TensorFlowのチュートリアルをやってみる(1)
概要
TensorFlowがだいぶ落ち着いてきてる感(Python3系に対応したり、GeForceとかの推奨に入ってないGPUでの情報もそこそこ出てきていたり)があるので、公式サイトのチュートリアルをちょこちょこ寄り道しながらやってみる。
本ページはやりながら調べたこととかをメモしたもの。書いている人はNN初心者の文系プログラマなので、記述には怪しいところがあると思われる。注意されたし。
Python3.4, TensofFlow0.7, OSはUbuntu系を利用。今回はMNIST For ML Beginnersのところをこなす。
@Versions python3.4.0 tensorflow0.7.0, numpy1.10.1
インストール
Tensorflowはpipからインストール可能。
これを書いている時点ではPython2.7及び3.3以上に対応しているらしい。pipでインストールできる一覧を見るとcp34というバージョンがあったのでPython3.4を使う。(後日見たらcp35というバージョンもできていた)
下記はPythonをaltinstallしてpipでCPU版を入れる例。GPU版のインストールについてはこちらを参照。
# 公式サイトからPython-3.4.4を落としてきてaltinstall$ tar xvf Python-3.4.4.tar.xz $ cd Python-3.4.4/$ ./configure$ sudo make altinstall$ sudo make install# pip3.4で;ipythonとtensorflowをインストール$ sudo pip3.4 install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.6.0-cp34-none-linux_x86_64.whl
インストールしたら成功したことを確認。
$ python3.4>>> import tensorflow as tf
エラーがでなければ成功。
CentOSの少し古いバージョンに入れたら上記の段階でGLIBCのバージョン古いから上げろというエラーに遭遇した。
データの読み込みと確認
MNISTの手書き文字認識を行う。MNIST database(Mixed National Institute of Standards and Technology database)は、数字の手書きデータを集めたもの。
下記でMNISTのダウンロードから読み込みまでを実行してくれる。
from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("MNIST_data/", one_hot=True)まずは読み込んだデータがどんなものなのかを確認する。matplotlibを使用。
# trainデータの件数mnist.train.num_examples #=> 55000# testデータの件数mnist.test.num_examples #=> 10000# validationデータの件数mnist.validation.num_examples #=> 5000
合計7万件のデータを保持しているようだ。0〜9の10種類の文字が入っているわけなので、訓練データは1つの数字につき5500件入っていることになる。
次にデータの中身も確認しておく。
# imageの中身を見てみると、ndarrayが入っているmnist.validation.images[0] #=> array([ 0. , 0. , 0. , 0. , 0. , #=> 0. , 0. , 0. , 0. , 0. , #=> 0. , 0. , 0. , 0. , 0. , #=> 0. , 0. , 0. , 0. , 0. , # 以下略 #=> 0. , 0. , 0. , 0. ], dtype=float32)# 784ピクセル(28*28)の情報が入っているらしいmnist.validation.images[0].shape #=> (784,)# ndarrayをgrayscaleの画像として表示from matplotlib import pylab as pltimport matplotlib.cm as cmplt.imshow(mnist.validation.images[0].reshape(28, 28), cmap = cm.Greys_r)

入っていた配列を28*28にreshapeして画像として表示してみると、5っぽい数字が出てきた。
格納されている画像を40枚くらいまとめて表示してみる。
f, axarr = plt.subplots(5, 8)for idx, img in enumerate(mnist.validation.images[0:40]): axarr[int(idx / 8)][idx % 8].imshow(img.reshape(28, 28), cmap = cm.Greys_r)

みんな字汚いね。人の目で見ても若干判別しづらい文字も混じっているのが見て取れる。右下から1つ左の文字ってなに? 子かなにか?
これらの数値にどのようにラベルが貼られているかも確認しておく。
mnist.validation.labels[0:5] #=> array([[ 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], #=> [ 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], #=> [ 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], #=> [ 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], #=> [ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])
1行目は5番目(0origin)に1が、2行目は0番目に1が、3行目は4番目に1が立っている。これは上に表示した画像の数字と一致する。
1 + 2 = 3
処理するデータの内容がわかったところで、チュートリアルを開始する。
しかし文系の私にとってはチュートリアルの内容(Softmax Regressionからスタートする)をこなすのは難しそうなので、とりあえず1 + 2(これならわかる。答えは3だ!)から始めることにする。
備え付けのクラスに値を入れて、Sessionを作り、runする。これがTensorFlowの基本的な処理の実行方法らしい。
1 + 2のような定数の計算をさせる際は、tf.constantというクラスに値を入れるらしい。
import tensorflow as tf# 値を用意x = tf.constant(1)y = tf.constant(2)# 足し算ses = tf.Session()ses.run(x + y) #=> 3
3が出力された。
intではなくarray[int]を入れて足してみる。また加算には + ではなく add を使ってみる。
import tensorflow as tf# 値を用意x = tf.constant([1, 3])y = tf.constant([2, 4])# 足し算product = tf.add(x, y)ses = tf.Session()ses.run(product) #=> array([3, 7], dtype=int32)
arrayでも足し算ができた。
y = x * w
だいたいフローはわかったけどチュートリアルのコードをやるのはまだ早い気がする。
もう少し簡単な、シンプルな回帰(y = x * wくらいなら俺にもわかる!)をしてみる。
今回の画像を読み込んで単純な回帰分析を行い、予測モデルを生成してみる。
import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("MNIST_data/", one_hot=True)# 画像データを入れる用のplaceholder# 784は画像のピクセルの数x = tf.placeholder(tf.float32, [None, 784])# 正解データを入れる用のplaceholdery = tf.placeholder(tf.float32, [None, 10])# weightを用意# 各ピクセルに対する0〜9までの数字に対するweightを入れるという意味で、784*10個用意w = tf.Variable(tf.zeros([784, 10]))# 式(x * w)f = tf.matmul(x, w)# テキトーなloss functionのようなナニカloss = tf.reduce_sum(tf.abs(y - f) * 0.1)# 一番よく見かけるGradientDescentOptimizer(最急降下法)を使うopt = tf.train.GradientDescentOptimizer(0.01).minimize(loss)# valiableの初期化sess = tf.Session()sess.run(tf.initialize_all_variables)# 学習開始sess.run(opt, feed_dict={x: mnist.train.images, y: mnist.train.labels})# 結果weights = sess.run(w)# 算出されたweightを描画してみるf, axarr = plt.subplots(2, 5)for idx in range(10): ax = axarr[int(idx / 5)][idx % 5] ax.imshow(weights[:, idx].reshape(28, 28), cmap = cm.Greys_r) ax.set_title(str(idx)) ax.axes.get_xaxis().set_visible(False) ax.axes.get_yaxis().set_visible(False)出来上がったWeightを画像にすると、なんかそれっぽい結果が出てきた。

Placeholderと呼ばれるものに入力に対応するshapeを設定しておき、weightやbiasなどの出したい項目をVariableとして設定しておき、あとはmatmulなりgradient descentなり必要な計算処理を記述して渡せば、それっぽい結果を返してくれるようだ。
上では全件で学習しているけど、例えば100件だけで学習すると下記のようになる。
sess.run(opt, feed_dict={x: mnist.train.images[0:100], y: mnist.train.labels[0:100]})
数が少ないので元の手書き文字が透けて見える。
正答率の確認
上記のモデルを使って予測した場合の正答率を見てみる。やり方がやり方なので70%も出ればいい方だろうか。
# ラベルの値とモデルの評価# yがラベル(argmaxで1が立っているものが取れる)# fでモデルを適用した結果を返す(最大のものが取れる)# argmaxの2つ目の引数はdimensioncorrect_prediction = tf.equal(tf.argmax(y,1), tf.argmax(f,1))# 正解/不正解がbooleanで返るcorrects = sess.run(correct_prediction, feed_dict={x: mnist.test.images, y: mnist.test.labels})corrects #=> array([ True, True, True, ..., False, False, True], dtype=bool)# 正解率を出すcorrects.mean() #=> 0.6704tf.equalでラベルとモデルによる予測処理を比較し、正しかった割合を出している。
結果は67%。まあ、こんなもんでしょうという数字。
確認の為、合っている画像と間違っている画像をちまちま表示してみる。
まずは合っている画像から。
# correctsがTrueの画像だけ前方から40件抽出して表示f, axarr = plt.subplots(5, 8)for idx, img in enumerate(mnist.test.images[corrects][0:40]): axarr[int(idx / 8)][idx % 8].imshow(img.reshape(28, 28), cmap = cm.Greys_r)
5が見当たらないけど偶然だろうか。

数字毎の正答率を見てみる。
for i in range(10): positive = sum(mnist.test.labels[corrects][:, i] == 1) all = sum(mnist.test.labels[:, i] == 1) print(i, positive / all)
0 0.9867346938781 0.7603524229072 0.689922480623 0.8316831683174 0.3849287169045 0.06 0.7515657620047 0.7344357976658 0.8223819301859 0.662041625372
5がなんと0%。4も38%と良くない。逆に0は98%以上のかなり良い数字になっている。
次に不正解の画像。
f, axarr = plt.subplots(5, 8)for idx, img in enumerate(mnist.test.images[~ corrects][0:40]): axarr[int(idx / 8)][idx % 8].imshow(img.reshape(28, 28), cmap = cm.Greys_r)

死亡した5を除くと、人の目で見ても読みづらい文字がけっこう含まれている。特に右上なんて数字とわかってるから4と判別できるけど、数字以外も含んだら判別できなさそう。
これはこれで文字の綺麗さ判定とかに使えそうな気がした。
チュートリアルのコードを動かす
いくつかの段階を踏んで、そろそろチュートリアルのコードを理解できそうな気がしてきたので、そろそろ当該コードを動かしてみる。
import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_data# データ読み込みmnist = input_data.read_data_sets("MNIST_data/", one_hot=True)# placeholder用意x = tf.placeholder(tf.float32, [None, 784])y_ = tf.placeholder(tf.float32, [None, 10])# weightとbias# さっきの例ではw * xだったけど、今回はw * x + bW = tf.Variable(tf.zeros([784, 10]))b = tf.Variable(tf.zeros([10]))# Softmax Regressionを使うy = tf.nn.softmax(tf.matmul(x, W) + b)# 交差エントロピーcross_entropy = -tf.reduce_sum(y_ * tf.log(y))# 先ほど使ったGradientDescentOptimizerで、今回はcross_entropyを利用train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)# 初期化init = tf.initialize_all_variables()sess = tf.Session()sess.run(init)# 学習for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})# テストデータで予測correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}) #=> 0.91839999tf.nn.softmaxを使っていたり、cross_entropyのところの式が変わっているけど、基本、やっていることはさっきのコードと変わりはない。ちゃんと書かれたコードだけあって、正答率は91.8%とそこそこの値になっている。
weightとbiasの値を確認してみる。
まずはbias。
sess.run(b) #=> array([-0.60608989, 0.37535664, 0.22243324, -0.32445797, -0.02885269, #=> 1.98688066, -0.19526966, 0.94287419, -2.00994039, -0.36292851], dtype=float32)
5のbiasが1.98と大きくなっている。5は判別されづらいのだろうか。
次にweight。
weights = sess.run(W)f, axarr = plt.subplots(2, 5)for idx in range(10): ax = axarr[int(idx / 5)][idx % 5] ax.imshow(weights[:, idx].reshape(28, 28), cmap = cm.Greys_r) ax.set_title(str(idx)) ax.axes.get_xaxis().set_visible(False) ax.axes.get_yaxis().set_visible(False)
じっと見ると言わんとすることはわからなくもないみたいな感じ。
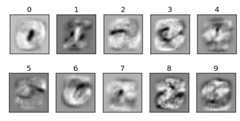
各数字ごとの正答率も見ておく。
corrects = sess.run(correct_prediction, feed_dict={x: mnist.test.images, y_: mnist.test.labels})for i in range(10): positive = sum(mnist.test.labels[corrects][:, i] == 1) all = sum(mnist.test.labels[:, i] == 1) print(i, positive / all) #=> 0 0.979591836735 #=> 1 0.985022026432 #=> 2 0.924418604651 #=> 3 0.877227722772 #=> 4 0.913441955193 #=> 5 0.841928251121 #=> 6 0.959290187891 #=> 7 0.913424124514 #=> 8 0.887063655031 #=> 9 0.9068384539153, 5, 8あたりが80%台。0と1は97%を超える高い正答率になっている。
不正解になったのはどんな文字か確認する。
f, axarr = plt.subplots(5, 8)for idx, img in enumerate(mnist.test.images[~ corrects][0:40]): axarr[int(idx / 8)][idx % 8].imshow(img.reshape(28, 28), cmap = cm.Greys_r)

判定がうまくいってない3, 5, 8は普通に読める文字が多いが、それ以外の文字は人が見ても悩むような字も含まれている。
一番上の左から4番目。これは1か? それとも7か?
一番下の右から3番目。これはどう見てもyなんだけど、4のなのか?
まとめ
TensorFlowのチュートリアルの最初の一歩的なところが実行できた。
適切なPlaceholder, Variableを用意して、あとは式をSessionでrunすれば動くという流れで、慣れるまでは少し違和感があったが、それなりに使いやすい印象を受けた。