
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
※この投稿は米国時間 2021 年 5 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。 2021 年用に更新: この投稿には、Google のホワイトペーパー「パスワード管理のベスト プラクティス」のユーザー向けとシステム設計者向けの両方の最新情報を含む、更新されたベスト プラクティスが含まれています。 アカウント管理、認証、パスワード管理には十分な注意を払う必要があります。多くの場合、アカウント管理は開発者や製品マネージャーにとって最優先事項ではなく、盲点になりがちです。そのため、ユーザーが期待するデータ セキュリティやユーザー エクスペリエンスを提供できていないケースがよくあります。 幸い、Google Cloud には、ユーザー アカウント(ここでは、システムに対して認証を受けるすべてのユーザー、つまりお客様または内部ユーザー)の作成、安全な取り扱い、

𓁲 𓀀 𓀁 𓀂 𓀃 𓀄 𓀅 𓀆 𓀇 𓀈 𓀉 𓀊 𓀋 𓀌 𓀍 𓀎 𓀏 𓀐 𓀑 𓀒 𓀓 𓀔 𓀕 𓀖 𓀗 𓀘 𓀙 𓀚 𓀛 𓀜 𓀝 𓀞 𓀟 𓀠 𓀡 𓀢 𓀣 𓀤 𓀥 𓀦 𓀧 𓀨 𓀩 𓀪 𓀫 𓀬 𓀭 𓀮 𓀯 𓀰 𓀱 𓀲 𓀳 𓀴 𓀵 𓀶 𓀷 𓀸 𓀹 𓀺 𓀻 𓀼 𓀽 𓀾 𓀿 𓁀 𓁁 𓁂 𓁃 𓁄 𓁅 𓁆 𓁇 𓁈 𓁉 𓁊 𓁋 𓁌 𓁍 𓁎 𓁏 𓁐 𓁑 𓁒 𓁓 𓁔 𓁕 𓁖 𓁗 𓁘 𓁙 𓁚 𓁛 𓁜 𓁝 𓁞 𓁟 𓁠 𓁡 𓁢 𓁣 𓁤 𓁥 𓁦 𓁧 𓁨 𓁩 𓁪 𓁫 𓁬 𓁭 𓁮 𓁯 𓁰 𓁱 𓁳 𓁴 𓁵 𓁶 𓁷 𓁸 𓁹 𓁺 𓁻 𓁼 𓁽 𓁾 𓁿 𓂀 𓂁 𓂂 𓂃 𓂄

2023.05.10 官報に使われる「官報文字」というものがあります。 そこには渡辺さんの「辺」の異体字が140文字も登録されています。 日本語の常用漢字には2136文字ありますが、そこには邉や邊などは入っていません。 そこでJISの第四水準までを含むJIS X 0213という標準を定め、スマホやパソコンではここまでを標準的に表示できるようにしています。 ところが我が国の戸籍で使ってもよいとされている文字はそれを遙かに超えていて、少なくとも55,270文字もあります。 全ての国民の氏名をコンピュータで扱えるようになることを目指して、戸籍統一文字や住基ネット用の統一文字を網羅した「文字情報基盤」を2011年に策定し、それにあわせたフォントを作成し、無償で提供しています。 この「文字情報基盤」(MJ)には、58,862文字が含まれています。 しかし、このMJを全庁的に採用している自治体は、川口

A static site to link people to when their code is displaying Japanese wrong. View the Project on GitHub heistak/your-code-displays-japanese-wrong Why am I here? If someone gave you a link to this page, that person probably thinks your code displays Japanese wrong. In short, from a native Japanese eye, yѳur ҭєxҭ lѳѳκs κιnd ѳf lικє ҭЋιs. This page will give you a brief description of the glyph appe
Googleは独自のルールに従って検索結果の表示順位を決めていますが、Googleの広告枠を購入すれば任意のウェブサイトを検索結果の最上部に表示することができます。この広告枠を悪用して人気画像処理ソフト「GIMP」の公式サイトになりすました偽サイトが検索結果の最上部に表示されてしまう事態が発生しました。偽サイトはドメインの見た目までソックリで、インターネットに慣れている人でも見分けることは困難となっています。 Dangerous Google Ad Disguising Itself as www.gimp.org : GIMP https://www.reddit.com/r/GIMP/comments/ygbr4o/dangerous_google_ad_disguising_itself_as/ Dangerous Google Ad Disguising Itself as www
usagimaru ⌘ @usagimaruma 日本人が想像するよりかなり広い範囲で日本語文字が中華フォント化している現象。CJK処理系における日本語の扱いに対する問題としてそろそろ何とかしていかないと、ソフトウェアの中の日本語が死んでいく危機感がある。そもそもなんでChineseに分類されるフォントにフォールバックされるのかって。 2022-09-28 16:03:32 usagimaru ⌘ @usagimaruma 前も調べたけど、言語環境の言語優先度設定で“わざわざ”日本語を優先言語にしておかないと、日本語の文字の多くは簡体中国語の奇妙なフォントで描画される。バグではなく仕様。わざわざ日本語を優先している民族なんて日本人しかいないから、世界のほとんどはきっと中華フォントで日本語を眺めている。 2022-09-28 16:07:52

英文におけるエムダッシュ「—」と、エンダッシュ「–」と、ハイフン「-」の用法について、辞典の出版社であるMerriam-Websterがまとめました。 How to Use Em Dashes (—), En Dashes (–) , and Hyphens (-) | Merriam-Webster https://www.merriam-webster.com/grammar/em-dash-en-dash-how-to-use ◆エムダッシュ エムダッシュはカンマやコロン、あるいは括弧のように機能し、例や説明、補足事項などの区切りに使われます。 ・文の構造の突然の変化や中断を示すのに使われるケース Mabel the Cat was delighted with the assortment of pastries the new bakery featured, but Harry

最近知ったんですが、Windowsではキーボードから円記号(¥)の入力はできないらしい。 というのも キーボード右上の¥キー キーボード右下の\キー のどちらかを押せば円記号(¥)を入力できますが、どちらを押しても入力されるのは円記号(¥)に偽装されたバックスラッシュ記号(\ )らしい。 皆さんこれ知ってました? いや正直、これを聞いても「何言ってんだコイツ」って思う人が大半だと思いますし、私も今でもそう思います。 これは「バックスラッシュと円記号問題」などと言って、Windowsで昔から続く”呪い”のようなものらしいのですが この”呪い”を理解するには文字コードの歴史を知る必要があります。 文字コードとは? その前に、そもそも文字コードってなによ?という根本的な話からすると、文字コードは「パソコンに文字を覚えさせるための暗記表」みたいなものです。 パソコンは2進数しか理解できないので あ
はじめにこちらはmhidakaが建立したAdvent Calendar Day.3となります。 こんにちは、はじめまして、のなと申します。mhidakaさんのTweetを見つけて、初めてAdvent Calendarなるものを書いています。なにかお作法間違っていたら大目に見てください、よろしくお願いします。 軽く自己紹介をさせていただくと、普段はGoogleでAndroidのTextまわりの開発を行っており、DroidKaigiやShibuya APKで発表させていただいたりしています。最近はほぼ絵文字の話しかしてないので、絵文字おじさんと思われてそうですが、普段の仕事は絵文字に限らず、Androidの文字表示の部分は大抵面倒をみています。 今回この機会をいただいたので、どんな内容を書こうか迷ったのですが、やはり皆が読んで面白い内容というと、絵文字になるのかなぁ、ということで性懲りもなく絵

先日は住所の件でお楽しみでしたね。 私も楽しくなってしょうもないツイートをしたところ、@masanorkさんから有用な情報をいただいてしまいました。 異体字に加えて外字も根深いですし、日付型に収まらない住基の生年月日とか、屋号を含んだ個人事業主の口座名義とか、外国人氏名における住民登録のアルファベットと口座名義のカタカナとの解離とか、旧姓併記の例外処理とか、文字列型に刻まれたバッドノウハウの塊ですね https://t.co/GOaytijfst — Masanori Kusunoki / 楠 正憲 (@masanork) June 6, 2023 このとき、私はごく簡単な「名寄せの難しさ」の社内研修資料を作っている最中だったのですが、この情報が大変参考になりました。 一方、私だけが得をしているのがなんとなくムズムズしてきたので、ここにアウトプットしてスッキリしようと思います。 なお、住所

2003年には「プレーンテキストなんてものは全く存在しない」と言われ、テキストの解読には文字コードの情報が必須となっていました。しかし、2023年になるまでの20年の間に絵文字などのおかげでUnicodeの利用率は98%へと到達し、再び文字コードを気にせずにすむ時代がやってきています。そんな時代において、正しくUnicodeを使うために必要な知識をエンジニアのニキータ・プロコポフさんが解説しています。 The Absolute Minimum Every Software Developer Must Know About Unicode in 2023 (Still No Excuses!) @ tonsky.me https://tonsky.me/blog/unicode/ Unicodeの歴史と利用率の推移をまとめたグラフは下図の通り。2000年代後半から急速に普及が進んでいったこ

Original article:https://dev.to/dotnetsafer/rip-copy-and-paste-from-stackoverflow-trojan-source-solution-4p8f その昔コピペできない文章というものがありました。 実際は単にフォントを変えているだけというものですが、人間の目に見える文字と実際の文字が異なることを利用した攻撃の一種と見ることもできます。 さて、最近になって似たような攻撃に関する論文が公開されました。 人間には見えない文字を織り交ぜることによって、一見問題ないコードが実は脆弱になってしまうというものです。 ただ論文は堅苦しいうえに長くて読むのがつらいので、具体的に何がどうなのかよくわかりません。 平易に解説している記事があったので紹介してみます。 以下はDotnetsafer( Twitter / GitHub / Web

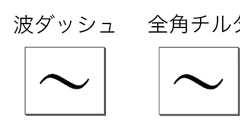
どうも、『人文×社会』の中の人です。 今回は、WindowsとMacで起こった「波ダッシュ」をめぐるドタバタ劇をご紹介したいと思います。 波ダッシュといえば、「〜」という記号。どこにもドタバタする要素がないように思えますが、実は今でも組版業界で問題となっている大混乱があります。 波ダッシュと全角チルダ「それ、不等号ですよ! 紛らわしい約物3連発!」の記事でもご紹介したように、見た目が「〜」に見える約物には、2種類あります。 「波ダッシュ」と「全角チルダ」です。 「波ダッシュ」は、日本語で範囲を表すときに使われる約物です。「明治〜大正」みたいな感じで使います。 「全角チルダ」は、半角チルダ(~)の全角版です。チルダは「漸近的に等しい」ことを表す数学記号として使われます。つまり、全角イコール(=)の仲間です。(他にも半角チルダは、コンピュータ上のホームディレクトリを表したり、プログラミング言語
かつてWindowsでテキストファイルといえばシフトJIS形式のものが大半だった。しかし最近では、UTF-8形式のテキストファイルも普通に見かけるようになってきた。世の中はUTF-8が主流になりつつあると言っていいだろう。 しかし、WindowsでUTF-8を使うと、ちょっと困ったことがある。それは、エクスプローラーの検索欄などで用いるWindows Searchが、UTF-8にはしっかり対応していないのである。正確に言うと、Windows Searchはファイル先頭に「BOM」のあるUTF-8は認識して正確にインデックス化し、ファイルの全文検索が可能になるが、BOMのないUTF-8では正しくインデックス化できず、ファイルの全文検索はASCIIコードのみ可能で、日本語などの非ASCII文字では全文検索ができない。 同じ内容のテキストをUTF-8、UTF-8 BOM付き、UTF-16ビッグエ

Deleted articles cannot be recovered. Draft of this article would be also deleted. Are you sure you want to delete this article? Webサービスのフォームに住所を入力するとき、丁目や番地などを入れる欄について、数字やハイフンを全角で書かなければいけない「全角縛り」をやっているフォームをよく見ます。半角文字を入力してしまってエラーになったり、咄嗟に変換方法を思い出せなかったり、全角と半角の見分けが付きづらかったり、「全角縛り」であることが明示されていなかったり、「ハイフン」としてどの文字を使うべきかわからなかったり……と、鬱陶しさを感じることが多くあります。 「住所は全角のみ」(数字やハイフンも絶対に半角を受け付けない)という仕様がどういう経緯で生まれて、どう広まっ

パトリック・ミッケンジー(Patrick McKenzie)さんのブログ・エントリ、 “Falsehoods Programmers Believe About Names” の日本語訳です。翻訳の公開を快諾してくださったミッケンジーさんに感謝します。 公開: 2012-02-22 Posted on June 17, 2010 by Patrick きょう、ジョン・グレアム゠カミング(John Graham-Cumming)が、正しくない文字が含まれているといって彼のラスト・ネームを受け付けないコンピュータ・システムへの不満の記事を書いていた。もちろん彼の名前に「正しくない」ところなどない。当人の申し出たものが当人を識別するものとしては相応しいのであって、定義からして名前とはそういうものである。このことにジョンは当然ながらいらだったし、そうなるのもきわめて正当なことだ。定義からすれば事実
TL;DR Shift_JISにしただけでコンパイラが通らなくなる恐ろしい事件とその回避法について。 \ (¥)のASCIIコードは0x5c 表、能は良くない UTF-8は神 2023/12/06追記 誤りがあったので訂正します。こんな読まれると思ってなかったので正直ちょっとびっくりしていますが、いろいろコメントありがとうございました。(ツイート等全て拝見しました。) Shift_JISが悪いわけではない(デフォルトのエンコーディング設定の問題)→追記しました UTF-8にはUTF-FSSという仕様でこの問題が回避されている→マジでタメになる知識ありがとうございます OSによってデフォルトのエンコーディング設定が異なるせいで、デフォルト環境での動作がOSにより異なる→なるほど?(調査中) CRLFとLF問題では→なるほど?(調査中) そんな問題何を今更→UTF-8が出てから生まれたからです

欧文のルール日本人は知らない欧文(主に英語)のルールというものがあります。これは英語の授業でも教えてくれません。それゆえか翻訳者からの原稿にも、このルールに則っていないものがすごく多くあります。 知っておくと何かとアドバンテージになるので少しずつご紹介していきます。ご紹介した欧文のルールはこちらのマガジンにストックしていきます。 欧文で「〜」は使わない考えてみると「そりゃそうか」ってなるのがこの「〜」。日本だと 午前10時〜午後7時 というように使用します。便利でわかりやすい符号です。 「〜」は波形という日本の約物これは「波形」というつなぎ符号です。約物(やくもの)という記号の一種。波形の意味は、「…まで」。だから 東京〜大阪まで という表記は間違いです。「東京〜大阪」で「東京から大阪まで」という意味になるからです。波形は、この他に語句の省略や長音を強調するために使う音引き「ー」の代わりに

2022年12月1日、Discordはカスタマイズされたオリジナルのフォント「gg sans」を導入しました。ggは"Good Game"に由来するようです。Web フォントなどを利用して Discord 上の表示がこのフォントに順次切り替わる予定です。 補足 / UPDATE 2022/12/03 14:37 JST DiscordのCEO(Jason氏)より返事があり、ツとノの字形がgg sansから削除されたとのことです。右括弧は現時点で残っているようです(これは当初のわたしの指摘がツとノのみに限られていたせいです)。 2022/12/04 14:55 JST 12/3時点でJason氏からの返信に右括弧が残っているという旨を補足しました。 12/4 午前にDiscordのエンジニア Brandon氏より連絡があり、括弧等の修正が完了したとのことです。 こちらで確認する限り、CJK関

ChatGPTが「視覴」という新語を発明したらしいことをフガクラさんのツイート(2023-06-08 08:51:02 JST)で知る。 すでに「視覴」は、いくつかの最近書かれたWebページで使われていた。ChatGPTで生成されたページらしい。ざっと検索して見つけたページを列挙しておく。いずれも最近作られたか修正されたページである(1件だけ2020年のページがあるが、最近修正されたものかどうか不明)。 映像・音声編集におけるノーマライズの重要性!(2023-05-11)「視覴的・聴覚的な一貫性」「視覴的な効果を最大化」「視覴的な混乱を避け」(2回)なお、このページは現在消えて視覴とは?AI(ChatGPT)が出力した新しい言葉なのか?(2023-06-08)にリダイレクトされ、「弊社では、2023年3月より用語集作成に際しAIライティングの試験運用を行っておりますが、この度、「視覚」の誤
法務省が、戸籍で取り扱う文字を整理した「戸籍統一文字」を検索できるウェブサイト「戸籍統一文字情報」で、漢字を検索すると、みたことのない漢字がゾロゾロでてきて、たいへんおもしろい。 当サイトでは、昨年動画で取り上げたうえに、記事化までしていじり倒してきた。 この、みたことのない漢字をいじっておもしろがるのは、それはそれでいいけれど、やはり「なんでこんな漢字があるのか」という、素朴な疑問も当然わく。 そこで、漢字に詳しいひとと一緒に、戸籍統一文字にある不思議な文字を一緒にみてもらうことにした。 「戸籍統一文字」とは? 日本語を話す日本人が普段使うとされている漢字は、常用漢字としてまとめられており、その数は現在2136文字ある。 そのほか、めったに見かけないけれど、読んだり書いたりできる漢字。読み方もわからないけれど、どこかで使われている漢字をあわせて、かなり多めに見積もっても、おそらく3000

こんにちは。徒然なるままにTweetを眺めていたら、Tanakaさんがこのようなことを呟いていました。 そういやRustのStringにreverseメソッドないなと思ったけど、まあよく考えたらUTF-8で文字逆転させるとか地獄のような話になるしそもそも長さが変わるケースとかあったりしそうで怖いわな・・・(´・_・`) — Hideyuki Tanaka (@tanakh) May 1, 2021 背景等はよくわからないですが、文字列の反転というのは確かに難しい問題ですし、どう難しいのかというのを、ちょっと真面目に考えて解説してみました。というノートです。 本文での表記についてこれから文字とそのバイト表現の話をしていきます。文字のエンコードの方式で同じ数値でも色々意味が分かれてしまいますので、本文では以下のように表記することにします。 Unicodeコードポイント(以下、単にコードポイント

関連記事 25人のAIが一緒に暮らしたら、自我は芽生えるか? ゲームの中で検証 バレンタインなど勝手に企画 米スタンフォード大学とGoogle Researchに所属する研究者らは、ChatGPTなどで制御したキャラクター25人が1つの町で一緒に生活したらどうなるかを検証した研究報告を発表した。 「サーバに致命的な不具合」のスマホゲー、「修正不可能と判断」でそのままサービス終了 問題発生から2日で ゲームの開発・運営を手掛けるインゲームは、スマートフォンゲーム「戦策三国志」(iOS/Android)の不具合を修正できず、サービスの提供を終了したと発表した。 任天堂「ご迷惑をおかけし申し訳ございません」 「ポケモンSV」アップデート配信 SNSではバグ報告の声多数 任天堂とポケモン社が、「ポケットモンスター スカーレット・バイオレット」の更新データを配信する。新機能を追加した他、いくつかのバ

何を言っているんだと思われるかもしれないですが、気軽にパスワードの1文字目に「~」を使わないほうがいいというお話です。 起こった問題 踏み台サーバー経由でサーバーAに接続して作業をしていた時の話です。 いわゆる多段 ssh 接続というもので、リモートワークになってからは結構使われる方も多いかと思います。 サーバーA上で root 権限になろうと sudo su - してパスワードを入力したら Connection to xxx.xxx.yyy.zzz closed. の文字とともにサーバーAから追い出されてしまいました。 なにかの間違いだろうと何度か挑戦していたのですが、結果はサーバーAから切断され踏み台サーバーに戻る羽目に。。。 そのときに入力していたパスワードが ~.xxxxxxxxxx のような ~ から始まるものでした。 調査 ~ って何か意味があったよなーと思ってどう調べようかと

美乳テーブルとは 「美乳テーブル」という物がある。 「EUC-JP の文章を Shift_JIS だと誤認識されない様に、EUC-JP 固有のバイト値を文章先頭付近に埋め込んでおく」という物。 具体的に、Shift_JIS には 0xFD と 0xFE が現れず、EUC-JP にはそれが現れるので、その値を含む文字コードを書いておこうという事で、その文字の集合に付いた名前。 “美” = 0xC8FE、“乳” = 0xC6FD。 各文字エンコーディングの事情 但し、これは EUC-JP での話。 一応、文章の先頭付近に日本語の文字を書いておくのは、他の文字エンコーディングでも認識のヒントにはなるけど。 逆に「Shift_JIS の文章を EUC-JP だと誤認識されない様にする」には、EUC-JP にはないバイト値の 0x80〜0xA0 を書けばいいんだろうけど、これは沢山ありそうだから、慎
NTT Tech Conferenceは、NTTグループのエンジニアたちが一堂に会し、NTTグループ内外のエンジニアたちと技術交流を行うためのカンファレンスです。ここで、細田氏が「PDFのコピペが文字化けするのはなぜか?〜CID/GIDと原ノ味フォント〜」をテーマに話します。まずは文字化けが起こってしまう原因について。 原ノ味フォントの作成者 細田真道氏(以下、細田):細田です。ふだんはNTTグループのどこかでDXな仕事をしていますが、今日はぜんぜん仕事とは関係なく、個人的にやっているオープンソースなどの話をしたいと思います。よろしくお願いします。 簡単に自己紹介をします。楽譜を作成するプログラム「LilyPond」のコミッターと、GNUの公式文書フォーマット「Texinfo」のコミッターをしています。あとで話しますが、「原ノ味フォント」を作っていて、すごく似たような名前で「原ノ町」という

はじめに Windows ではディレクトリ区切りに Unix 系 OS の / ではなくバックスラッシュ ⧵ を使い、しかも 日本語フォントでは 円マーク ¥ で表示されます。なぜこうなったかは次の独立した 2 つの理由からです。 はるか昔に JIS の文字コードの標準規格はあまり使わない ⧵ を必須の ¥ に置き換えた はるか昔にコマンドのオプション(スイッチ)としてすでに / を使っていた Microsoft は他の OS のやり方を真似するのが嫌だからとか権利侵害になりそうだから ⧵ に変更したなどという根も葉もない噂がありますが、そうではありません。むしろ Microsoft は他の OS のやり方を取り込んだんです。なお、後で解説しますが、Windows は昔からディレクトリ区切りに/ と ⧵ の両方を使えるので Unix 系 OS と互換性がないわけではありません(どっちかと言

この記事は 2024 TSG Advent Calendar 3日目の記事です。昨日の記事は @__dAi00 さんの記事 AivisSpeechを使ったDiscordボットの作成 ①AivisSpeechをGoogle Cloud Runにデプロイする でした。12/5 公開予定の続編も楽しみです。 今回は、初日に公開した以下の記事の副産物です。 import unicodedata # Python 3.12 まで 1000000000000.0 # Python 3.13 から 1000000.0 print(unicodedata.numeric("兆")) 大変だ。Python 3.13 から「5000 兆円」が 50 億円になってしまう(?) unicodedata.numeric メソッドと Unicode 例によって Unicode が関係してきます。前編でも触れたとおり、
海外旅行とピクニック、あとビールが好き。なで肩が過ぎるので、サラリーマンのくせに側頭部と肩で受話器をホールドするやつができない。 前の記事:「非常用持ち出し袋」は旅行気分で用意しよう > 個人サイト つるんとしている >ライターwiki 深遠なる中華炒めの世界 おれが以前から秘かに興味を持っている語学といえば、アラスカ先住民文字、エスペラント語、宜蘭クレオール、ゲール語、モンゴル文字など、日常生活で役に立つ場面がきわめて少ない(趣味性の高い)言葉ばかり。それらと比較すれば、10億人が話す中国語を勉強すれば圧倒的な実益が見込めるだろう。 特に「料理分野」なら、最近は日本の街中でも生身の中国語に触れる機会がそれなりにある。池袋や西川口は日本人向けにアレンジされていない中華料理屋=「ガチ中華」の街として有名だけど、いま全国的にこうした全力投球の中華料理が体験できる街が注目されつつあるからだ。 お

by Whooym 文字が適切に表示されずに読めなくなってしまう「文字化け」は、海外の技術者の間でも「Mojibake」で通用するとのこと。そんな文字化けの種類について、東京で自然言語処理(NLP)の開発をしているポール・オリーリ・マッキャン氏が解説しました。 A Field Guide to Japanese Mojibake https://www.dampfkraft.com/mojibake-field-guide.html マッキャン氏によると、文字化けは作成した時と異なる文字コードで文書を開くことで発生するとのこと。文章が文字化けすると無意味な文字列になってしまうので読めませんが、どのような文字コードが使われたかによって異なるパターンが表れるので、慣れると使われている文字コードの種類を推測することができるそうです。 ◆UTF-8 UTF-8はインターネット上では最も一般的な文字

携帯電話を用いたコミュニケーションの手法の1つに「絵文字」がある。日本で生まれたこの絵文字は、GoogleとAppleによって標準化され、今ではさまざまなスマートフォンやPCでもでも閲覧できる。 その一方、ドコモで販売されるAndroidスマートフォンには、いまだフィーチャーフォン時代の絵文字が表示される。しかしこれが今のスマートフォンにそぐわない側面が出ている。この絵文字問題について考察したい。 今の絵文字は日本のものをベースにGoogleとAppleが標準化を提案 絵文字を携帯電話に採用したのは、NTTドコモが最初だ。この後にDDI(現au)、J-フォン(現ソフトバンク)が採用する形で続く。絵文字にはシフトJISというコードが用いられていたが、互換性維持の空き領域に絵文字を割り当てたことから、キャリア間で互換性がなく、文字化けの要因となっていた。 後に自動変換サービスも展開されたが、使

j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


























