
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
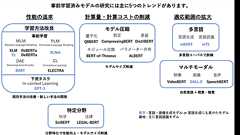
はじめまして,インターン生の三澤遼です。本記事では,BERT以降の事前学習済みモデルを体系化し,主要なモデルについて解説します。TransformerやBERTについて事前知識があると理解しやすいと思います。 BERT以降のNLP分野の発展 学習方法の改良について 事前学習 Masked Language Modeling 改良版Masked Language Modeling RoBERTa (2019-07) Translation Language Modeling XLM (2019-01) Sequence-to-Sequence Masked Language Modeling T5 (2020-07) Permuted Language Modeling XLNet (2020-01)Denoising Auto Encoder BART (2019-10) Contras

この記事についてこの記事ではGPT-3[1]の解説をします。内容のサマリは以下の通りです。GPT-3の前身であるGPT-2では、巨大なデータセット+巨大なネットワークで言語モデルを構築し、各タスクで学習させなくても良い結果が得られた。GPT-3では、さらに巨大なデータセット+さらに巨大なネットワークで言語モデルを構築し、数十のサンプルを見せると凄く良い結果が得られた一方、様々なタスクに言語モデルのスケールアップのみで対応することへの限界が見えてきた。人種、性別、宗教などへの偏見の問題や、悪用に対する課題もある。この記事の流れは以下の通りです。 Transformer, GPT-2の説明GPT-3のコンセプトと技術的な解説GPT-3ので上手くいくタスクGPT-3で上手くいかないタスク偏見や悪用への見解 Transformerまず、GPT-3の前身となったGPT-2に入る前に、その中に使われ

 1
1リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く




