
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く

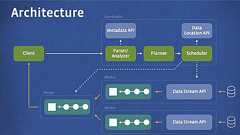
Facebookは、数ペタバイト級の大規模データに対しても、対話的にアドホックな問い合わせを可能にする分散SQLエンジン「Presto」を、オープンソースで公開しました。 PrestoはFacebook社内で大規模データの分析のために開発され、すでに同社社内使われているもの。 FacebookはPrestoを開発した背景として、大量のデータをHadoop/HDFSベースで保存したものの、バッチ指向のMapReduceではなく、リアルタイム性に優れた処理が必要になったためだと、次のように説明しています。 Facebook’s warehouse data is stored in a few large Hadoop/HDFS-based clusters. HadoopMapReduce [2] and Hive are designed for large-scale, reliabl
■ インデックスとは データベースの世界で、インデックス(索引)とはテーブルに格納されているデータを 高速に取り出す為の仕組みを意味します。 インデックスを適切に使用することによってSQL文の応答時間が劇的に改善 される可能性があります。 インデックスにはB-Treeインデックスをはじめ、ビットマップインデックス、 関数インデックスなどの種類がありますが、ここでは最も一般的に使われ、かつ ほとんどのDBMSでサポートされているB-Treeインデックスについて解説します。 ※CREATE INDEX文でオプションを指定しない場合は通常B-Treeインデックスが 作成されます。 ■ B-Treeインデックスのしくみ B-Tree(Balanced Tree)インデックスは次のようなツリー状の構造になっています。 ツリーの先頭はヘッダブロックと呼ばれています。ヘッダブロックでは、キー値の 範囲
SQLとNoSQLではどちらが優れているのか?グーグルの担当者がディベート(というより小芝居:-)を行ったセッション「Google I/O 2012 -SQL vs NoSQL: Battle of the Backends - YouTube」が公開されています。 (この記事は「SQL vs NoSQL、グーグルにおける戦い(前編)。Google I/O 2012」の続きです) スケーラビリティについて (NoSQL担当)あらゆる面で、こちらが高いスケーラビリティを提供している。 (SQL担当)そんな訳ないだろ。 (NoSQL担当)そんな訳あるさ。 (SQL担当)じゃあまず、CloudSQLがどう使われているか紹介しよう。例えば「グーグルorgチャート」。グーグルの3万人の従業員について、組織内のつながりや仕事を示すアプリケーションだ。 社内では誰もがこのWebサイトを開いていて、


SQLとNoSQLではどちらが優れているのか?グーグルの担当者がディベート(というより小芝居:-)を行ったセッション「Google I/O 2012 -SQL vs NoSQL: Battle of the Backends - YouTube」が公開されています。 このセッションは、先々週開催されたGoogle I/O 2012で行われたもの。SQLとNoSQLには機能的にどのような違いがあり、どう使い分けるべきなのか、明確な説明が参考になります。 ハイライトを紹介しましょう。 クラウドにおけるデータベースのメリットグーグルのAlfred Fuller氏(NoSQL担当)。 クラウドはフォルトトレラントでメンテナンス不要、パッチも私たちが適用しており、利用者は運用について心配する必要がない、といったメリットがある。 データのレプリケーションや地域分散でデータも保全され、インターネッ
eBayが、JavaScriptアプリケーションからSQL文のような形式でデータベースへの問い合わせを記述できるDSL(ドメイン固有言語)のql.ioを発表。オープンソースとして公開しました。 現在、多くのWebアプリケーションが、バックエンドとのデータのやりとりにHTTPをベースにしたAPIを用いています。しかし、WebベースのAPIによってデータを取り出すのは、プログラマにとって実は手間のかかることです。 例えば、キーワードを入力すると関連する商品の名前、詳細、購入者の評価をユーザーに表示する、というWebアプリケーションでは、まずキーワードでデータベースを検索して商品IDを取得し、今度はその商品IDをキーにして名前や概要、評価の情報を取得する、といったように、APIを繰り返し呼び出す必要があります。 ql.ioはこうした内容をSQLのように分かりやすい記述で実現するだけでなく、複数の
この連載もついに最終回となりました。今までの連載で紹介したテクニックを使えば、ほとんどのデータウェアハウスは大幅に高速になるはずですが、統計情報の取得方法に問題があって想定どおりに動いていなかったら元も子もありません。「SQLが遅い」という理由の一つに「実行計画が悪い」ということがありますが、オプティマイザは統計情報を基にして実行計画を作ります。なので、正しくない統計情報を使っていると正しくない実行計画が作られてしまい、その結果、SQLが遅いという結果になってしまいます。ある程度のコストが掛かる統計情報収集はデータの変更とリアルタイムで行われるわけではないので、統計情報を収集するタイミングや方法によっては現在のデータの実態を反映していない、正しくない統計情報になってしまいます。そこで今回は正しい統計情報の取り方と、その統計情報で正しい実行計画が作られたかどうかの監視の仕方についてご紹介しま
Hello, I’m Kristof, a human being like you, and an easy to work with, friendly guy. I've been a programmer, a consultant, CIO in startups, head of software development ingovernment, and built two software companies. Some days I’m codingGolang in the guts of a system and other days I'm wearing a suit to help clients with their DevOps practices. WhileSQLdatabases are insanely useful tools, their
The document containslog data from user activities on a platform. There are three columns - user_id, event, and event_date.Itlogs the activities of 5 users over several days, including events likelogins, posts, comments, views.It also includes some aggregated data on unique events and totals by user.

MySQL の勉強をせずにフレームワーク等でSQL を書かずに Web サイトを構築していました。データ数も2万件程度でしたので、そこまで困ることはありませんでしたが、今回100万弱の商品データを扱う機会ができたので、MySQL のチューニングや発行するSQL について見直す機会がありました。 この記事ではMySQL を高速化するのに行った対策など勉強したものを自分用にメモしておきました。 条件式で比較するカラムにインデックスを使用して高速化 商品コードで存在しない商品を見つけて、商品をDBに登録するという処理を行っている場合、4万件超えたころから処理に2秒以上かかるようになってきます。12万件超えた頃には10秒程度かかるようになってしまいましたが、商品コードのフィールドに対してカラムインデックスを貼ることで0.2秒に短縮することができました。MySQL のリファレンスにも以下のよ
Web時代に生成される大量のデータを、トランザクションを維持しつつ処理できる新しい種類のデータベース「NewSQL」が求められていると、データベース研究者の大御所、マイケル・ストーンブレイカー氏が米計算機学会ACM(Association for ComputingMachinery)のコラム「NewSQL: An Alternative to NoSQL and OldSQL for New OLTP Apps」(NewSQL:New OLTPアプリケーションのための、NoSQLやOldSQLに替わるデータベース)で書いています。 NewSQL: An Alternative to NoSQL and OldSQL for New OLTP Apps |blog@CACM | Communications of the ACM これまで企業の情報システムの定番は、受発注
SQLのプログラミングは奥が深い。特にパフォーマンスの観点から、そう言えるだろう。 みなさんご承知の通り、同じ結果を出すプログラムでも、SQLの書き方次第で処理時間に何倍もの差が生じ得る。効率の悪いSQLを書いてしまう原因は、多くの場合、リレーショナルデータベースの内部動作やアプリケーションに関する理解不足である。両者をよく知った上で最適なSQLを書けるようになることは、システムエンジニアとしての重要なスキルの一つである。 特集『基礎から理解するデータベースのしくみ』では、リレーショナルデータベースの内部動作について、基本的な部分を分かりやすく解説している。SQLプログラミングに役立つことはもちろん、SQLチューニングやデータベース設計のための基礎知識としても不可欠だ。 イントロダクション ブラックボックスのままでいいの? Part 1:SQL文はどのように実行されるのかSQL実行までの

I tweeted aboutORM last week, and since then several people have asked me to clarify what I meant. I have actually previously written aboutORM, butit was in the context of a larger discussion aboutSQL and I shouldn't have confused the two issues. So here I'mgoing to focus onORMitself. I'm alsogoing to try to be very brief, sinceit became very apparent from mySQL article that people tend
 1
1リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く



