
サクサク読めて、
アプリ限定の機能も多数!
アプリで開く
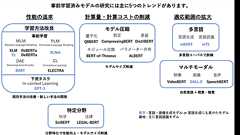
はじめまして,インターン生の三澤遼です。本記事では,BERT以降の事前学習済みモデルを体系化し,主要なモデルについて解説します。TransformerやBERTについて事前知識があると理解しやすいと思います。 BERT以降のNLP分野の発展 学習方法の改良について 事前学習 Masked Language Modeling 改良版Masked Language Modeling RoBERTa (2019-07) Translation Language Modeling XLM (2019-01) Sequence-to-Sequence Masked Language Modeling T5 (2020-07) Permuted Language Modeling XLNet (2020-01)Denoising Auto Encoder BART (2019-10) Contras

サインインした状態で「いいね」を押すと、マイページの 「いいね履歴」に一覧として保存されていくので、 再度読みたくなった時や、あとでじっくり読みたいときに便利です。

この記事についてこの記事ではGPT-3[1]の解説をします。内容のサマリは以下の通りです。GPT-3の前身であるGPT-2では、巨大なデータセット+巨大なネットワークで言語モデルを構築し、各タスクで学習させなくても良い結果が得られた。GPT-3では、さらに巨大なデータセット+さらに巨大なネットワークで言語モデルを構築し、数十のサンプルを見せると凄く良い結果が得られた一方、様々なタスクに言語モデルのスケールアップのみで対応することへの限界が見えてきた。人種、性別、宗教などへの偏見の問題や、悪用に対する課題もある。この記事の流れは以下の通りです。 Transformer, GPT-2の説明GPT-3のコンセプトと技術的な解説GPT-3ので上手くいくタスクGPT-3で上手くいかないタスク偏見や悪用への見解 Transformerまず、GPT-3の前身となったGPT-2に入る前に、その中に使われ

2018年4月20日、Deep Learning Labが主催するイベント「音声・言語ナイト」が開催されました。Chainerを提供するPreferredNetworksと、Azureクラウドを提供するMicrosoftによる、エンジニアコミュニティDeep Learning Lab。今回は、自然言語処理や合成音声など、音声・言語×深層学習(ディープラーニング)の最新事例や知見を発表しました。プレゼンテーション「深層学習時代の自然言語処理ビジネス」に登場したのは、株式会社PreferredNetworksの海野裕也氏。ディープラーニングによる自然言語処理技術の最前線と、ビジネスへの転用可能性について語りました。 自然言語処理の活かし方 海野裕也氏(以下、海野):では、お話を始めさせていただきたいと思います。PreferredNetworksの海野と申します。 今日は「自然言語処理の話

Paste (or write) a document ortext inJapanese into the box and press a Tool button: CAUTION: When you pasteJapanesetext, even though theJapanese characters change into strange characters, don't worry.Just click on a Tool button and the Results page will show the correctJapanese characters. Currently we don't supportNetscape Navigator 6.
Transcript 1. 大規模データから単語の 意味表現学習-word2vec ボレガラ ダヌシカ 博士(情報理工学) 英国リバープール大学計算機科学科准教授 2. 2 2005 2008~10 学部 修士 博士 助教/講師 東京大学 工学部 東京大学大学院情報理工学系 文書自動要約における 重要文順序学習 同姓同名抽出 別名抽出 属性類似性計測 関係類似性計測 評判分類の分野適応 関係抽出の分野適応 進化計算を用いたWeb 検索結果順序学習 ソーシャルネットワーク の関係予測 対話型協調 Web検索エンジン 潜在関係検索 エンジン 自己紹介 専門分野:自然言語処理,機械学習,データマイニング 2006~07 2010~13 2010~現在 准教授 リバープール大学 深層学習 3. 今回の講演の背景 •深層学習に関する活動 •2014年9月に深層学習のチュートリアルをCyberAge

TinySegmenterはJavascriptだけ書かれた極めてコンパクトな日本語分かち書きソフトウェアです。 わずか25kバイトのソースコードで、日本語の新聞記事であれば文字単位で95%程度の精度で分かち書きが行えます。Yahoo!の形態素解析のように サーバーサイドで解析するのではなく、全てクライアントサイドで解析を行うため、セキュリティの 観点から見ても安全です。分かち書きの単位はMeCab +ipadicと互換性があります。 デモ 日本語の文章を入力し、解析ボタンをクリックしてください。 ダウンロード TinySegmenterはフリーソフトウェアです. 修正BSDライセンスに従って本ソフトウェアを使用,再配布することができます. Download TinySegmenter version 0.2 使い方 <script type="text/javascript" src
自然言語処理を学ぶ推薦書籍を紹介します。2025年3月現在、自然言語処理を取り巻く状況が大きく変わっているため、ここに書かれている情報は極めて古く、記録のために残しておきますが、新しく自然言語処理の勉強をしようという人のための参考にはなりません。 2021年03月時点では、自然言語処理を勉強したい理工系の学生・エンジニアの人は、以下の本を推薦します。 (概要)自然言語処理(放送大学出版) (理論)言語処理のための機械学習入門+深層学習による自然言語処理 (実装)Python機械学習プログラミング 第3版 自然言語処理を勉強したい、非理工系・非エンジニアの人には、以下の本を推薦します。 (数式なし)自然言語処理の基本と技術 (数式あり)自然言語処理(放送大学出版) オライリーから出ている「入門 自然言語処理」は特殊な本(詳しい人がこれを使ってレクチャーしてくれるならともかく、独習に向いてい
海外に長い間住んでいると、日本語の活字を無性に読みたくなることが頻繁にある。青空文庫はその飢えを満たしてくれるサイトのうちのひとつだ。夏目漱石、芥川竜之介、宮沢賢治など名だたる作家の作品が収められているが、中でも太宰治の作品は私にとって特別な存在だ。 太宰治というと、「人間失格」のテーマ及び彼自身の入水自殺のインパクトがあまりにも強いためか、「暗い」「陰鬱」というイメージがあるようだ。例えば、私がまだ日本に住んでいた頃に軽い病気を患って1週間ほど入院していた時のことだ。元来読書が好きだったので、「久しぶりに集中して本を読む時間が出来た」くらいの軽い気持ちで「太宰治全集」を読んでいたら検温をしに来た看護師の方に「大丈夫ですか」と深刻な表情で訊かれたのを今でも記憶している。実際のところ、太宰は一貫して「暗い」作品を書いていたわけではなく、「お伽草紙」「富嶽百景」「走れメロス」などの明るい作品も
自然言語処理まわりのDeep Learningを自分なりにまとめてみた “自然言語処理のためのDeep Learning”というスライドを公開しました. 自然言語処理のためのDeep Learning from Yuta Kikuchi カジュアルな感じで自然言語処理まわりのDeep Learningの話題をまとめた感じになっています. きっかけは,勉強会をしていることを知ったOBのbeatinaniwaさんにお願いされたことで, 株式会社Gunosyの勉強会の場で,発表の機会を頂きました. それが,9/11で,その後9/26に研究室内で同じ内容で発表しました. どちらも思った以上に好評を頂け,公開してはと進めて頂いたので,公開することにしました. もちろん間違いが含まれている可能性も多分にあるので.気づいた方はご指摘頂けると幸いです. 内容ざっくり 前半は,ニューラルネットワークを図を使
The Natural Language Group at the USC Information Sciences Institute conducts research in natural language processing and computational linguistics, developing new linguistic and mathematicaltechniques to make bettertechnology. We have a wide range of ongoing projects, including those related to statisticalmachine translation, question answering, summarization, ontologies, information retrieval

FrontPage / Project 311 / トレンド分析 3 秒後に Project 311/Trend Analysis に移動します。 (移動しない場合は、上のリンクをクリックしてください。) © Inui Laboratory 2010-2018 All rights reserved. 研究室紹介/About Us 過去に在籍したメンバー Members 研究室環境 Lab Facilities ↑研究会/Research Meetings 概要 Overview 総合研究会 Research Seminar 意味研究会 SIG Semantics 談話研究会 SIG Discourse 知識獲得研究会 SIG Knowledge AcquisitionEmbedding研究会 SIGEmbedding KIAI Knowledge-Intensive Artifici
FrontPage / 言語処理100本ノック 3 秒後にNLP 100 Drill Exercises に移動します。 (移動しない場合は、上のリンクをクリックしてください。) © Inui Laboratory 2010-2018 All rights reserved. 研究室紹介/About Us 過去に在籍したメンバー Members 研究室環境 Lab Facilities ↑研究会/Research Meetings 概要 Overview 総合研究会 Research Seminar 意味研究会 SIG Semantics 談話研究会 SIG Discourse 知識獲得研究会 SIG Knowledge AcquisitionEmbedding研究会 SIGEmbedding KIAI Knowledge-Intensive Artificial Intellige
言語処理学会18回年次大会で音象徴の機械学習による再現:最強のポケモンの生成という面白そうなタイトルの論文があったので紹介します. 概要 「最強のポケモンの生成」というタイトルですが,ポケモン廃人的な意味ではなくて「どんな名前のポケモンが強そうに聞こえるか」という内容の研究です. いわゆる音象徴と呼ばれる分野の話で,ゴジラやキングギドラなどの怪獣の名前には濁音が多い,という話にも関係してきます. ブーバ/キキ効果 音象徴でよく使われる例としてブーバ/キキ効果と呼ばれるものがあります. 以下の画像に描かれている2つの図形に対して「どちらがブーバでどちらがキキと思うか?」とたずねます. (ファイル:BoobaKiki.png -Wikipedia, Drawn by Andrew Dunn, 1 October 2004.) すると回答者の母語によらず「曲線のほうがブーバで鋭角のほうがキキ」

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
処理を実行中です
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く








