906Epoch 7/2027/27 [==============================] - 1s 26ms/step - loss: 0.1290 - acc: 0.9594 - val_loss: 0.3897 - val_acc: 0.8874Epoch 8/2027/27 [==============================] - 1s 26ms/step - loss: 0.0938 - acc: 0.9641 - val_loss: 0.4998 - val_acc: 0.8735Epoch 9/2027/27 [==============================] - 1s 26ms/step - loss: 0.0711 - acc: 0.9768 - val_loss: 0.4365 - val_acc: 0.8891Epoch 10/2027/27 [==============================] - 1s 26ms/step - loss: 0.0615 - acc: 0.9826 - val_loss: 0.4359 - val_acc: 0.8903Epoch 11/2027/27 [==============================] - 1s 25ms/step - loss: 0.0595 - acc: 0.9780 - val_loss: 0.4955 - val_acc: 0.8822Epoch 12/2027/27 [==============================] - 1s 25ms/step - loss: 0.0693 - acc: 0.9791 - val_loss: 0.4481 - val_acc: 0.8935Epoch 13/2027/27 [==============================] - 1s 26ms/step - loss: 0.0413 - acc: 0.9803 - val_loss: 0.5638 - val_acc: 0.8825Epoch 14/2027/27 [==============================] - 1s 28ms/step - loss: 0.0270 - acc: 0.9919 - val_loss: 0.5338 - val_acc: 0.8949Epoch 15/2027/27 [==============================] - 1s 27ms/step - loss: 0.0367 - acc: 0.9884 - val_loss: 0.5655 - val_acc: 0.8822Epoch 16/2027/27 [==============================] - 1s 28ms/step - loss: 0.0473 - acc: 0.9861 - val_loss: 0.6070 - val_acc: 0.8828Epoch 17/2027/27 [==============================] - 1s 26ms/step - loss: 0.0489 - acc: 0.9803 - val_loss: 0.5536 - val_acc: 0.8900Epoch 18/2027/27 [==============================] - 1s 26ms/step - loss: 0.0362 - acc: 0.9849 - val_loss: 0.5445 - val_acc: 0.8920Epoch 19/2027/27 [==============================] - 1s 27ms/step - loss: 0.0200 - acc: 0.9942 - val_loss: 0.6624 - val_acc: 0.8851Epoch 20/2027/27 [==============================] - 1s 27ms/step - loss: 0.0229 - acc: 0.9884 - val_loss: 0.5932 - val_acc: 0.8944
[39]:
<tensorflow.python.keras.callbacks.History at 0x7f82c40b5c50>
[40]:
acc=task.history.history["acc"];val_acc=task.history.history["val_acc"]plt.plot(acc,label="Train acc - final value:%.3f"%acc[-1])plt.plot(val_acc,label="Test acc - final value:%.3f"%val_acc[-1])plt.legend();plt.xlabel("Epochs");plt.ylabel("Acc");plt.show()
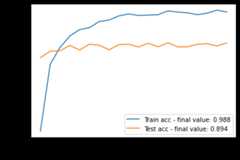
You can clearly see that the results obtained are much better: 0.89% of accuracy instead of 0.57%! We can say that the features extracted from the ResNet50 make sense for our set of flower images. As the ResNet has been trained on a large dataset we can also consider that the features of the last layer are more general which leads to reduce the overfitting.
Fine-Tuning
Previously, we have fixed the parameters of the ResNet50, we will see if a gain is possible by fine-tuning them with respect to the flower classification task. Note that we don’t want to change completely the parameters of the ResNet because otherwise we lose the information of the sources and we come back to a target only model and thus to the risk of overfitting. This is why we will update the ResNet parameters more slowly than those of the task model. We will also pre-train the task modelwith the ResNet parameters fixed to avoid that the first updates of the ResNet are made using the gradients returned by a poor task model.
We will use theFineTuning object of the ADAPT library which allows to easily implement such a finetuning. Note that we could use directly thetask model that we have just trained above, but to see how to use FineTuning directly we will do a pre-training.
[42]:
fromadapt.parameter_basedimportFineTuningencoder=load_resnet50()task=get_task()optimizer=Adam(0.001)optimizer_enc=Adam(0.00001)finetunig=FineTuning(encoder=encoder,task=task,optimizer=optimizer,optimizer_enc=optimizer_enc,loss="categorical_crossentropy",metrics=["acc"],copy=False,pretrain=True,pretrain__epochs=10)
WARNING:tensorflow:No training configuration found in the save file, so the model was *not* compiled. Compile it manually.
As we can see above, we need to define anencoder network (our ResNet) which will do the feature extraction and atask network. We define two optimizers:optimizer_enc for the encoder andòptimizer for the task. We take a much smaller learning rate foroptimizer_enc, here we took 100 times less. To specify that we want to pre-train thetask model on the fixed encoder, we set thepretrain parameter toTrue, then we specify the number of pre-training epochs with thepretrain__epochs parameter. We also specify the loss and the metrics. Notice that we set the parametercopy toFalse to avoid a copy of the ResNet which would increase the memory usage for no reason.
[43]:
finetunig.fit(data_train,epochs=10,batch_size=32,validation_data=data_test.batch(32))
WARNING:tensorflow:Layer fine_tuning is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because its dtype defaults to floatx.If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.Epoch 1/1027/27 [==============================] - 194s 7s/step - loss: 1.2252 - acc: 0.6176 - val_loss: 0.5543 - val_acc: 0.8014Epoch 2/1027/27 [==============================] - 203s 8s/step - loss: 0.4900 - acc: 0.8482 - val_loss: 0.4472 - val_acc: 0.8452Epoch 3/1027/27 [==============================] - 201s 7s/step - loss: 0.3342 - acc: 0.8830 - val_loss: 0.4226 - val_acc: 0.8669Epoch 4/1027/27 [==============================] - 197s 7s/step - loss: 0.2531 - acc: 0.9050 - val_loss: 0.3568 - val_acc: 0.8886Epoch 5/1027/27 [==============================] - 199s 7s/step - loss: 0.1572 - acc: 0.9397 - val_loss: 0.4225 - val_acc: 0.8735Epoch 6/1027/27 [==============================] - 198s 7s/step - loss: 0.1476 - acc: 0.9502 - val_loss: 0.3722 - val_acc: 0.8915Epoch 7/1027/27 [==============================] - 197s 7s/step - loss: 0.1073 - acc: 0.9594 - val_loss: 0.4256 - val_acc: 0.8805Epoch 8/1027/27 [==============================] - 193s 7s/step - loss: 0.1003 - acc: 0.9664 - val_loss: 0.4589 - val_acc: 0.8854Epoch 9/1027/27 [==============================] - 193s 7s/step - loss: 0.0820 - acc: 0.9745 - val_loss: 0.4451 - val_acc: 0.8874Epoch 10/1027/27 [==============================] - 193s 7s/step - loss: 0.0485 - acc: 0.9849 - val_loss: 0.4707 - val_acc: 0.8868Epoch 1/1027/27 [==============================] - 294s 11s/step - loss: 0.0672 - acc: 0.9780 - val_loss: 0.5075 - val_acc: 0.8802Epoch 2/1027/27 [==============================] - 294s 11s/step - loss: 0.0716 - acc: 0.9768 - val_loss: 0.5479 - val_acc: 0.8776Epoch 3/1027/27 [==============================] - 293s 11s/step - loss: 0.0724 - acc: 0.9791 - val_loss: 0.4892 - val_acc: 0.8836Epoch 4/1027/27 [==============================] - 293s 11s/step - loss: 0.0513 - acc: 0.9815 - val_loss: 0.4357 - val_acc: 0.9033Epoch 5/1027/27 [==============================] - 294s 11s/step - loss: 0.0219 - acc: 0.9930 - val_loss: 0.5104 - val_acc: 0.8891Epoch 6/1027/27 [==============================] - 295s 11s/step - loss: 0.0166 - acc: 0.9965 - val_loss: 0.5059 - val_acc: 0.8889Epoch 7/1027/27 [==============================] - 309s 11s/step - loss: 0.0159 - acc: 0.9954 - val_loss: 0.4562 - val_acc: 0.8973Epoch 8/1027/27 [==============================] - 294s 11s/step - loss: 0.0412 - acc: 0.9896 - val_loss: 0.7151 - val_acc: 0.8423Epoch 9/1027/27 [==============================] - 294s 11s/step - loss: 0.0097 - acc: 0.9954 - val_loss: 0.4253 - val_acc: 0.9080Epoch 10/1027/27 [==============================] - 292s 11s/step - loss: 0.0204 - acc: 0.9930 - val_loss: 0.5102 - val_acc: 0.8923[43]:
<adapt.parameter_based._finetuning.FineTuning at 0x7f81e04ef080>
[44]:
acc=finetunig.history.history["acc"];val_acc=finetunig.history.history["val_acc"]plt.plot(acc,label="Train acc - final value:%.3f"%acc[-1])plt.plot(val_acc,label="Test acc - final value:%.3f"%val_acc[-1])plt.legend();plt.xlabel("Epochs");plt.ylabel("Acc");plt.show()

We observe that the finetuned network performs better than the network trained from scratch, however the performances are not really higher than the one of the feature-extraction method. In some cases the features given by the ResNet are already very good, by modifying them we take the risk to lose in generalization, here the flower dataset is quite close to the ImageNet dataset but in other cases (as X-ray images) it can be interesting to modify the ResNet.